Notes of Master Of Commerce, Research methodology Research Methodology.pdf - Study Material
Page 1 :
UNIT–1, , Introduction to Research, Methodology, , Introduction to Research, Methodology, , Notes, , (Structure), 1.1, , Learning Objectives, , 1.2, , Introduction, , 1.3, , Objectives of Research, , 1.4, , General Characteristics of Research, , 1.5, , Types of Research, , 1.6, , Stage 1: Formulating the Problem, , 1.7, , Stage 2: Method of Inquiry, , 1.8, , Stage 3: Research Method, , 1.9, , Stage 4: Research Design, , 1.10, , Stage 5: Data Collection Techniques, , 1.11, , Stage 6: Sample Design, , 1.12, , Stage 7: Data Collection, , 1.13, , Stage 8: Analysis and Interpretation, , 1.14, , Resource Planning For Your Study, , 1.15, , Importance of Defining the Problem, , 1.16, , Formulating the Problem, , 1.17, , Sources for the Problem Identification, , 1.18, , Self Questioning by the Researcher while defining the Problem, , 1.19, , Types of Research Design, , 1.20, , Exploratory Research, , 1.21, , Conclusive Research, , 1.22, , How to Prepare a Synopsis, , 1.23, , Choosing a Research Design, , 1.24, , Summary, , 1.25, , Glossary, , 1.26, , Review Questions, , 1.27, , Further Readings, Self Learning Material, , 1
Page 2 :
Research Methodology, , 1.1 Learning Objectives, After studying the chapter, students will be able to:, zz The, , Notes, , objectives of research;, , zz Different, , types of research;, , zz Meaning, , of research methodology;, , zz Qualities, , of good research;, , zz Problems, , encountered by researchers in India;, , zz Know, , the steps of a research process;, , zz Know, , understand the importance of formulating the problem and statement, of research;, , zz Know, , understand the tasks involved in problem definition;, , zz Know, , understand discuss the environmental factors affecting the definition of, the research problem;, , zz Know, , what are the different types of research design;, , zz Discuss, , what is descriptive research and what methods are adopted;, , zz Explain what is experimental research and what are the methods of conducting, , experimental research;, zz Know, , what are the types of errors that affect research design., , 1.2 Introduction, Research in common parlance refers to a search for knowledge. Once can also define, research as a scientific and systematic search for pertinent information on a specific, topic. In fact, research is an art of scientific investigation., The Advanced Learner’s Dictionary of Current English lays down the meaning, of research as “a careful investigation or inquiry specially through search for new facts, in any branch of knowledge.”, 1. Redman and Mory define research as a “systematized effort to gain new knowledge.”, 2. Some people consider research as a movement, a movement from the known, to the unknown. It is actually a voyage of discovery. We all possess the vital, instinct of inquisitiveness for, when the unknown confronts us, we wonder and, our inquisitiveness makes us probe and attain full and fuller understanding of the, unknown. This inquisitiveness is the mother of all knowledge and the method,, which man employs for obtaining the knowledge of whatever the unknown, can, be termed as research., Research is an academic activity and as such the term should be used in a technical, sense. According to Clifford Woody research comprises defining and redefining, 2, , Self Learning Material
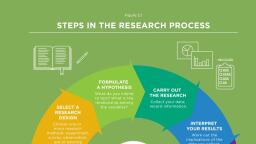
Page 3 :
problems, formulating hypothesis or suggested solutions; collecting, organising and Introduction to Research, Methodology, evaluating data; making deductions and reaching conclusions; and at last carefully, testing the conclusions to determine whether they fit the formulating hypothesis. D., Slesinger and M. Stephenson in the Encyclopaedia of Social Sciences define research, Notes, as “the manipulation of things, concepts or symbols for the purpose of generalising, to extend, correct or verify knowledge, whether that knowledge aids in construction, of theory or in the practice of an art.”, 3. Research is, thus, an original contribution to the existing stock of knowledge making, for its advancement. It is the persuit of truth with the help of study, observation,, comparison and experiment. In short, the search for knowledge through objective, and systematic method of finding solution to a problem is research. The systematic, approach concerning generalisation and the formulation of a theory is also research., As such the term ‘research’ refers to the systematic method consisting of enunciating, the problem, formulating a hypothesis, collecting the facts or data, analyzing the, facts and reaching certain conclusions either in the form of solutions(s) towards the, concerned problem or in certain generalizations for some theoretical formulation., In this unit, we will show you the steps of conducting such a research project., Figure 1.1 shows the stages in the research process. While these steps are presented in, order, you can be creative and adapt the steps to meet your business needs. Some steps, can be completed in parallel to speed the project as it begins to develop., Problem Formulation, , ⇓, , Method of Inquiry, , ⇓, , Research Method, , ⇓, , Research Design, , ⇓, , Selection of Data Collection Techniques, , ⇓, , Sample Design, , ⇓, , Data Collection, , ⇓, , Analysis and Interpretation of Data, , ⇓, , Research Reports, , Fig. 1.1: Stages in Research Process, There is a famous saying that “problem well-defined is half solved”. This statement, is strikingly true in market research, because if the problem is not stated properly, the, Self Learning Material, , 3
Page 4 :
Research Methodology objectives will not be clear. If the objectives are not clearly defined, the data collection, becomes meaningless., , Notes, , 1.3 Objectives of Research, There are various objectives of research. Some of them are listed below., The purpose of research is to discover answers to questions through the application, of scientific procedures. The main aim of research is to find out the truth which is, hidden and which has not been discovered as yet. Though each research study has its, own specific purpose, we may think of research objectives as falling into a number of, following broad groupings:, 1. To gain familiarity with a phenomenon or to achieve new insights into it (studies, with this object in view are termed as exploratory or formulative research studies);, 2. To portray accurately the characteristics of a particular individual, situation or a, group (studies with this object in view are known as descriptive research studies);, 3. To determine the frequency with which something occurs or with which it is, associated with something else (studies with this object in view are known as, diagnostic research studies);, 4. To test a hypothesis of a causal relationship between variables (such studies are, known as hypothesis-testing research studies)., , 1.4 General Characteristics of Research, The following characteristics may be gathered from the definitions of ‘Research’., 1. It gathers new knowledge or data from primary or first-hand sources., 2. It places emphasis upon the discovery of general principles., 3. It is an exact systematic and accurate investigation., 4. It uses certain valid data gathering devices., 5. It is logical and objective., 6. The researcher resists the temptation to seek only the data that support his, hypotheses., 7. The researcher eliminates personal feelings and preferences., 8. It endeavours to organise data in quantitative terms., 9. Research is patient and unhurried activity., 10. The researcher is willing to follow his procedures to the conclusions that may be, unpopular and bring social disapproval., 11. Research is carefully recorded and reported., 12. Conclusions and generalisations are arrived at carefully and cautiously., 4, , Self Learning Material
Page 5 :
1.5, , Types of Research, , There are different types of research., , Exploratory Research, Exploratory research is carried out at the very beginning when the problem is not clear, , Introduction to Research, Methodology, , Notes, , or is vague. In exploratory research, all possible reasons which are very obvious are, eliminated, thereby directing the research to proceed further with limited options. Sales, decline in a company may be due to:, 1. Inefficient service, 2. Improper price, 3. Inefficient sales force, 4. Ineffective promotion, 5. Improper quality, The research executives must examine such questions to identify the most useful, avenues for further research. Preliminary investigation of this type is called exploratory, research. Expert surveys, focus groups, case studies and observation methods are used, to conduct the exploratory survey., , Descriptive Research, The main purpose of descriptive research is to describe the state of view as it exists at, present. Simply stated, it is a fact finding investigation. In descriptive research, definite, conclusions can be arrived at, but it does not establish a cause and effect relationship., This type of research tries to describe the characteristics of the respondent in relation, to a particular product., Descriptive research deals with demographic characteristics of the consumer., For example, trends in the consumption of soft drink with respect to socio-economic, characteristics such as age, family, income, education level, etc. Another example can, be the degree of viewing TV channels, its variation with age, income level, profession, of respondent as well as time of viewing. Hence, the degree of use of TV to different, types of respondents will be of importance to the researcher. There are three types of, players who will decide the usage of TV: (a) Television manufacturers, (b) Broadcasting, agency of the programme, (c) Viewers. Therefore, research pertaining to any one of the, following can be conducted:, zz The, , manufacturer can come out with facilities which will make the television, more user-friendly. Some of the facilities are (a) Remote control, (b) Child lock,, (c) Different models for different income groups, (d) Internet compatibility etc.,, (e) Wall mounting etc., Self Learning Material, , 5
Page 6 :
Research Methodology, , zz Similarly,, , broadcasting agencies can come out with programmes, which can, suit different age groups and income., , zz Ultimately,, , the viewers who use the TV must be aware of the programmes, appearing in different channels and can plan their viewing schedule, accordingly., , Notes, , zz Descriptive, , research deals with specific predictions, for example, sales of a, company’s product during the next three years, i.e., forecasting., , zz Descriptive, , research is also used to estimate the proportion of population, who behave in a certain way. Example: “Why do middle income groups go to, FoodWorld to buy their products?”, , zz A, , study can be commissioned by a manufacturing company to find out, various facilities that can be provided in television sets based on the above, discussion., , zz Similarly,, , studies can be conducted by broadcasting stations to find out the, degree of utility of TV programmes. Example: The following hypothesis may, be formulated about the programmes:, , zz The, , programmes in various channels are useful by way of entertainment to, the viewers., , zz Viewers feel that TV is a boon for their children in improving their knowledge—, , especially, fiction and cartoon programmes., , Applied Research, Applied research aims at finding a solution for an immediate problem faced by any, business organization. This research deals with real life situations. Example: “Why, have sales decreased during the last quarter”? Market research is an example of applied, research. Applied research has a practical problem-solving emphasis. It brings out many, new facts., Examples:, 1. Use of fibre glass body for cars instead of metal., 2. To develop a new market for the product., , Pure/Fundamental Research or Basic Research, Gathering knowledge for knowledge’s sake is known as basic research. It is not directly, involved with practical problems. It does not have any commercial potential. There is, no intention to apply this research in practice. Tata Institute of Fundamental Research, conducts such studies. Example: Theory of Relativity (by Einstein)., , Conceptual Research, This is generally used by philosophers. It is related to some abstract idea or theory. In, this type of research, the researcher should collect the data to prove or disapprove his, hypothesis. The various ideologies or ‘isms’ are examples of conceptual research., 6, , Self Learning Material
Page 7 :
Causal Research, Causal research is conducted to determine the cause and effect relationship between the, , Introduction to Research, Methodology, , two variables. Example: Effect of advertisement on sales., , Historical Research, , Notes, , The name itself indicates the meaning of the research. Historical study is a study of, past records and data in order to understand the future trends and development of the, organisation or market. There is no direct observation. The research has to depend on, the conclusions or inferences drawn in the past., For example, investors in the share market study the past records or prices of shares, which he/she intends to buy. Studying the share prices of a particular company enables, the investor to take decision whether to invest in the shares of a company. Crime branch, police/CBI officers study the past records or the history of the criminals and terrorists, in order to arrive at some conclusions. The main objective of this study is to derive, explanation and generalization from the past trends in order to understand the present, and anticipate the future., There are however, certain shortcomings of Historical Research:, 1. Reliability and adequacy information is subjective and open to question, 2. Accuracy of measurement of events is doubtful., 3. Verification of records are difficult., , Ex-post Facto Research, In this type of research, an examination of relationship that exists between independent, and dependent variable is studied. We may call this empirical research. In this method,, the researcher has no control over an independent variable. Ex-post facto literally means, “from what is done afterwards”. In this research, a variable “A” is observed. Thereafter,, the researcher tries to find a causal variable “B” which caused “A”. It is quite possible, that “B” might not have been caused “A”. In this type of analysis, there is no scope, for the researcher to manipulate the variable. The researcher can only report “what has, happened” and “what is happening”., , Action Research, This type of research is undertaken by direct action. Action research is conducted to, solve a problem. Example: Test marketing a product is an example of action research., Initially, the geographical location is identified. A target sample is selected from among, the population. Samples are distributed to selected samples and feedback is obtained, from the respondent. This method is most common for industrial products, where a trial, is a must before regular usage of the product., Self Learning Material, , 7
Page 8 :
Research Methodology Evaluation Research, , Notes, , Evaluation research is an example of applied research. This research is conducted to, find out how well a planned programme is implemented. Therefore, evaluation research, deals with evaluating the performance or assessment of a project. Example: “Rural, Employment Programme Evaluation” or “Success of Midday Meal Programme”., , Library Research, Library research is done to gather secondary data. This includes notes from the past, data or review of the reports already conducted. This is a convenient method whereby, both manpower and time are saved., , Research Methods versus Methodology, It seems appropriate at this juncture to explain the difference between research methods, and research methodology. Research methods may be understood as all those methods/, techniques that are used for conduction of research. Research methods or techniques*,, thus, refer to the methods the researchers use in performing research operations. In, other words, all those methods which are used by the researcher during the course of, studying his research problem are termed research methods. Since the object of research,, particularly the applied research, is to arrive at a solution for a given problem, the, available data and the unknown aspects of the problem have to be related to each other, to make a solution possible. Keeping this in view, research methods can be put into the, following three groups:, 1. In the first group, we include those methods which are concerned with the collection, of data. These methods will be used where the data already available are not, sufficient to arrive at the required solution;, 2. The second group consists of those statistical techniques which are used for, establishing relationships between the data and the unknowns;, 3. The third group consists of those methods which are used to evaluate the accuracy, of the results obtained., Research methods falling in the above stated last two groups are generally taken, as the analytical tools of research., Research methodology is a way to systematically solve the research problem. It, may be understood as a science of studying how research is done scientifically. In it we, study the various steps that are generally adopted by a researcher in studying his research, problem along with the logic behind them. It is necessary for the researcher to know, not only the research methods/techniques but also the methodology. Researchers not, only need to know how to develop certain indices or tests, how to calculate the mean,, the mode, the median or the standard deviation or chi-square, how to apply particular, research techniques, but they also need to know which of these methods or techniques, are, 8, , Self Learning Material
Page 9 :
relevant and which are not, and what would they mean and indicate and why. Researchers Introduction to Research, Methodology, also need to understand the assumptions underlying various techniques and they need to, know the criteria by which they can decide that certain techniques and procedures will, be applicable to certain problems and others will not. All this means that it is necessary, Notes, for the researcher to design his methodology for his problem as the same may differ, from problem to problem. For example, an architect, who designs a building, has to, consciously evaluate the basis of his decisions, i.e., he has to evaluate why and on what, basis he selects particular size, number and location of doors, windows and ventilators,, uses particular materials and not others and the like. Similarly, in research the scientist, has to expose the research decisions to evaluation before they are implemented. He, has to specify very clearly and precisely what decisions he selects and why he selects, them so that they can be evaluated by others also. From what has been stated above,, we can say that research methodology has many dimensions and research methods do, constitute a part of the research methodology. The scope of research methodology is, wider than that of research methods. Thus, when we talk of research methodology we, not only talk of the research methods but also consider the logic behind the methods, we use in the context of our research study and explain why we are using a particular, method or technique and why we are not using others so that research results are capable, of being evaluated either by the researcher himself or by others. Why a research study, has been undertaken, how the research problem has been defined, in what way and why, the hypothesis has been formulated, what data have been collected and what particular, method has been adopted, why particular technique of analysing data has been used, and a host of similar other questions are usually answered when we talk of research, methodology concerning a research problem or study., , Criteria of Good Research, Whatever may be the types of research works and studies, one thing that is important is, that they all meet on the common ground of scientific method employed by them. One, expects scientific research to satisfy the following criteria:, 1. The purpose of the research should be clearly defined and common concepts be used., 2. The research procedure used should be described in sufficient detail to permit, another researcher to repeat the research for further advancement, keeping the, continuity of what has already been attained., 3. The procedural design of the research should be carefully planned to yield results, that are as objective as possible., 4. The researcher should report with complete frankness, flaws in procedural design, and estimate their effects upon the findings., 5. The analysis of data should be sufficiently adequate to reveal its significance and, the methods of analysis used should be appropriate. The validity and reliability of, the data should be checked carefully., Self Learning Material, , 9
Page 10 :
Research Methodology, , Notes, , 6. Conclusions should be confined to those justified by the data of the research and, limited to those for which the data provide an adequate basis., 7. Greater confidence in research is warranted if the researcher is experienced, has a, good reputation in research and is a person of integrity., In other words, we can state the qualities of a good research as under:, 1. Good research is systematic: It means that research is structured with specified steps, to be taken in a specified sequence in accordance with the well-defined set of rules., Systematic characteristic of the research does not rule out creative thinking but it, certainly does reject the use of guessing and intuition in arriving at conclusions., 2. Good research is logical: This implies that research is guided by the rules of logical, reasoning and the logical process of induction and deduction are of great value in, carrying out research. Induction is the process of reasoning from a part to the whole, whereas deduction is the process of reasoning from some premise to a conclusion, which follows from that very premise. In fact, logical reasoning makes research, more meaningful in the context of decision making., 3. Good research is empirical: It implies that research is related basically to one or, more aspects of a real situation and deals with concrete data that provide a basis, for external validity to research results., 4. Good research is replicable: This characteristic allows research results to be verified, by replicating the study and thereby building a sound basis for decisions., , Problems Encountered by Researchers in India, Researchers in India, particularly those engaged in empirical research, are facing several, problems. Some of the important problems are as follows:, 1. The lack of scientific training in the methodology of research is a great impediment, for researchers in our country. There is paucity of competent researchers. Many, researchers take a leap in the dark without knowing research methods. Most of the, work, which goes in the name of research is not methodologically sound. Research, to many researchers and even to their guides, is mostly a scissor and paste job, without any insight shed on the collated materials. The consequence is obvious,, viz., the research results, quite often, do not reflect the reality or realities. Thus, a, systematic study of research methodology is an urgent necessity. Before undertaking, research projects, researchers should be well equipped with all the methodological, aspects. As such, efforts should be made to provide short duration intensive courses, for meeting this requirement., 2. There is insufficient interaction between the university research departments, on one side and business establishments, government departments and research, institutions on the other side. A great deal of primary data of non-confidential, 10, , Self Learning Material
Page 11 :
nature remain untouched/untreated by the researchers for want of proper contacts. Introduction to Research, Methodology, Efforts should be made to develop satisfactory liaison among all concerned for, better and realistic researches. There is need for developing some mechanisms, of a university—industry interaction programme so that academics can get ideas, Notes, from practitioners on what needs to be researched and practitioners can apply the, research done by the academics., 3. Most of the business units in our country do not have the confidence that the, material supplied by them to researchers will not be misused and as such they are, often reluctant in supplying the needed information to researchers. The concept of, secrecy seems to be sacrosanct to business organizations in the country so much, so that it proves an impermeable barrier to researchers. Thus, there is the need for, generating the confidence that the information/data obtained from a business unit, will not be misused., 4. Research studies overlapping one another are undertaken quite often for want of, adequate information. This results in duplication and fritters away resources. This, problem can be solved by proper compilation and revision, at regular intervals,, of a list of subjects on which and the places where the research is going on. Due, attention should be given toward identification of research problems in various, disciplines of applied science which are of immediate concern to the industries., 5. There does not exist a code of conduct for researchers and inter-university and, interdepartmental rivalries are also quite common. Hence, there is need for, developing a code of conduct for researchers which, if adhered sincerely, can win, over this problem., 6. Many researchers in our country also face the difficulty of adequate and timely, secretarial assistance, including computerial assistance. This causes unnecessary, delays in the completion of research studies. All possible efforts be made in this, direction so that efficient secretarial assistance is made available to researchers and, that too well in time. University Grants Commission must play a dynamic role in, solving this difficulty., 7. Library management and functioning is not satisfactory at many places and much, of the time energy of researchers is spent in tracing out the books, journals, reports,, etc., rather than in tracing out relevant material from them., 8. There is also the problem that many of our libraries are not able to get copies of, old and new Acts/Rules, reports and other government publications in time. This, problem is felt more in libraries which are away in places from Delhi and/or the, state capitals. Thus, efforts should be made for the regular and speedy supply of, all governmental publications to reach our libraries., Self Learning Material 11
Page 12 :
Research Methodology, , 9. There is also the difficulty of timely availability of published data from various, government and other agencies doing this job in our country. Researcher also faces, the problem on account of the fact that the published data vary quite significantly, because of differences in coverage by the concerning agencies., , Notes, , 10. There may, at times, take place the problem of conceptualization and also problems, relating to the process of data collection and related things., , 1.6, , Stage 1: Formulating the Problem, , ‘Formulating a problem’ is the first step in the research process. In many ways, research, starts with a problem that management is facing. This problem needs to be understood,, the cause diagnosed, and solutions developed. However, most management problems, are not always easy to research. A management problem must first be translated into a, research problem. Once you approach the problem from a research angle, you can find, a solution. For example, “sales are not growing” is a management problem. Translated, into a research problem, we may examine the expectations and experiences of several, groups: potential customers, first-time buyers, and repeat purchasers. We will determine, if the lack of sales is due to (1) poor expectations that lead to a general lack of desire to, buy, or (2) poor performance experience and a lack of desire to repurchase., What then is the difference between a management problem and a research problem?, Management problems focus on an action. Do we advertise more? Do we change our, advertising message? Do we change an under-performing product configuration? If so,, how? Research problems, on the other hand, focus on providing the information you, need in order to solve the management problem., Once you’ve created a research problem, you have to develop a research question. A, research question gives you research direction. From the research question, a hypothesis, or hypotheses can be formulated to guide the research. A hypothesis should include, a statement about the relationship between two or more variables and carry clear, implications for testing the stated relationship. For example, you might need to know, if and how your customers’ positive and negative product expectations are confirmed, or disconfirmed upon product use., , How to Formulate the Research Problem, Problem formulation is simplified once we define the components of the research problem., 1. Specify the Research Objectives: A clear statement of objectives will help you, develop effective research. It will help the decision makers evaluate your project., It is critical that you have manageable objectives. Thus, two or three clear goals, will help to keep your research project focused and relevant., 2. Review the Environment or Context of the Problem: As a marketing researcher,, you must work closely with your team. This will help you determine whether the, 12, , Self Learning Material
Page 13 :
findings of your project will produce enough information to be worth the cost. In Introduction to Research, Methodology, order to do this, you have to identify the environmental variables that will affect, the research project. These variables will be discussed in-depth in later units., 3. Explore the Nature of the Problem: Research problems range from simple to, complex, depending on the number of variables and the nature of their relationship., If you understand the nature of the problem as a researcher, you will be able to, better develop a solution for the problem. To help you understand all dimensions,, you might want to consider focus groups of consumers, sales people, managers,, or professionals to provide what is sometimes much needed insight., , Notes, , 4. Define the Variable Relationships: Marketing plans often focus on creating a, sequence of behaviours that occur over time, as in the adoption of a new package, design, or the introduction of a new product. Such programmes create a commitment, to follow some behavioural pattern in the future. Studying such a process involves:, (i), , Determining which variables affect the solution to the problem., , (ii), , Determining the degree to which each variable can be controlled., , (iii), , Determining the functional relationships between the variables and which, variables are critical to the solution of the problem., , During the problem formulation stage, you will want to generate and consider as, many courses of action and variable relationships as possible., 5. The Consequences of Alternative Courses of Action: There are always consequences, to any course of action. Anticipating and communicating the possible outcomes of, various courses of action is a primary responsibility in the research process., , Basic Research Issues, As technology advances, marketing researchers continually look for ways to adapt new, technology to the practice of research. However, researchers must never forget that, research basics cannot be overlooked. Rather, what must be done is to adapt the new, techniques and technologies to these basics. All studies must address the following basic, issues (Anderson, Berdie, & Liestman, 1984):, 1. Ask the right questions: This is the essence of project design and the heart of proper, planning. Every project is unique, and as such must be tailored to the user’s needs., 2. Ask the right people: The goal of sample design should be that only those people, who are of interest to the researcher are contacted, and that those contacted are, representative of the group of interest, 3. Ask questions the right way: It is not enough to be able to ask the right questions;, they must be asked the right way. This is the essence of questionnaire design. If the, wording of the questions is not clear to the respondents, the results will be useless., Pre-testing the questionnaire is crucial for ensuring that responses are the ones that, are needed., Self Learning Material 13
Page 14 :
4. Obtain answers to questions: Data collection is central to all marketing research., The techniques used should minimize on-response while maximizing response., , Research Methodology, , Case “Let New Coke” Versus Original Coke, , Notes, , In the mid-1980s, the Coca Cola Company made a decision to introduce a new beverage, product (Hartley, 1995, pp. 129–145). The company had evidence that taste was the, single most important cause of Coke’s decline in the market share in the late 1970s and, early 1980s. A new product dubbed “New Coke” was developed that was sweeter than, the original-formula Coke., Almost 200,000 blind product taste tests were conducted in the United States, and, more than one-half of the participants favored New Coke over both the original formula, and Pepsi. The new product was introduced and the original formula was withdrawn from, the market. This turned out to be a big mistake! Eventually, the company reintroduced, the original formula as Coke Classic and tried to market the two products. Ultimately,, New Coke was withdrawn from the market., What went wrong? Two things stand out. First, there was a flaw in the market research, taste tests that were conducted: They assumed that taste was the deciding factor in, consumer purchase behaviour. Consumers were not told that only one product would be, marketed. Thus, they were not asked whether they would give up the original formula, for New Coke. Second, no one realized the symbolic value and emotional involvement, people had with the original Coke. The bottom line on this is that relevant variables that, would affect the problem solution were not included in the research., , Relate Answers to the Needs of the Research User/Client, Data seldom speaks for itself. Proper data analysis is needed if a study is to have any, value to the user. Here there is a risk of letting advanced techniques become the master, of the researcher rather than the opposite. Common sense is a valuable tool for the, researcher when considering alternative analysis approaches for any project., , Communicate Effectively and in a Way that the Client Understands, Many good projects are ruined because the information that is reported to the user is in a, form that is not understandable. Reports must tell the user what information is relevant,, and how it is relevant to the issues at hand., , 1.7, , Stage 2: Method of Inquiry, , The scientific method is the standard pattern for investigation. It provides an opportunity, for you to use existing knowledge as a starting point and proceed impartially. The, scientific method includes the following steps:, 1. Formulate a problem, 2. Develop a hypothesis, 14, , Self Learning Material
Page 15 :
3. Make predictions based on the hypothesis, 4. Devise a test of the hypothesis, , Introduction to Research, Methodology, , 5. Conduct the test, 6. Analyze the results, , Notes, , The terminology is similar to the stages in the research process. However, there, are subtle differences in the way the steps are performed. For example, the scientific, method is objective while the research process can be subjective. Objective-based, research (quantitative research) relies on impartial analysis. The facts are the priority in, objective research. On the other hand, subjective-based research (qualitative research), emphasizes personal judgement as you collect and analyze data., , The Scientific Method, In structure, if not always in application, the scientific method is simple and consists, of the following steps:, 1. Observation: This is the problem-awareness phase, which involves observing a set, of significant factors that relate to the problem situation., 2. Formulation of Hypotheses: In this stage, a hypothesis (i.e., a generalization about, reality that permits prediction) is formed that postulates a connection between, seemingly unrelated facts. In a sense, the hypothesis suggests an explanation of, what has been observed., 3. Prediction of the Future: After hypotheses are formulated, their logical implications, are deduced. This stage uses the hypotheses to predict what will happen., 4. Testing the Hypotheses: This is the evidence collection and evaluation stage. From, a research project perspective this is the design and implementation of the main, study. Conclusions are stated based on the data collected and evaluated., A simple example will show how the scientific method works. Assume a researcher is, performing a marketing research project for a manufacturer of men’s shirts:, 1. Observation: The researcher notices some competitors’ sales are increasing and, that many competitors have shifted to a new plastic wrapping., 2. Formulation of Hypotheses: The researcher assumes his client’s products are, of similar quality and that the plastic wrapping is the sole cause of increased, competitors’ sales., 3. Prediction of the Future: The hypothesis predicts that sales will increase if the, manufacturer shifts to the new wrapping., 4. Testing the Hypotheses: The client produces some shirts in the new packaging and, market-tests them., Self Learning Material 15
Page 16 :
Research Methodology, , 1.8, , Stage 3: Research Method, , In addition to selecting a method of inquiry (objective or subjective), you must select, a research method., , Notes, , There are two primary methodologies that can be used to answer any research, question: experimental research and non-experimental research. Experimental research, gives you the advantage of controlling extraneous variables and manipulating one or, more variables that influence the process being implemented. Non-experimental research, allows observation but not intervention. You simply observe and report on your findings., , 1.9, , Stage 4: Research Design, , The datadays research design is a plan or framework for conducting the study and, collecting data. It is defined as the specific methods and procedures you use to acquire, the information you need., , 1.10, , Stage 5: Data Collection Techniques, , Your research design will develop as you select techniques to use. There are many ways, to collect data. Interviews require you to ask questions and receive responses. Common, modes of research communication include interviews conducted face-to-face, by mail, by, telephone, by e-mail, or over the Internet. This broad category of research techniques is, known as survey research. These techniques are used in both non-experimental research, and experimental research., Another way to collect data is by observation. Observing a person’s or company’s, past or present behaviour can predict future purchasing decisions. Data collection, techniques for past behaviour can include analyzing company records and reviewing, studies published by external sources., In order to analyze information from interview or observation techniques, you, must record your results. Because the recorded results are vital, measurement and, development are closely linked to which data collection techniques you decide on. The, way you record the data changes depends on which method you use., , 1.11, , Stage 6: Sample Design, , Your marketing research project will rarely examine an entire population. It’s more, practical to use a sample—a smaller but accurate representation of the greater population., In order to design your sample, you must find answers to these questions:, 1. From which base population is the sample to be selected?, 2. What is the method (process) for sample selection?, 3. What is the size of the sample?, 16, , Self Learning Material
Page 17 :
Once you’ve established who the relevant population is (completed in the problem Introduction to Research, Methodology, formulation stage), you have a base for your sample. This will allow you to make, inferences about a larger population. There are two methods of selecting a sample from, a population: probability or non-probability sampling. The probability method relies on, Notes, a random sampling of everyone within the larger population. Non-probability is based, on part on the judgement of the investigator, and often employs convenience samples,, or by other sampling methods that do not rely on probability., The final stage of the sample design involves determining the appropriate sample, size. This important step involves cost and accuracy decisions. Larger samples generally, reduce sampling error and increase accuracy, but also increase costs., , 1.12 Stage 7: Data Collection, Once you’ve established the first six stages, you can move on to data collection. Depending, on the mode of data collection, this part of the process can require large amounts of, personnel and a significant portion of your budget. Personal (face-to-face) and telephonic, interviews may require you to use a data days rather than weeks or months., Regardless of the mode of data collection, the data collection process introduces, another essential element to your research project: the importance of clear and constant, communication., , 1.13 Stage 8: Analysis and Interpretation, In order for data to be useful, you must analyze it. Analysis techniques vary and their, effectiveness depends on the types of information you are collecting, and the type of, measurements you are using. Because they are dependent on the data collection, analysis, techniques should be decided before this step., , Stage 9: The Research Report, The research process culminates with the research report. This report will include all, of your information, including an accurate description of your research process, the, results, conclusions, and recommended courses of action. The report should provide all, the information the decision maker needs to understand the project. It should also be, written in language that is easy to understand. It’s important to find a balance between, completeness and conciseness. You don’t want to leave any information out; however,, you can’t let the information get so technical that it overwhelms the reading audience., One approach to resolving this conflict is to prepare two reports: the technical report, and the summary report. The technical report discusses the methods and the underlying, assumptions. In this document, you discuss the detailed findings of the research project., The summary report, as its name implies summarizes the research process and presents, the findings and conclusions as simply as possible., Self Learning Material 17
Page 18 :
Research Methodology, , Notes, , Another way to keep your findings clear is to prepare several different representations, of your findings. PowerPoint presentations, graphs, and face-to-face reports are all, common methods for presenting your information. Along with the written report for, reference, these alternative presentations will allow the decision maker to understand, all aspects of the project., , 1.14, , Resource Planning For Your Study, , As you are developing your study, you have to account for the expenditure of your, resources: personnel, time, and money. Resource plans need to be worked out with the, decision maker and will range from very formal budgeting and approval processes to, a very informal “Go ahead and do it”. Before you can start the research project, you, should get yourself organized and prepare a budget and time schedule for the major, activities in the study. Microsoft Project and similar programmes are good resources, for breaking down your tasks and resources., , 1.15, , Importance of Defining the Problem, , Problem definition involves stating the general problem and identifying the specific, components of the research problem. Only when the marketing research problem has, been clearly defined can research be designed and conducted properly. Of all the tasks, in a research, none is more vital to the ultimate fulfilment of a client’s needs than a, proper definition of the research problem. All the effort, time, and money spent from, this point will be wasted if the problem is misunderstood or ill defined. This point is, worth remembering because inadequate problem definition is a leading cause of failure, of research projects., , 1.16, , Formulating the Problem, , The first step in research is to formulate the problem. A company manufacturing television, sets might think that it is losing sales to a foreign company. A brief illustration aptly, demonstrates how such problem can be ill conceived. The management of a company, felt, a drop in sales was because of the poor quality of product. Subsequently, research, was undertaken with a view to improving the quality of the product. However, despite, an improvement in quality, sales did not pick up. In this case, we may say that the, problem is ill defined. The actual reason was ineffective sales promotion. The problem, thus needs to be carefully identified., Marketing problem, which needs research, can be classified into two categories:, 1. Difficulty related problems, 2. Opportunity related problems, while the first category produces negative results, such as, decline in market share or sales, the second category provides benefits., 18, , Self Learning Material
Page 19 :
Either problem definition might refer to a real-life situation or it may also refer to Introduction to Research, Methodology, a set of opportunities. Market research problems or opportunities will arise under the, following circumstances–, 1. Unanticipated change, 2. Planned change., , Notes, , Many factors in the environment can create problems or opportunities. Thus, changes, in the demographics, technological and legal changes affect the marketing function. Now, the question is how the company responds to new technology, or product introduced by, the competitor or how to cope with the changes in lifestyles. It may be a problem and at, the same time, it can also be viewed as an opportunity. In order to conduct research,the, problem must be defined accurately., While formulating the problem, clearly define:, 1. Who is the focus?, 2. What is the subject-matter of research?, 3. To which geographical territory/area the problem refers to?, 4. To which period does the study pertains to?, Example: “Why does the upper-middle class of Bangalore shop at Lifestyle during, the Diwali season”? Here all the above four aspects are covered. We may be interested, in a number of variables due to which shopping is done at a particular place. The, characteristic of interest to the researcher may be:, 1. Variety offered at Lifestyle, 2. Discount offered by way of promotion, 3. Ambience at the Lifestyle and the, 4. Personalised service offered., In some cases, the cause of the problem is obvious whereas in others the cause, is not so obvious. The obvious causes are the products being on the decline. Not so, obvious causes could be a bad first experience for the customer., , 1.17 Sources for the Problem Identification, Research students can adopt the following ways to identify the problems:, zz Research, , reports already published may be referred to define a specific, , problem., zz Assistance, , of any research organisation, which handles a number of projects, of the companies, can be sought to identify the problem., , zz Professors working in reputed academic institution can act as guides in problem, , identification., Self Learning Material 19
Page 20 :
Research Methodology, , zz Company, , employees and competitors can assist in identifying the, , problems., zz Cultural, , and technological changes can act as a source for research problem, identification., , Notes, , zz Seminars/symposiums/focus, , 1.18, , groups can act as a useful source., , � elf Questioning by the Researcher while defining the, S, Problem, , 1. Is the research problem correctly defined?, 2. Is the research problem solvable?, 3. Can relevant data be gathered through the process of marketing research?, 4. Is the research problem significant?, 5. Can the research be conducted within the available resources?, 6. Is the time given to complete the project sufficient?, 7. What exactly will be the difficulties in conducting the study, and hurdles to be, overcome?, 8. Am I competent, to carry the study out?, Managers often want the results of research in accordance with their expectation., This satisfies them immensely. If one were to closely look at the questionnaire, it is found, that in most cases, there are stereotyped answers given by the respondents. A researcher, must be creative and should look at problems in a different perspective. What does the, researcher understand from the above?, , 1.19, , Types of Research Design, , Exploratory, descriptive and causal research is some of the major types. Exploratory, research is used to seek insights into general nature of the problem. It provides the, relevant variable that needs to be considered. In this type of research, there is no previous, knowledge; research methods are flexible, qualitative and unstructured. The researcher, in this method does not know “what he will find”., Descriptive research is a type of research, very widely used in marketing research., Generally in descriptive study there will be a hypothesis, with respect to this hypothesis,, we ask questions such as size, distribution, etc. Causal research, this type of research, is concerned with finding cause and effect relationship. Normally, experiments are, conducted in this type of research., , 1.20, , Exploratory Research, , The major emphasis in exploratory research is on converting broad, vague problem, statements into small, precise sub-problem statements, which is done in order to, 20, , Self Learning Material
Page 21 :
formulate specific hypothesis. The hypothesis is a statement that specifies, “how two Introduction to Research, Methodology, or more variables are related?”, In the early stages of research, we usually lack sufficient understanding of the, problem to formulate a specific hypothesis. Further, there are often several tentative, explanations. For Example “Sales are down because our prices are too high”, “our, dealers or sales representatives are not doing a good job”, “our advertisement is weak”, and so on. In this scenario, very little information is available to point out, what is the, actual cause of the problem. We can say that the major purpose of exploratory research, is to identify the problem more specifically. Therefore, exploratory study is used in the, initial stages of research., , Notes, , Under What Circumstances is Exploratory Study Ideal?, The following are the circumstances in which exploratory study would be ideally suited:, zz To, , gain an insight into the problem, , zz To, , generate new product ideas, , zz To, , list all possibilities. Among the several possibilities, we need to prioritize, the possibilities which seem likely to occur, , zz To, , develop hypothesis occasionally, , zz Exploratory, , study is also used to increase the analyst’s familiarity with the, problem. This is particularly true, when the analyst is new to the problem, area. For example, a market researcher working for (new entrant) a company, for the first time., , zz To, , establish priorities so that further research can be conducted., , zz Exploratory, , studies may be used to clarify concepts and help in formulating, precise problems. For example, the management is considering a change in the, contract policy, which it hopes, will result in improved satisfaction for channel, members. An exploratory study can be used to clarify the present state of channel, members’ satisfaction and to develop a method by which satisfaction level of, channel members is measured., , zz To, , pre-test a draft questionnaire., , zz In general, exploratory research is appropriate to any problem about which very, , little is known. This research is the foundation for any future study., , Hypothesis Development at Exploratory Research Stage Research Design, At Exploratory Stage:, 1. Sometimes, it may not be possible to develop any hypothesis at all, if the situation, is being investigated for the first time. This is because no previous data is available., 2. Sometimes, some information may be available and it may be possible to formulate, a tentative hypothesis., Self Learning Material 21
Page 22 :
Research Methodology, , 3. In other cases, most of the data is available and it may be possible to provide, answers to the problem., The examples given below indicate each of the above type:, , Notes, , Research purpose, 1. �What product feature,, if stated, will be, most effective in the, advertisement?, 2. �What new packaging is, to be developed by the, company with respect to, a soft drink., 3. �How can our insurance, service be improved?, , Research question, Hypothesis, What benefit do people, No hypothesis, derive from this Ad appeal? formulation is possible, , What alternatives exist to, provide a container for soft, drink?, , Paper cup is better than, any other forms, such as, a bottle., , What is the nature of, customer dissatisfaction?, , Impersonalization is the, problem., , In example 1: The research question is posed to determine “What benefit do people, seek from the Ad?” Since no previous research is done on consumer benefit for this, product, it is not possible to form any hypothesis., In example 2: Some information is currently available about packaging for a, soft drink. Here it is possible to formulate a hypothesis which is purely tentative. The, hypothesis formulated here may be only one of the several alternatives available., In example 3: The root cause of customer dissatisfaction is known, i.e., lack of, personalised service. In this case, it is possible to verify whether this is a cause or not., , Characteristics of Exploratory Research, 1. Exploratory research is flexible and very versatile., 2. For data collection structured forms are not used., 3. Experimentation is not a requirement., 4. Cost incurred to conduct study is low., 5. This type of research allows very wide exploration of views., 6. Research is interactive in nature and also it is open ended., , Exploratory Research Methods, The quickest and the cheapest way to formulate a hypothesis in exploratory research is, by using any of the four methods:, 1. Literature search, 2. Experience survey, 3. Focus group, 4. Analysis of selected cases, 22, , Self Learning Material
Page 23 :
Literature Search, This refers to “referring to a literature to develop a new hypothesis”. The literature, referred are—trade journals, professional journals, market research finding publications,, statistical publications, etc. Example: Suppose a problem is “Why are sales down?” This, can quickly be analysed with the help of published data which should indicate “whether, the problem is an “industry problem” or a “firm problem”. Three possibilities exist to, formulate the hypothesis., , Introduction to Research, Methodology, , Notes, , 1. The company’s market share has declined but industry’s figures are normal., 2. The industry is declining and hence the company’s market share is also declining., 3. The industry’s share is going up but the company’s share is declining., If we accept the situation that our company’s sales are down despite the market, showing an upward trend, we need to analyse the marketing mix variables., Example 1: A TV manufacturing company feels that its market share is declining, whereas the overall television industry is doing very well., Example 2: Due to a trade embargo imposed by a country, textiles exports are, down and hence sales of a company making garment for exports is on the decline., The above information may be used to pinpoint the reason for declining sales., , Experience Survey, In experience surveys, it is desirable to talk to persons who are well informed in the area, being investigated. These people may be company executives or persons outside the, organisation. Here, no questionnaire is required. The approach adopted in an experience, survey should be highly unstructured, so that the respondent can give divergent views., Since the idea of using experience survey is to undertake problem formulation, and not, conclusion, probability sample need not be used. Those who cannot speak freely should, be excluded from the sample., , Example 1, 1. A group of housewives may be approached for their choice for a “ready to cook, product”., 2. A publisher might want to find out the reason for poor circulation of newspaper, introduced recently. He might meet (a) Newspaper sellers (b) Public reading room, (c) General public (d) Business community, etc. These are experienced persons, whose knowledge researcher can use., , Focus Group, Another widely used technique in exploratory research is the focus group. In a focus, group, a small number of individuals are brought together to study and talk about some, topic of interest. The discussion is co-ordinated by a moderator. The group usually is of, Self Learning Material 23
Page 24 :
Research Methodology 8–12 persons. While selecting these persons, care has to be taken to see that they should, have a common background and have similar experiences in buying. This is required, because there should not be a conflict among the group members on the common issues, that are being discussed. During the discussion, future buying attitudes, present buying, Notes, opinions etc., are gathered., Most of the companies conducting the focus groups first screen the candidates to, determine who will compose the particular group. Firms also take care to avoid groups,, in which some of the participants have their friends and relatives, because this leads to, a biased discussion. Normally, a number of such groups are constituted and the final, conclusion of various groups is taken for formulating the hypothesis. Therefore, a key, factor in focus group is to have similar groups. Normally, there are 4–5 groups. Some of, them may even have 6-8 groups. The guiding criterion is to see whether the latter groups, are generating additional ideas or repeating the same with respect to the subject under, study. When this shows a diminishing return from the group, the discussions stopped., The typical focus group lasts for 1–30 hours to 2 hours. The moderator under the focus, group has a key role. His job is to guide the group to proceed in the right direction., The following should be the characteristics of a moderator/facilitator:, zz Listening:, , He must have a good listening ability. The moderator must not miss, the participant’s comment, due to lack of attention., , zz Permissive:, , The moderator must be permissive, yet alert to the signs that the, group is disintegrating., , zz Memory:, , He must have a good memory. The moderator must be able to, remember the comments of the participants. Example: A discussion is centered, on a new advertisement by a telecom company. The participant may make a, statement early and make another statement later, which is opposite to what was, said earlier. For example, the participant may say that s(he) never subscribed to, the views expressed in the advertisement by the competitor, but subsequently, may say that the “current advertisement of competitor is excellent”., , zz Encouragement:, , The moderator must encourage unresponsive members to, , participate., zz Learning:, , He should be a quick learner., , zz Sensitivity:, , The moderator must be sensitive enough to guide the group, , discussion., zz Intelligence:, zz Kind/firm:, , He must be a person whose intelligence is above the average., , He must combine detachment with empathy., , Types of Focus Group, zz Respondent, , Moderator group: Under this method, the moderator will select, one of the participants to act as a temporary moderator., , 24, , Self Learning Material
Page 25 :
zz Dueling, , Moderator Group: In this method, there are two moderators. They Introduction to Research, Methodology, purposely take opposing positions on a given topic. This will help the researcher, to obtain the views of both groups., , zz Two-way, , Focus Group: Under this method, one group will listen to the other, group. Later, the second group will react to the views of the first group., , Notes, , zz Dual, , Moderator Group: Here, there are two moderators. One moderator will, make sure that the discussion moves smoothly. The second moderator will ask, a specific question., , Case Studies, Analyzing a selected case sometimes gives an insight into the problem which is being, researched. Case histories of companies which have undergone a similar situation, may be available. These case studies are well suited to carry out exploratory research., However, the result of investigation of case histories is always considered suggestive,, rather than conclusive. In case of preference to “ready to eat food”, many case histories, may be available in the form of previous studies made by competitors. We must carefully, examine the already published case studies with regard to other variables such as price,, advertisement, changes in the taste, etc., , 1.21 Conclusive Research, Meaning, This is a research having clearly defined objectives. In this type of research, specific, courses of action are taken to solve the problem., In conclusive research, there are two types:, 1. Descriptive research, 2. Experimental research or Causal research., , Descriptive Research, , Meaning, zz The, , name itself reveals that, it is essentially a research to describe something., For example, it can describe the characteristics of a group such as—customers,, organisations, markets, etc. Descriptive research provides “association between, two variables” like income and place of shopping, age and preferences., , zz Descriptive, , study informs us about the proportions of high and low income, customers in a particular territory. What descriptive research cannot indicate is, that it cannot establish a cause and effect relationship between the characteristics, of interest. This is the distinct disadvantage of descriptive research., Self Learning Material 25
Page 26 :
Research Methodology, , zz Descriptive, , study requires a clear specification of “Who, what, when, where,, why and how” of the research, for example, consider a situation of convenience, stores (food world) planning to open a new outlet. The company wants to, determine, “How people come to patronize a new outlet?” Some of the questions, that need to be answered before data collection for this descriptive study are, as follows:, , Notes, , Who?—Who, , is regarded as a shopper responsible for the success of the, shop, whose demographic profile is required by the retailer?, , What?—What, , characteristics of the shopper should be measured? Is it the, age of the shopper, sex, income or residential address?, , When?—When, , shall we measure?, , Should, , the measurement be made while the shopper is shopping or at a, later time?, , Where?—Where, , shall we measure the shoppers? Should it be outside, the stores, soon after they visit or should we contact them at their, residence?, , Why?—Why, , do you want to measure them?, , What is the purpose of measurement?—Based on the information, are there, , many strategies which will help the retailer to boost the sales? Does the, retailer want to predict future sales based on the data obtained?, Answer, , to some of the above questions will help us in formulating the, hypothesis., , How, , to measure? Is it a ‘structured’ questionnaire, ‘disguised’ or, ‘undisguised’ questionnaire?, , When to use Descriptive Study., 1. To determine the characteristics of market such as:, (i), , Size of the market, , (ii), , Buying power of the consumer, , (iii), , Product usage pattern, , (iv), , To find out the market share for the product, , (v), , To track the performance of a brand., , 2. To determine the association of the two variables such as Ad and sales., 3. To make a prediction. We might be interested in sales forecasting for the next three, years, so that we can plan for training of new sales representatives., 4. To estimate the proportion of people in a specific population, who behave, in a particular way? Example: What percentage of population in a particular, geographical location would be shopping in a particular shop?, 26, , Self Learning Material
Page 27 :
Hypothesis study at the descriptive research stage (to demonstrate the characteristics Introduction to Research, Methodology, of the group), Management problem, , Research problem, , Hypothesis, , How should a new product Where do customers Upper class buyers use, be distributed?, buy a similar product ‘Shopper’s Stop’ and middle, right now?, class buyers buy from local, departmental stores, , Notes, , What will be the target What kind of people Senior citizens buy our products., segment?, buys our product now? Young and married buy our, competitors products., , Types of Descriptive Studies, There are two types of descriptive research:, 1. Longitudinal study, 2. Cross-sectional study, , Longitudinal Study, These are the studies in which an event or occurrence is measured again and again over, a period of time. This is also known as ‘Time Series Study’. Through longitudinal study,, the researcher comes to know how the market changes over time. Longitudinal studies, involve panels. Panel once constituted will have certain elements. These elements may, be individuals, stores, dealers, etc. The panel or sample remains constant throughout the, period. There may be some dropouts and additions. The sample members in the panel are, being measured repeatedly. The periodicity of the study may be monthly or quarterly etc., Example for longitudinal study, assume a market research is conducted on ‘ready, to eat food’ at two different points of time T1 and T2 with a gap of 4 months. Each of, the above two times, a sample of 2000 household is chosen and interviewed. The brands, used most in the household are recorded as follows., Brands, , At T1, , At T2, , Brand X, , 500(25%), , 600(30%), , Brand Y, , 700(35%), , 650(32.5%), , Brand Z, , 400(20%), , 300(15%), , Brand M, , 200(10%), , 250(12.5%), , ALL OTHERS, , 200(10%), , 250(12.5%), , 200, , 100%, , As can be seen between period T1 and T2 Brand X and Brand M has shown an, improvement in market share. Brand Y and Brand Z have decrease in market share,, Self Learning Material 27
Page 28 :
Research Methodology whereas all other categories remain the same. This shows that Brand A and M have, gained market share at the cost of Y and Z., There are two types of panels:, zz True, , Notes, , panel, , zz Omnibus, , panel., , True panel: This involves repeat measurement of the same variables. Example:, Perception towards frozen peas or iced tea. Each member of the panel is examined at a, different time, to arrive at a conclusion on the above subject., Omnibus panel: In omnibus panel too, a sample of elements is being selected and, maintained, but the information collected from the member varies. At a certain point of, time, the attitude of panel members “towards an advertisement” may be measured. At, some other point of time the same panel member may be questioned about the “product, performance”., , Advantages of Panel Data, 1. We can find out what proportion of those who bought our brand and those who did, not. This is computed using the brand switching matrix., 2. The study also helps to identify and target the group which needs promotional effort., 3. Panel members are willing persons; hence a lot of data can be collected. This is, because becoming a member of a panel is purely voluntary., 4. The greatest advantage of panel data is that it is analytical in nature., 5. Panel data is more accurate than cross-sectional data because it is free from the error, associated with reporting past behaviour. Errors occur in past behaviour because, of time that has elapsed or forgetfulness., , Disadvantages of Panel Data, 1. The sample may not be representative. This is because sometimes, panels may be, selected on account of convenience., 2. The panel members, who have provided the data, may not be interested to continue, as panel members. There could be dropouts, migration, etc. Members who replace, them may differ vastly from the original member., 3. Remuneration given to panel members may not be attractive. Therefore, people, may not like to be panel members., 4. Sometimes the panel members may show disinterest and non-commitment., 5. A lengthy period of membership in the panel may cause respondents to start, imagining themselves to be experts and professionals. They may start responding, like experts and consultants and not like respondents. To avoid this, no one should, be retained as a member for more than 6 months., 28, , Self Learning Material
Page 29 :
Cross-sectional Study, Cross-sectional study is one of the most important types of descriptive research, it can, be done in two ways:, zz Field, , study, , zz Field, , survey, , Introduction to Research, Methodology, , Notes, , Field study: This includes a depth study. Field study involves an in-depth study of, a problem, such as reaction of young men and women towards a product, for example,, ‘Reaction of Indian men towards branded ready-to-wear suit’. Field study is carried out, in real world environment settings. Test marketing is an example of field study., Field survey: Large samples are a feature of the study. The biggest limitations, of this survey are cost and time. Also, if the respondent is cautious, he might answer, the questions in a different manner. Finally, field survey requires good knowledge like, constructing a questionnaire, sampling techniques used, etc., Example: Suppose the management believes that geographical factor is an, important attribute in determining the consumption of a product, like sales of a woollen, wear in a particular location. Suppose that the proposition to be examined is that, the, urban population is more likely to use the product than the semi-urban population. This, hypothesis can be examined in a cross-sectional study. Measurement can be taken from, a representative sample of the population in both geographical locations with respect to, the occupation and use of the products. In case of tabulation, researcher can count the, number of cases that fall into each of the following classes:, 1. Urban population which uses the product—Category I, 2. Semi-urban population which uses the product—Category II, 3. Urban population which does not use the product—Category III, 4. Semi-urban population which does not use the product—Category IV., Here, we should know that the hypothesis need to be supported and tested by the, sample data, i.e., the proportion of urbanities using the product should exceed the semiurban population using the product., , Causal Studies, Although descriptive information is often useful for predictive purposes, where possible, we would like to know the causes of what we are predicting—the “reasons why.” Further,, we would like to know the relationships of these causal factors to the effects that we are, predicting. If we understand the causes of the effects we want to predict, we invariably, improve our ability both to predict and to control these effects., , Bases for Inferring Causal Relationships, There are three types of evidence that can be used for drawing inferences about causal, relationships:, Self Learning Material 29
Page 30 :
Research Methodology, , 1. Associative variation, 2. Sequence of events, 3. Absence of other possible causal factors, , Notes, , In addition, the cause and the effect have to be related, i.e., there must be logical, implication (or theoretical justification) to imply the specific causal relation., , Associative Variation, Associative variation, or “concomitant variation,” as it is often termed, is a measure of, the extent to which occurrences of two variables are associated. Two types of associative, variation may be distinguished:, 1. Association by presence: A measure of the extent to which the presence of one, variable is associated with the presence of the other., 2. Association by change: A measure of the extent to which a change in the level of, one variable is associated with a change in the level of the other., It has been argued that two other conditions may also exist, particularly for, continuous variables:, (i), , The presence of one variable is associated with a change in the level of, other; and, , (ii), , A change in the level of one variable is associated with the presence of the, other (Feldman, 1975)., , Sequence of Events, A second characteristic of a causal relationship is the requirement that the causal factor, occurs first; the cause must precede the result. In order for salesperson retraining to, result in increased sales, the retraining must have taken place prior to the sales increase., , Absence of Other Possible Causal Factors, A final basis for inferring causation is the absence of any other possible causes other, than the one(s) being investigated. If it could be demonstrated, for example, that no other, factors present could have caused the sales increase in the third quarter, we could then, logically conclude that the salesperson training must have been responsible., Obviously, in an after-the-fact examination of an uncontrolled result such as an, increase in detergent sales, it is impossible to clearly rule out all causal factors other, than salesperson retraining. One could never be completely sure that there were no, competitor-, customer-, or company-initiated causal factors that would account for the, sales increase., , Conclusions Concerning Types of Evidence, No single type of evidence, or even the combination of all three types considered,, can ever conclusively demonstrate that a causal relationship exists. Other unknown, 30, , Self Learning Material
Page 31 :
factors may exist. However, we can obtain evidence that makes it highly reasonable to Introduction to Research, Methodology, conclude that a particular relationship exists. Exhibit 4.1 shows certain questions that, are necessary to answer., , Exhibit 4.1: Issues in Determining Causation, Several questions arise when determining whether a variable X has causal power, over another variable, Y:, , Notes, , 1. What is the source of causality—does X cause Y, or does Y cause X?, 2. What is the direction of causality—does X positively influence Y, or is the, relationship negative?, 3. Is X a necessary and sufficient cause—or necessary, but not sufficient cause—of, Y? Is X’s causation deterministic or probabilistic?, 4. Which value of the believed cause exerts a causal influence—its presence or, absence?, 5. Are the causes and effects the states themselves or changes in the states? Is the, relationship static or dynamic?, In the end, the necessary conditions for causality to exist are a physical basis for, causality, a cause that temporally precedes the effect (even for associative variation),, and a logical reason to imply the specific causal relation being examined. (Monroe, and Petroshius, n.d.)., , Difference Between Exploratory and Descriptive Research, Exploratory research, , Descriptive research, , It is concerned with the “Why” aspect, of consumer behaviour, i.e., it tries to, understand the problem and not measure, the result., , It is concerned with the “What”, “When”, or “How often” on the consumer, behaving., , This research does not require large, samples., , This needs large samples of respondents., , Sample need not to represent the, population., , Sample must be representative of, population., , Due to imprecise statement, data, collection is not easy., , Statement is precise. Therefore, data, collection is easy., , Characteristics of interest to be measured Characteristics of interest to be measured, are not clear., are clear., There is no need for a questionnaire for, collecting the data., , There should be a properly designed, questionnaire for data collection., Self Learning Material 31
Page 32 :
Research Methodology, , Notes, , Data collection methods are:, , Use of panel data, , Focus group, , Longitudinal, , Literature Searching, , Cross-sectional studies., , Case study, , 1.22, , How to Prepare a Synopsis, , Synopsis is an abstract form of research which underlines the research procedure followed, and is presented before the guide for evaluating its potentiality. In one sentence it may, be described as a condensation of the final report. The structure of synopsis varies and, also depends on the guides’ choice. However, for our understanding a common structure, may be framed as under:, 1. Defining the Problem: In defining the problem of the research objective, definition, of Glossary, general background information, limitations of the study and order of, presentation should be mentioned in brief., 2. Review of Existing Literature: In this head, researcher should study the summary, of different points of view on the subject matter as found in books, periodicals and, approach to be followed at the time of writing., 3. Conceptual Framework and Methodology: Under this head, the researcher should, first make a statement of the hypothesis. Discussion on the research methodology, used, duly pointing out the relationship between the hypothesis and objective of the, study and finally discussions about the sources and means of obtaining data should, also be made. In this head, the researcher should also point out the limitations of, methodology, if any, and the natural crises from which the research is bound to, suffer for such obvious limitations., 4. Analysis of Data: Analysis of the data involves testing of hypothesis from data, collected and key conclusions thus arrived., 5. General Conclusions: In general conclusions, the researcher should make a, restatement of objectives. Conclusion with respect to the acceptance or rejection, of hypothesis, conclusion with respect to the stated objectives, suggested areas, of further research and final discussion of possible implications of the study for a, model, group, theory and discipline., Finally, the researcher should mention about the bibliographies and appendices. The, above format is drawn after a standard framework followed internationally in preparation, of a synopsis. However, in our country, keeping in view the object of research, style and, structure of synopsis varies and quite often it is found that the research guide exercises, his own discretion in synopsis preparation than following some acceptable international, norms. A standard format for preparation of synopsis commonly used in management, and commerce research in India may be drawn as follows:, 32, , Self Learning Material
Page 33 :
1. Introduction: This includes definition of the problem and its review from a historical Introduction to Research, Methodology, perspective., 2. Objective of the Study: It defines the research purpose and its specialty from the, existing available research in the related field., , Notes, , 3. Literature Review: It includes among other things, different sources from which, the required abstract is drawn., 4. Methodology: It is intended to draw out the sequences followed in research and, ways and manners of carrying out the survey and compilation of data., 5. Hypothesis: It is a formal statement relating to the research problem and it need to, be tested on the basis of the researchers’ findings., 6. Model: It underlies the nature and structure of the model that the researcher is going, to build in the light of survey findings., , 1.23 Choosing a Research Design, The overview of research designs and sources of error just presented should make it, apparent that, given a specified problem, many competing designs can provide relevant, information. Each design will have an associated expected value of information and, incurred cost., Suppose, for example, that a researcher is assigned to determine the market share, of the ten leading brands of energy drinks. There are many possible ways of measuring, market share of energy drink brands, including questioning a sample of respondents,, observing purchases at a sample of retail outlets, obtaining sales figures from a sample, of wholesalers, obtaining sales figures from a sample of retailers and vending machine, operators, obtaining tax data, subscribing to a national consumer panel, subscribing, to a national panel of retail stores, and, possibly, obtaining data directly from trade, association reports or a recent study by some other investigative agency. Though lengthy,, this listing is not exhaustive., The selection of the best design from the alternatives is no different in principle, from choosing among the alternatives in making any decision. The associated expected, value and cost of information must be determined for each competing design option. If the, design is such that the project will yield information for solving more than one problem,, the expected value should be determined for all applicable problems and summed. The, design with the highest, positive, net expected payoff of research should be selected., , 1.24 Summary, Research Methodology is a way to find out the result of a given problem on a specific, matter or problem that is also referred as research problem. In Methodology, researcher, Self Learning Material 33
Page 34 :
Research Methodology uses different criteria for solving/searching the given research problem. Different sources, use different type of methods for solving the problem., , Notes, , Research methodology is a way to systematically solve the research problem. It, may be understood as a science of studying how research is done scientifically. In it, we study the various steps that are generally adopted by a researcher in studying his, research problem along with the logic behind them., We’ve introduced the research process and discussed some of the decisions that, need to be made before you start your research project., This unit has introduced the research process planning from the perspective of, valuing research on the basis of how well it has been done (the management of total, error). Planning are search project that includes:, zz Problem, zz Method, , formulation, , of inquiry, , zz Research, , method, , zz Research, , design, , zz Selection, , of data collection techniques, , zz Sample, zz Data, , design, , collection, , zz Analysis, , and interpretation of data, , zz Research, , reports, , We’ve also discussed how managers use research to help with decision-making. It’s, important to build strong and frequent communication between team members, decision, makers, and clients. As you develop your research project, you want to consult with the, decision makers throughout the project, building a common understanding of exactly, what is needed and is to be provided to assure success., Proper problem formulation is the key to success in research. It is vital and any, error in defining the problem incorrectly can result in wastage of time and money. Several, elements of introspection will help in defining the problem correctly., In this unit, we have dealt with a subject of single most importance to the research, project: the research design. We described what a research design is, discussed the classes, of designs, and examined major sources of marketing information that various designs, employ. Finally, we considered the errors that affect research designs., The unit deals with two types of research namely exploratory research and, descriptive research exploratory research helps the researcher to become familiar with, the problem. It helps to establish the priorities for further research. It may or may not, be possible to formulate hypothesis during exploratory stage. To get an insight into the, problem, literature search, experience surveys, focus groups, and selected case studies, 34, , Self Learning Material
Page 35 :
assist in gaining insight into the problem. The role of moderator or facilitator is extremely Introduction to Research, Methodology, important in focus group. There are several variations in the formation of focus group., , 1.25 Glossary, zz Marketing, , research: Marketing research is about researching the whole of a, company’s marketing process., , Notes, , zz Exploratory, , research: Exploratory research provides insights into and, comprehension of an issue or situation., , zz Descriptive, , research: Descriptive research includes surveys and fact-finding, enquiries of different kinds., , zz Applied research: Applied research aims at finding a solution for an immediate, , problem facing a society or an industrial/business organization., zz Fundamental, , research: Fundamental research is mainly concerned with, generalisations and with the formulation of a theory., , zz Research methodology: Research methodology is a way to systematically solve, , the research problem., zz Research, , design: The research design is a plan or framework for conducting, , the study and collecting data., zz Research, , problem: It focuses on the relevance of the present research., , zz Objective, , of Research: It means to what the researcher aims to achieve., , zz Literature, , research: It refers to “referring to a literature to develop a new, hypothesis”., , zz Conclusive, , research: This is a research having clearly defined objectives., In this type of research, specific courses of action are taken to solve the, problem., , zz Descriptive, , research: It is essentially a research to describe something., , zz Longitudinal, , study: These are the studies in which an event or occurrence is, measured again and again over a period of time., , zz Field, , study: Field study involves an in-depth study of a problem, such as, reaction of young men and women towards a product., , zz Synopsis:, , Synopsis is an abstract form of research which underlines the, research procedure followed and is presented before the guide for evaluating, its potentiality., , 1.26 Review Questions, 1. What do you mean by research?, 2. Distinguish between Research methods and Research methodology., Self Learning Material 35
Page 36 :
Research Methodology, , Notes, , 3. Write short notes on following:, (i), , Exploratory research, , (ii), , Descriptive research, , 4. Discuss the objectives of research., 5. What are the qualities of a good research?, 6. What are the Problems Encountered by Researchers in India?, 7. What are the various types of research? Discuss in detail., 8. What is a scientific method?, 9. What are the various methods of inquiry?, 10. List any two methods of data collection., 11. Explain the importance of formulating the research problem., 12. Describe in detail various steps of conducting research., 13. hat is a research problem?, 14. What are the steps involved in formulating the problem?, 15. What are the sources of problem?, 16. What is a research problem? Why is it necessary to formulate the problem?, 17. Explain the steps involved in formulating the problem?, 18. What are the sources of problem? Describe in detail., 19. What are the questions posed for self while formulating the problem?, 20. “The objective of research problem should be clearly defined; otherwise the data, collection becomes meaningless”. Explain with suitable examples., 21. Why is research design necessary to conduct a study?, 22. What are the various types of research design? Explain with examples., 23. What is exploratory research? Give Example under what circumstances, exploratory, research is ideal., 24. What are the sources available for data collection at exploratory stage?, 25. What are the different variations in the focus group?, 26. For each of the situation mentioned below, state whether the research should be, exploratory, descriptive or causal:, , 36, , Self Learning Material, , (i), , To find out the relationship between promotion and sales., , (ii), , To find out the consumer reaction regarding use of new detergents which, are economical?, , (iii), , To identify the target market demographics, for a shopping mall., , (iv), , Estimate the sales potential for ready-to-eat food in the northeastern parts, of India.
Page 37 :
27. What are the characteristic that a moderator should possess while conducting the Introduction to Research, Methodology, focus group?, 28. What are the uses of descriptive research and when will it is used?, 29. What are the various types of descriptive studies?, 30. What are the Longitudinal and cross sectional studies?, , Notes, , 31. Describe the various types of panels and its use., 32. What is a Sample survey? What are its benefits?, 33. What are the various types of cross sectional studies?, 34. What are the benefits and limitations of each?, 35. Distinguish exploratory from descriptive research., 36. What are the advantages and disadvantages of panel data?, , 1.27 Further Readings, Kothari, Research Methodology, Willey International Ltd., New, , zz C.R., , Delhi, J. Goode and Paul K. Hatt, Methods in Social Research, McGraw, Hill, New Delhi, , zz William, , Moser and G. Kalton, Survey Methods in Social Investigation, , zz C.A., , Bhandar Kar and T.S. Wilkinson, Methodology and Techniques of Social, Research, Himalaya Publishing House, Delhi, , zz P.L., , Michael, Research Methodology in Management, Himalaya Publishing, House, Delhi, , zz V.P., , zz S.R., , Bajpai, Methods of Social Survey and Research, Kitab Ghar, Kanpur, , Gopal, An Introduction to Research Procedure in Social Sciences, Asian, Publishing House, Bombay, , zz M.H., , Self Learning Material 37
Page 38 :
Research Methodology, , Notes, , UNIT–2, , Sampling and Data Collection, (Structure), 2.1, , Learning Objectives, , 2.2, , Introduction, , 2.3, , What is a Hypothesis?, , 2.4, , Null and Alternative Hypotheses, , 2.5, , Making Inferences, , 2.6 �The Relationship between a Population, a Sampling Distribution, and a Sample, , 38, , Self Learning Material, , 2.7, , Hypothesis Testing, , 2.8, , Steps in Hypothesis Testing, , 2.9, , Type I and Type II Errors, , 2.10, , Secondary Data, , 2.11, , Special Techniques of Market Research or Syndicated Data, , 2.12, , Advantages and Disadvantages of Secondary Data, , 2.13, , Primary Data, , 2.14, , Methodology for Collection of Primary Data, , 2.15, , Qualitative Versus Quantitative Research, , 2.16, , Conditions for a Successful Interview, , 2.17, , Descriptive Research Design: Survey, , 2.18, , Descriptive Research Design: Observation, , 2.19, , Why Sample?, , 2.20, , Distinction Between Census and Sampling, , 2.21, , Terms Used in Sampling, , 2.22, , Sampling Process, , 2.23, , Sampling Techniques, , 2.24, , Sample Sizes: Considerations, , 2.25, , Sampling Challenges, , 2.26, , Probability Samples, , 2.27, , Non-probability Sampling
Page 39 :
2.28, , Random Selection and Random Assignment, , 2.29, , Determining the Sample Size When Random Sampling is used, , 2.30, , Sampling in Mixed Research, , 2.31, , Distinction between Probability Sample and Non-probability Sample, , 2.32, , Errors in Sampling, , 2.33, , Summary, , 2.34, , Glossary, , 2.36, , Further Readings, , 2.1, , Sampling and Data, Collection, , Notes, , Learning Objectives, , After studying the chapter, students will be able to:, zz State, , the need of hypothesis in research;, , zz Describe, zz Discuss, zz Relate, , the use of null and alternative hypothesis;, , the steps in hypothesis testing;, , the difference between type I and type II errors;, , zz Know, , what is primary data and what are the methods adopted for collecting, primary data;, , zz Know, , what are the various steps involved in designing a questionnaire;, , zz Understanding, , what are the advantages/ limitations of a mail questionnaire/, Secondary sources;, , zz Know, , how to conduct successful interview;, , zz Explain, , how to collect data through observation method;, , zz Differentiate, zz Understand, , 2.2, , between census and sample;, , the process of sampling;, , zz Discuss, , various types of probability sampling techniques;, , zz Discuss, , various types of non-probability sampling techniques., , Introduction, , Scientific research is directed at the inquiry and testing of alternative explanations of, what appears to be fact. For behavioural researchers, this scientific inquiry translates, into a desire to ask questions about the nature of relationships that affect behaviour, within markets. It is the willingness to formulate hypotheses capable of being tested to, determine (1) what relationships exist, and (2) when and where these relationships hold., The first stage in the analysis process is identified to include editing, coding, and, making initial counts of responses (tabulation and cross tabulation). In the current unit,, Self Learning Material 39
Page 40 :
Research Methodology we then extend this first stage to include the testing of relationships, the formulation of, hypotheses, and the making of inferences., , Notes, , In formulating hypotheses the researcher uses “interesting” variables, and considers, their relationships to each other, to find suggestions for working hypotheses that may, or may not have been originally considered. In making inferences, conclusions are, reached about the variables that are important, their parameters, their differences, and, the relationships among them. A parameter is a summarizing property of a collectivity—, such as a population—when that collectivity is not considered to be a sample (Mohr,, 1990, p.12)., Although the sequence of procedures, (a) formulating hypotheses, (b) making, inferences and (c) estimating parameters is logical, in practice these steps tend to merge, and do not always follow in order. For example, the initial results of the data analysis, may suggest additional hypotheses that in turn require more and different sorting and, analysis of the data. Similarly, not all of the steps are always required in a particular, project; the study may be exploratory in nature, which means that it is designed more, to formulate the hypotheses to be examined in a more extensive project, than to make, inferences or estimate parameters., In this unit, we will discuss several methods of qualitative research methods, commonly adopted in educational research, namely; ethnography, case study, action, research and the generic qualitative method. Irrespective of research method adopted,, the techniques of data collection are more or less similar. In this unit, we will discuss, in detail three common data collection or evidence-gathering techniques employed in, qualitative research methods. For example, the experimental method in quantitative, research uses tests or attitude scales to collect data. Similarly, the survey method use, questionnaires and interview checklists to collect data. Therefore, for ethnography or, case study methods or action research the data collection techniques employed could, be observations, interviews or the examination of documents or a combination of three, techniques., The purpose of this unit is to help you learn about sampling in quantitative,, qualitative, and mixed research. In other words, you will learn how participants are, selected to be part of empirical research studies., Sampling refers to drawing a sample (the subset) from a population (the full set)., zz The usual goal in sampling is to produce a representative sample (i.e., a sample, , which is similar to the population on all characteristics, except that it includes, fewer people because it is a sample rather than the complete population)., zz Metaphorically, a perfectly representative sample would be a “mirror image” of, , the population from which it was selected (again, except that it would include, fewer people)., 40, , Self Learning Material
Page 41 :
In the previous unit, you have studied about the fundamental concepts of sampling., In this unit, you will study in detail about the various types of samples and errors in, sampling. Although there are a number of different methods that might be used to, create a sample, they generally can be grouped into one of two categories: probability, samples or non-probability samples. In the first part of the unit you will study about, probability sampling techniques and in the next part you will study about various types, of non-probability sampling techniques. Lastly, you will study about errors in sampling., , 2.3, , Sampling and Data, Collection, , Notes, , What is a Hypothesis?, , As a beginning point in the discussion of hypotheses testing, we ask: what is a hypothesis?, A hypothesis is an assertion that variables (measured concepts) are related to a specific, way such that this relationship explains certain facts or phenomena. From a practical, standpoint, hypotheses may be developed to solve a problem, answer a question, or, imply a possible course of action. Outcomes are predicted if a specific course of action, is followed. Hypotheses must be empirically testable. A hypothesis is often stated as a, research question when reporting either the purpose of the investigation or the findings., The hypothesis may be stated informally as a research question, or more formally, as an alternative hypothesis, or in a testable form known as a null hypothesis., Hypothesis: A prediction of the outcome of a study. Hypotheses are drawn from, theories and research questions or from direct observations. In fact, a research problem, can be formulated as a hypothesis. To test the hypothesis we need to formulate it in, terms that can actually be analysed with statistical tools., As an example, if we want to explore whether using a specific teaching method at, school will result in better school marks (research question), the hypothesis could be that, the mean school marks of students being taught with that specific teaching method will, be higher than of those being taught using other methods. In this example, we stated a, hypothesis about the expected differences between groups. Other hypotheses may refer, to correlations between variables., Thus, to formulate a hypothesis, we need to refer to the descriptive statistics (such, as the mean final marks), and specify a set of conditions about these statistics (such, as a difference between the means, or in a different example, a positive or negative, correlation). The hypothesis we formulate applies to the population of interest., The null hypothesis makes a statement that no difference exists (see Pyrczak,, 1995, pp. 75-84)., Research questions state in layman’s terms the purpose of the research, the variables, of interest, and the relationships to be examined. Research questions are not empirically, testable, but aid in the important task of directing and focusing the research effort. To, illustrate, a sample research question is developed in the following scenario:, Self Learning Material 41
Page 42 :
Research Methodology, , Exhibit 2.1: Development of a Research, Question for Mingles, Mingles is an exclusive restaurant specialized in seafood prepared with a light, Italian flair. Barbara C., the owner and manager, has attempted to create an airy, contemporary atmosphere that is conducive to conversation and dining enjoyment., In the first three months, business has grown to about 70 % of capacity during, dinner hours., , Notes, , Barbara wants to track customer satisfaction with the Mingles concept, the quality, of the service, and the value of the food for the price paid. To implement the, survey, a questionnaire was developed using a five-point expectations scale with, items scaled as values from –2 to +2. The questionnaire asks, among other things:, “How would you rate the value of Mingles food for the price paid”?, The response format for the five answers appeared as:, When tabulated, the average response was found to be +0.89 with a sample standard, deviation of 1.43. The research question asks if Mingles is perceived as being better, than average when considering the price and value of the food., Additional questions measure customer satisfaction by addressing “How satisfied, Mingles customers are with the concept, service, food, and value”., , Why State Hypothesis?, The hypothesis guides us on the selection of a certain design, observations and methods, of researching over others., Based on previous theory and research, research questions are formulated, which, are “translated” into hypothesis, which, by turn, are tested using a sample in order to, make inferences for the whole population., If we could test the whole population directly, we would not need to formulate, hypothesis, conduct inferential statistics and make inferences for the population based, on a sample. However, it is often impossible to test the whole population, and we need, to make our observations based on a sample., If differences (or relationships) between variables are revealed, the null hypothesis is, tested for significance. This test may determine whether these differences (or relationships), are “real”, in other words, if they are due to true differences between the groups instead, of due to, say, sampling error., Sample results are often subject to sampling fluctuations. These fluctuations could, account for the differences between the mean exam scores the students had in our example., Since we are researching a sample drawn from a population, we should always expect, some variation in the sample statistics, such as the mean exam scores, in our example,, between the groups of students being taught using different methods., 42, , Self Learning Material
Page 43 :
2.4 Null and Alternative Hypotheses, , Sampling and Data, Collection, , Null Hypotheses, Null Hypotheses (H0) are statements identifying relationships that are statistically, testable and can be shown not to hold (nullified). The logic of the null hypothesis is, that if we hypothesize no difference, and we “reject” the hypotheses if a difference is, found. If, however, we confirm that no difference exists, we “tentatively accept” the null, hypothesis. We may only accept the null on a “tentative” basis because another testing, of the null hypothesis using a new sample may reveal that sampling error was present, and that the null hypothesis should be rejected., , Notes, , The null hypothesis, H0, is an essential part of any research design, and is always, tested, even indirectly., For example, to compare the population and the sample, the null hypothesis might, be: “There is no difference between the perceived price-value of Mingles food and what, is expected on average. In this example, the difference between the population average,, which is assumed to be the middle scale value of 0 = “about average” and the sample’s, mean evaluation of Mingles can be tested using the z distribution., , Examples of the Null Hypothesis, A researcher may postulate a hypothesis:, H1: Tomato plants exhibit a higher rate of growth when planted in compost rather, than in soil., And a null hypothesis:, H0: Tomato plants do not exhibit a higher rate of growth when planted in compost, rather than soil., It is important to carefully select the wording of the null, and ensure that it is as, specific as possible. For example, the researcher might postulate a null hypothesis:, H0: Tomato plants show no difference in growth rates when planted in compost, rather than soil., There is a major flaw with this H0. If the plants actually grow more slowly in, compost than in soil, an impasse is reached. H1 is not supported, but neither is H0,, because there is a difference in growth rates., If the null is rejected, with no alternative, the experiment may be invalid. This is, the reason why science uses a battery of deductive and inductive processes to ensure, that there are no flaws in the hypotheses., Many scientists neglect the null, assuming that it is merely the opposite of the, alternative, but it is good practice to spend a little time creating a sound hypothesis. It, is not possible to change any hypothesis retrospectively, including H0., Self Learning Material 43
Page 44 :
Research Methodology Significance Tests, If significance tests generate 95% or 99% likelihood that the results do not fit the null, hypothesis, it is rejected, in favour of the alternative., , Notes, , Otherwise, the null is accepted. These are the only correct assumptions, and it is, incorrect to reject, or accept, H1., Accepting the null hypothesis does not mean that it is true. It is still a hypothesis,, and must conform to the principle of falsifiability, in the same way that rejecting the, null does not prove the alternative., , Perceived Problems With the Null, The major problem with the H0 is that many researchers, and reviewers, see accepting, the null as a failure of the experiment. This is very poor science, as accepting or rejecting, any hypothesis is a positive result., Even if the null is not refuted, the world of science has learned something new., Strictly speaking, the term ‘failure’, should only apply to errors in the experimental, design, or incorrect initial assumptions., , Development of the Null, The Flat Earth model was common in ancient times, such as in the civilizations of the, Bronze Age or Iron Age. This may be thought of as the null hypothesis, H0, at the time., , H0: World is Flat, Many of the Ancient Greek philosophers assumed that the sun, the moon and other, objects in the universe circled around the Earth. Hellenistic astronomy established the, spherical shape of the earth around 300 BC., , H0: The Geocentric Model: Earth is the centre of the Universe and it is, Spherical, Copernicus had an alternative hypothesis, H1 that the world actually circled around, the sun, thus being the center of the universe. Eventually, people got convinced and, accepted it as the null, H0., , H0: The Heliocentric Model: The sun is the centre of the universe, Later someone proposed an alternative hypothesis that the sun itself also circled around, the something within the galaxy, thus creating a new H0. This is how research works - the, H0 gets closer to the reality each time, even if it isn’t correct, it is better than the last H0., , Alternative Hypotheses, Alternative hypotheses may be considered to be the opposite of the null hypotheses. The, alternative hypothesis makes a formal statement of expected difference, and may state, 44, , Self Learning Material
Page 45 :
simply that a difference exists or that a directional difference exists, depending upon, how the null hypothesis is stated. Because population differences may exist, even if not, verified by the current sample data, the alternative form is considered to be empirically, non-testable., The objectives and hypotheses of the study should be stated as clearly as possible, and agreed on at the outset. Objectives and hypotheses shape and mold the study; they, determine the kinds of questions to be asked, the measurement scales for the data to, be collected, and the kinds of analyses that will be necessary. However, a project will, usually turn up new hypotheses, regardless of the rigor with which it was planned and, developed. New hypotheses are continually suggested as the project progresses from, data collection through the final interpretation of the findings., , Sampling and Data, Collection, , Notes, , In Unit 2, it was pointed out that when the scientific method is strictly followed,, hypothesis formulation must precede the collection of data. This means that according, to the rules for proper scientific inquiry, data suggesting a new hypothesis should not, be used to test it. New data must be collected prior to testing a new hypothesis., In contrast to the strict procedures of the scientific method, where hypotheses, formulation must precede the collection of data, actual research projects almost always, formulate and test new hypotheses during the project. It is both acceptable and desirable, to expand the analysis to examine new hypotheses to the extent that the data permit. At, one extreme, it may be possible to show that the new hypotheses are not supported by, the data and that no further investigation should be considered. At the other extreme,, a hypothesis may be supported by both the specific variables tested and by other, relationships that give similar interpretation. The converging results from these separate, parts of the analysis strengthen the case that the hypothesized relationship is correct., Between these extremes of nonsupport-support are outcomes of indeterminacy: the new, hypothesis is neither supported nor rejected by the data. Even this result may indicate, the need for an additional collection of information., In a position yet more extreme from scientific method, Selvin and Stuart (1966), convincingly argue that in survey research, it is rarely possible to formulate precise, hypotheses independently of the data. This means that most survey research is essentially, exploratory in nature. Rather than having a single pre-designated hypothesis in mind, the, analyst often works with many diffuse variables that provide a slightly different approach, and perspective on the situation and problem. The added cost of an extra question is so, low that the same survey can be used to investigate many problems without increasing, the total cost. However, researchers must resist the syndrome of “just one more question”., Often, the one more question escalates into many more questions of the type “it would, be nice to know”, which can be unrelated to the research objectives., In a typical survey project, the analyst may alternate between searching the data, (analyzing) and formulating hypotheses. Obviously, there are exceptions to all general, Self Learning Material 45
Page 46 :
Research Methodology rules and phenomena. Selvin and Stuart (1966), therefore, designate three practices of, survey analysts:, 1. Snooping: The process of searching through a body of data and looking at many, relations in order to find those worth testing (that is, there are no pre-designated, , Notes, , hypotheses)., 2. Fishing: The process of using the data to choose which of a number of predesignated variables to include in an explanatory model., 3. Hunting: The process of testing from the data all of a pre-designated set of, hypotheses. This investigative approach is reasonable for basic research but may not, be practical for decisional research. Time and resource pressures seem to require that, directed problem solving be the focus of decision research. Rarely can the decision, maker afford the luxury of dredging through the data to find all of the relationships, that must be present. Again, it simply reduces to the question of cost versus value., , 2.5, , Making Inferences, , Testing hypotheses is the broad objective that underlies all decisional research. Sometimes, the population as a whole can be measured and profiled in its entirety. Often, however,, we cannot measure everyone in the population rather we must estimate the population, using a sample of respondents drawn from the population. In this case, we estimate, the population “parameters” using the sample “statistics”. Thus, in both estimation and, hypothesis testing, inferences are made about the population of interest on the basis of, information from a sample., We often will make inferences about the nature of the population and ask a multitude, of questions, such as: Does the sample’s mean satisfaction differ from the mean of the, population of all restaurant patrons? Does the magnitude of the observed differences, between categories indicate that actual differences exist, or are they the result of random, variations in the sample? In other studies, it may be sufficient to simply estimate the, value of certain parameters of the population, such as the amount of our product used per, household, the proportion of stores carrying our brand, or the preferences of housewives, concerning alternative styles or package designs of a new product. Even in these cases,, however, we would want to know about the underlying associated variables that influence, preference, purchase, or use (color, ease of opening, accuracy in dispensing the desired, quantity, comfort in handling, etc.), and if not for purposes of the immediate problem,, then for solving later problems. In yet other case studies, it might be necessary to analyze, the relationships between the enabling or situational variables that facilitate or cause, behaviour. Knowledge of these relationships will enhance the ability to make reliable, predictions, when decisions involve changes in controllable variables., 46, , Self Learning Material
Page 47 :
2.6 T, � he Relationship between a Population, a Sampling, Distribution, and a Sample, In order to simplify the example, suppose there is a population consisting of only five, persons. On a specific topic, these five persons have a range of opinions that are measured, on a 7-point scale ranging from very strongly agree to very strongly disagree., , Sampling and Data, Collection, , Notes, , The parameters describe this population as having a mean of μ = 4 and standard, deviation = 2. Now that we know the “parameters” of the population, we will consider, the sampling distribution for our example data. Assume for a moment that like most, populations, ours is so large that we are not able to measure all persons in this population,, but must rely instead on a sample. In our example, the population is not large, and we, will assume a sample of size n = 2. The sampling distribution is the distribution pf, sample means from all possible samples of size n = 2., , 2.7 Hypothesis Testing, Once you have generated a hypothesis, the process of hypothesis testing becomes, important. More accurately, you should have two hypotheses, the alternative and the null., For testing, you will be analyzing and comparing your results against the null, hypothesis, so your research must be designed with this in mind. It is vitally important, that the research you design produces results that will be analyzable using statistical tests., Hypotheses, Induction, , Deduction, , Test of Predictions, , Predictions, , Observation, , Fig. 2.1: Hypothesis Testing, Most people are very afraid of statistics, due to obscure mathematical symbols,, and worry about not understanding the processes or messing up the experiments. There, really is no need to fear., Most scientists understand only the basic principles of statistics, and once you have, these, modern computing technology gives a whole battery of software for hypothesis, testing., Self Learning Material 47
Page 48 :
Research Methodology, , Designing your research only needs a basic understanding of the best practices for, selecting samples, isolating testable variables and randomizing groups., , Hypothesis Testing Example, , Notes, , A common statistical method is to compare a population to the mean., For example, you might have come up with a measurable hypothesis that children, have a higher IQ if they eat oily fish for a period of time., Your alternative hypothesis, H1 would be, “Children who eat oily fish for six months will show a higher IQ increase than, children who have not.”, Therefore, your null hypothesis, H0 would be, “Children who eat oily fish for six months do not show a higher IQ increase than, children who do not.”, In other words, with the experiment design, you will be measuring whether the IQ, increase of children fed oily fish will deviate from the mean, assumed to be the normal, condition., H0 = No increase. The children will show no increase in mean intelligence., From IQ testing of the control group, you find that the control group has a mean, IQ of 100 before the experiment and 100 afterwards, or no increase. This is the mean, against which the sample group will be tested., The children fed fish show an increase from 100 to 106. This appears to be an, increase, but here is where the statistics enters the hypothesis testing process. You, need to test whether the increase is significant, or if experimental error and standard, deviation could account for the difference., Using an appropriate test, the researcher compares the two means, taking into, account the increase, the number of data samples and the relative randomization of the, groups. A result showing that the researcher can have confidence in the results allows, rejection of the null hypothesis., Remember, not rejecting the null is not the same as accepting it. It is only that this, particular experiment showed that oily fish had no affect upon IQ. This principle lies at, the very heart of hypothesis testing., , Significance, The exact type of statistical test used depends upon many things, including the field,, the type of data and sample size, among other things., The vast majority of scientific research is ultimately tested by statistical methods,, all giving a degree of confidence in the results., For most disciplines, the researcher looks for a significance level of 0.05, signifying, that there is only a 5% probability that the observed results and trends occurred by chance., 48, , Self Learning Material
Page 49 :
For some scientific disciplines, the required level is 0.01, only a 1% probability, that the observed patterns occurred due to chance or error. Whatever the level, the, significance level determines whether the null or alternative is rejected, a crucial part, of hypothesis testing., , Empirical Evidence, , Sampling and Data, Collection, , Notes, , “Empirical evidence” or “scientific evidence” is the evidence which serves the purpose, of either supporting or counter a scientific hypothesis or theory., The word “empirical” indicates information gained by means of observation,, experience, or experiments., A central theme of science and scientific method is that all evidence must be, empirical, or at least empirically based, that is, it should depend on evidence or results that, can be observed by our senses. It should be noted here that scientific statements are, subject to and derived from our experience or observations and empirical data is based, on both observations and experiment results., In the process of accepting or disproving any hypothesis, facts (evidence) are, coupled with inference which is the act of deriving a conclusion on the basis of, observations or experiment., However, scientific evidence or empirical evidence is the evidence where evidence, does depend on inference thus it enables other researchers to examine the assumptions, or hypothesis employed to see if facts are relevant at all to the support of or counter, the hypothesis., For example, an infective organism, “Helicobacter pylori”, has shown to cause, stomach ulcers in humans. Following evidence may prove the hypothesis that H. pylorus, is indeed a cause of peptic ulcers in humans., zz If, , someone voluntarily ingests H. pylori, it results in chronic gastritis, , zz Experimental, , challenge to animals stimulates human infection and, , gastritis, zz Proper, , antimicrobial therapy in patients clears infection and thus clears, , gastritis, zz The, , H. pylori only found in gastric epithelium, , zz There, , is a systemic immune response seen in patients with H. pylori, infection, , zz Antibodies, , against H. pylori disappears after successful antimicrobial, , therapy, Let’s take another example of global warming which remains an ongoing dispute, about the effects of humans on global climate. You may hear following evidence in, favour or theory of global warming:, Self Learning Material 49
Page 50 :
Research Methodology, , zz Graphs, zz The, , levels of carbon dioxide gas are on the rise in atmosphere, , zz The, , levels of methane are also rising, , zz We, , Notes, , of historical trends show increasingly warming temperature, , have seen more frequent extreme weather as never before, , zz Glaciers, zz Arctic, , are disappearing rapidly, , seas’ ice is melting, , zz Antarctic, , seas’ ice is also melting, , zz Greenland’s, zz Incidence, zz Oceans, , ice sheet is also melting, , of tropical diseases is on the rise, , are warming with Coral bleaching and disintegration, , No hypothesis or theory can be called scientific or accepted if it lacks empirical, evidence in favour. Therefore, empirical evidence can be used both to accept or to, counter any scientific hypothesis or theory., , 2.8, , Steps in Hypothesis Testing, , As we have seen earlier in this Unit, hypothesis testing is all about populations and using, a sample based on which we make inferences about the population. We have seen so far, how to formulate hypothesis, what is the place of hypothesis testing in research, and some, important concepts such as sampling distributions, confidence intervals, critical regions, and significance levels. In this topic, we will refer to the steps of hypothesis testing., zz The, , first step is to formulate the alternative and null hypotheses., , zz The, , second step is to test the null hypothesis (rather than seeking to support, the experimental hypothesis), by carrying out a statistical test of significance, to determine whether it can be rejected, and consequently, whether there is a, difference between the groups under investigation., , For our example research question (effect of teaching method on final exams, marks), the researcher would run statistical tests to test whether the difference between, the means of the two samples of students (those who used method A and those who, used method B) is zero., Remember that, while testing the hypothesis of a relationship between two variables, we calculate a probability: the probability of obtaining such a relationship as a result, of sampling error alone (conditional probability). It is the probability of obtaining a, relationship in our sample by sampling error alone, if there was no such relationship in, the population. If this probability is small enough, it makes more sense to conclude that, the relationship observed in our sample also exists in the population., zz In, , the third step, the sample statistics appropriate for the sample, variables and, hypotheses are calculated (in our hypotheses, the mean exam score)., , 50, , Self Learning Material
Page 51 :
zz In, , the fourth step, a significance test is conducted, to see if the null hypothesis, can be rejected., , To do this, we first start with the assumption that the null hypothesis is true, and, proceed to determine the probability of obtaining the sample results. In order to understand, hypothesis testing, this is a quite important step to understand., , Sampling and Data, Collection, , Notes, , If the null hypothesis is true, what is the probability of obtaining the sample results?, Hypothesis testing involves the calculation of the probability of observing the data, collected. If this probability (also know as p-value) is small, it would be very unlikely, that the observed sequence would have occurred if the null hypothesis was true., The hypothesis is retained if a test of significance would show that if the research, were repeated many times, similar results would occur in at least 95 out of 100 repetitions,, or in other words if the p-value (probability of obtaining the results) is less than 5% (we, would then write: p< 0.05). This specific criterion of significance level is a convention., (Sometimes two other probability levels are reported, that is, p< 0.01 (odds of 99 to 1), and p< 0.001 (odds of 999 to 1, as will be mentioned later in this topic)., zz Therefore,, , in the final step, the decision is made to reject or accept the null, hypothesis:, , If the probability is small, i.e., less than 0.05, the null hypothesis is rejected and, the experimental hypothesis is retained, since we can say with some certainty (95%, certainty) that the differences discovered between the groups in our example are not, due to sampling error, but other factors., Looking at the odds we realise that it is much more likely that the null hypothesis, will be retained (95 to 1 for the 0.05 level of significance). To reject the null hypothesis, we require at least a probability of 95 confirmations that there are differences in the, groups for every 100 repetitions of the study., If the probability is large, the null hypothesis cannot be rejected., , 2.9 Type I and Type II Errors, It may become obvious from what has been discussed so far, that, as the procedure of, significance testing is based on probabilities, it is not without errors., We may sometimes incorrectly reject the null hypothesis (rejects it when it is true)., This is called Type I error (α)., Other times, we may fail to reject the null hypothesis, and actually reject the, alternative hypothesis (when it is true), which is called Type II error (β)., , Type I Error, In a hypothesis test, a type I error occurs when the null hypothesis is rejected when it, is in fact true; that is, H0 is wrongly rejected., Self Learning Material 51
Page 52 :
Research Methodology, , For example, in a clinical trial of a new drug, the null hypothesis might be that, the new drug is no better, on average, than the current drug; i.e., H0: there is no difference between the two drugs on average., , Notes, , A type I error would occur if we concluded that the two drugs produced different, effects when in fact there was no difference between them., The following table gives a summary of possible results of any hypothesis test:, Decision, , Reject H0, Truth, , Don't reject H0, H0, , Type I Error, , Right decision, , H1, , Right decision, , Type II Error, , A type I error is often considered to be more serious, and therefore more important, to avoid, than a type II error. The hypothesis test procedure is therefore adjusted so that, there is a guaranteed ‘low’ probability of rejecting the null hypothesis wrongly; this, probability is never 0. This probability of a type I error can be precisely computed as, P(type I error) = significance level = a, The exact probability of a type II error is generally unknown., If we do not reject the null hypothesis, it may still be false (a type II error) as the, sample may not be big enough to identify the falseness of the null hypothesis (especially, if the truth is very close to hypothesis)., For any given set of data, type I and type II errors are inversely related; the smaller, the risk of one, the higher the risk of the other., A type I error can also be referred to as an error of the first kind., , Type II Error, In a hypothesis test, a type II error occurs when the null hypothesis H0, is not rejected, when it is in fact false. For example, in a clinical trial of a new drug, the null hypothesis, might be that the new drug is no better, on average, than the current drug; i.e., H0: There is no difference between the two drugs on average., A type II error would occur if it was concluded that the two drugs produced the, same effect, i.e., there is no difference between the two drugs on average, when in fact, they produced different ones., A type II error is frequently due to sample sizes being too small., The probability of a type II error is generally unknown, but is symbolised by b and, written, P(type II error) = b, A type II error can also be referred to as an error of the second kind, 52, , Self Learning Material
Page 53 :
2.10 Secondary Data, In research, secondary data is collected and possibly processed by people other than the, researcher in question. Common sources of secondary data for social science include, censuses, large surveys and organizational records. In sociology, primary data is the data, you have collected yourself and secondary data is data you have gathered from primary, sources to create new research. In terms of historical research, these two terms have, different meanings. A primary source is a book or set of archival records. A secondary, source is a summary of a book or set of records., , Sampling and Data, Collection, , Notes, , Secondary data are statistics that already exist. They have been gathered not for, immediate use. This may be described as “those data that have been compiled by some, agency other than the user”. Secondary data can be classified as:, zz Internal, , secondary data, , zz External, , secondary data, , Internal Secondary Data, Internal secondary data is a part of the company’s record, for which research is already, conducted. Internal data are those that are found within the organization, for example,, sales in units, credit outstanding, call reports of sales persons, daily production report,, monthly collection report, etc., , External Secondary Data, The data collected by the researcher from outside the company. This can be divided, into four parts:, zz Census, , data, , zz Individual, zz Data, , project report being published, , collected for sale on a commercial basis is called syndicated data, , zz Miscellaneous, , data, , Census data is the most important data among the sources of data. The following, are some of the data that can be obtained by census records., zz Census, , of the wholesale trade, , zz Census, , of the retail trade, , zz Population, zz Census, , Census, , of manufacturing industries, , zz Individual, , project report being published, , zz Encyclopedia, , of business information sources, , zz Product, , finder, , zz Thomas, , registers etc., Self Learning Material 53
Page 54 :
Research Methodology, , Notes, , Special Techniques of Market Research or Syndicated Data, , 2.11, , These techniques involve data collection on a commercial basis, i.e., data collected by, this method is sold to interested clients on payment. Examples of such organisations are, A.C. Neilson, ORG Marg, IMRB, etc. These organizations provide NRS called National, Readership Survey to the sponsors and advertising agencies. They also provide business, relationship survey called BRS which estimates the following:, 1. Rating, 2. Profile of the company etc., 3. These people also provide TRP rating namely television rating points on a regular, basis. This provides:, (i), , Viewership figures, , (ii), , Duplication between programmes, etc. Some of the interesting studies made, by IMRB are SNAP- Study of Nations Attitude and Awareness Programme., , In this study, the various groups of India’s population and their lifestyles, attitudes, of Indian housewives were detailed., (a) There is also a study called FSRP which covers children in the age group of 10–19, years. Beside their demographics and psychographics, the study covers areas such as:, zz Children, zz Role, , as decision-makers, , models of Indian children, , zz Pocket, , money and its usage, , zz Media, , reviews, , zz Favoured, zz Brand, , personalities and characteristics, , awareness and advertising recall., , Syndicated sources consist of market research firms offering syndicated services., These market research organisations collect and update information on a continuous, basis. Since data is syndicated, its cost is spread over a number of client organisations, and hence is cheaper, for example, a client firm can give certain specific question to be, included in the questionnaire, which is used routinely to collect syndicated data. The client, will have to pay extra charges for these. The data generated from additional questions, and analysis will be revealed only to the firms submitting the questions. Therefore, we, can say that the customization of secondary data is possible. Some areas of syndicated, services are newspapers, periodical readership, popularity of TV channels, etc. Data, from syndicated sources are available on a weekly or monthly basis., Syndicated data may be classified as:, 1. Consumer purchase data, 2. Retailer and wholesaler data, 3. Advertising data., 54, , Self Learning Material
Page 55 :
Most of these data collection methods as mentioned above are also known as, syndicated data. Syndicated data can be classified into:, , Consumer Purchase Data or Panel Type Data, This is one type of syndicated data. In this method, there are consumer panels. Members, of this panel will be representative of the entire population. Panel members keep diaries, in which they record all purchases made by them. Products purchased range from, packaged food to personal care products. Members submit the dairies every month to the, organisations for which they are paid. This panel data can be used to find out the sales, of the product. These panel data also provides an insight into repeat purchases, effect, of free samples, coupon redemption, etc. The consumer panel data also provides profile, of the target audience. Nowadays, diaries are replaced by hand-held scanners. Panels, also provide data on consumer buying habits on petrol, auto parts, sports goods, etc., , Sampling and Data, Collection, , Notes, , Limitations, zz Low-income, , groups are not represented, , zz Some, , people do not want to take the trouble of keeping records of their, purchases., , zz Therefore,, , relevant data is not available., , Advantages, zz Use, , of scanner tied to the central computer helps the panel members to record, their purchases early (almost immediately)., , zz It, , also provides reliability and speed., , zz Panel, , can consist only of senior citizens or only children., , We also have the Consumer Mail Panel (CMP). This consists of members who are, willing to answer mail questionnaires. A large number of such households are kept on, the panel. This serves as a universe through which panels are selected., , Retail and Wholesale Data, Marketing research is done in a retail store. These are organisations that provide, continuous data on grocery products. The procedure does not involve questioning people, and also does not rely on their memory. This requires cooperation from the retailer to, allow auditing to be carried out. Generally, retail audit involves counting of stocks between, two consecutive visits. It involves inspection of goods delivered between visits. If the, stock of any product in the shop is accurately counted during both the visits and data, on deliveries are accurately taken from the records, the collection of sales of a product, over that period can be determined accurately as follows:, Initial stock + Deliveries between successive visits – Second time stock = Sales, Self Learning Material 55
Page 56 :
Research Methodology, , Notes, , If this information is obtained from different shops from the representative sample, of shops, the accurate estimates of sales of the product can be made. To do this, some, shops can be taken as a “Panel of shops” representing the universe., , Advantages, 1. It provides information between audits on consumer purchase over the counter in, specific units. For example, KGs, bottles, No’s etc., 2. It provides data on shop purchases, i.e., the purchases made by the retailer between, audits., 3. The manufacturer comes to know how competitor is doing., 4. It is a very reliable method., , Disadvantages, 1. Experience is needed by the market researcher, 2. Cooperation is required from the retail shop, 3. It is time consuming, , Advertising Data, Since a large amount of money is being spent on advertising, data need to be collected, on advertising. One way of recording is by using passive meter. This is attached to a, TV set records when the set was ‘On’. It will record “How long a channel is viewed”., By this method, data regarding audience interest in a channel can be ascertained. One, thing to be noticed from the above is that it only tells you that someone is viewing, television at home. But it does not tell you “who is viewing at home”. To find out, “who is viewing” a new instrument called ‘People’s Meter’ is introduced. This is a, remote-controlled instrument buttons. Each household is given a specific button. When, that button is pressed, it signals the control box that a specific person is viewing. This, information is recorded electronically and sent to a computer that stores this information, which is subsequently analysed., , Miscellaneous Secondary Data, This data includes trade associations such as FICCI, CEI, Institution of Engineers,, Chamber of Commerce, libraries such as public library, university libraries, etc,, literature, state and central government publications, private sources such as All India, Management Association (AIMA), Financial Express and financial dailies, world bodies, and international organizations such as IMF, ADB, etc., , 2.12, , Advantages and Disadvantages of Secondary Data, , Advantages, 1. It is economical and is available without the need to hire field staff., 56, , Self Learning Material
Page 57 :
2. It saves time; (normally 2 to 3 months). If data is available on hand, it can be, tabulated in minutes., , Sampling and Data, Collection, , 3. It provides information, which retailers may not be willing to reveal to researcher., 4. No training is required to collect this data, unlike primary data., , Notes, , Disadvantages, Because secondary data has been collected for some other projects, it may not fit in with, the problem that is being defined. In some cases, the feed is so poor that the data becomes, completely inappropriate. It may be ill-suited because of the following three reasons:, zz Unit, , of measurement, , zz Definition, , of a class, , zz Recency, , Unit of Measurement, It is common for secondary data to be expressed in units, for example, size of the retail, establishments, for instance, can be expressed in terms of gross sales, profits, square, feet area and number of employees. Consumer incomes can be expressed in variables, the individual, family, household, etc. Secondary data available may not fit in easily., Assume that the class intervals are quite different from those which are needed. For, example, the data available with respect to age group is as follows:, zz <18, , year, , zz 18–24, , years, , zz 25–34, , years, , zz 35–44, , years, , Suppose the company needs a classification less than 20, 20–30 and 30–40, the, above classification of secondary data cannot be used., , Problem of Accuracy, The accuracy of secondary data available is highly questionable. A number of errors are, possible in the collection and analysis of the data. Accuracy of secondary data depends, upon:, 1. Who has collected the data?, 2. How the data was collected?, 1. Who has collected the data: The reliability of the source determines the accuracy, of the data. Assume that a publisher of a private periodical conducts a survey of, his readers. The main aim of the survey is to find out the opinion of readers about, advertisements appearing in it. This survey is done by the publisher in the hope, that other firms will buy this data before inserting advertisements., Self Learning Material 57
Page 58 :
Research Methodology Assume that a professional MR agency has conducted a similar survey and has, sold its syndicated data on many periodicals. If you are an individual who wants, information on a particular periodical you buy, the data from MR agency rather, from the periodical’s publisher. The reason for this is trust of the MR agency. The, Notes, reasons for trusting the MR agency are as follows:, (i), , Being an independent agency, there is no bias. The MR agency is likely to, provide an unbiased data., , (ii), , The data quality of MR agency will be good since they are professionals., , 2. How the data was collected?, (i), , What instruments were used?, , (ii), , What type of sampling was done?, , (iii), , How large was the sample?, , (iv), , What was the time period of data collection? Example: days of the week,, time of the day., , Recency, This pertains to “how old was the information?” If it is five years old, it may be useless., Therefore, the publication lag is a problem., , 2.13, , Primary Data, , The data directly collected by the researcher, with respect to the problem under study, is, known as primary data. Primary data is also the first-hand data collected by the researcher, for the immediate purpose of the study., , 2.14, , Methodology for Collection of Primary Data, , Observation and questioning are two broad approaches available for primary data, collection. The major difference between the two approaches is that in the questioning, process, the respondents play an active role because of their interaction with the researcher., , Observation Method, In the observation method, only present/current behaviour can be studied. Therefore,, many researchers feel that this is a great disadvantage. A causal observation could, enlighten the researcher to identify the problems, such as the length of the queue in, front of a food chain, price and advertising activity of the competitor, etc. Observation, is the least expensive mode of data collection., Example: Suppose a Road Safety Week is observed in a city and the public is made, aware of advance precautions while walking on the road. After one week, an observer, can stand at a street corner and observe the number of people walking on the footpath, 58, , Self Learning Material
Page 59 :
and those walking on the road during a given period of time. This will tell him whether, the campaign on safety is successful or unsuccessful., Sometimes, observation will be the only method available to the researcher., Example: Behaviour or attitude of the children, and also of those who are inarticulate., , Sampling and Data, Collection, , Notes, , Types of Observation Methods, There are several methods of observation of which any one or a combination of some, of them could be used by the observer. Some of these are:, zz Structured, , or unstructured method, , zz Disguised, , or undisguised method, , zz Direct-indirect, , observation, , zz Human-mechanical, , observation, , Structured-Unstructured Observation: Whether the observation should be, structured or unstructured depends on the data needed., , Example 1, A manager of a hotel wants to know “how many of his customers visit the hotel with their, families and how many come as single customers. Here, the observation is structured,, since it is clear “what is to be observed”. He may instruct his waiters to record this., This information is required to decide requirements of the chairs and tables and also, the ambience. Suppose, the manager wants to know how single customers and those, with families behave and what their attitudes are like. This study is vague, and it needs, a non-structured observation., It is easier to record structured observation than non-structured observation., , Example 2, To distinguish between structured and unstructured observations, consider a study,, investigating the amount of search that goes into the purchase of a soap cake. On the, one hand, the observers could be instructed to stand at one end of a supermarket and, record each sample customer’s search. This may be observed and recorded as follows:, “The purchaser first paused after looking at HLL brand. He looked at the price of the, product, kept the product back on the shelf, then picked up a soap cake of HLL and, glanced at the picture on the pack and its list of ingredients, and kept it back. He then, checked the label and price for P&G product, kept that back down again, and after a, slight pause, picked up a different flavour soap of M/s. Godrej Company and placed it, in his trolley and moved down the aisle”. On the other hand, observers might simply, be told to record the “first soap cake examined”, by checking the appropriate boxes in, the observation form. The ‘second situation’ represents more structured than the first., Self Learning Material 59
Page 60 :
Research Methodology, , Notes, , To use a more structured approach, it would be necessary to decide precisely what, is to be observed and the specific categories and units that would be used to record the, observations., Disguised-Undisguised Observation: In disguised observation, the respondents do, not know that they are being observed. In non-disguised observation, the respondents, are well aware that they are being observed. In disguised observation, observers often, pose as shoppers. They are known as “mystery shoppers”. They are paid by research, organisations. The main strength of disguised observation is that it allows for registering, the true of the individuals. In the undisguised method, observations may be restrained, due to induced error by the objects of observation. The ethical aspect of disguised, observations is still open to question and debate., Direct-Indirect Observation: In direct observation, the actual behaviour or, phenomenon of interest is observed. In indirect observation, the results of the consequences, of the phenomenon are observed. Suppose, a researcher is interested in knowing about, the soft drink’s consumption by a student in a hostel room. He may like to observe empty, soft drink bottles dropped into the bin. Similarly, the observer may seek the permission, of the hotel owner to visit the kitchen or stores. He may carry out a kitchen/stores audit,, to find out the consumption of various brands of spice items being used by the hotel. It, may be noted that the success of an indirect observation largely depends on “how best, the observer is able to identify physical evidence of the problem under study”., Human-Mechanical Observation: Most of the studies in marketing research are, based on human observation, wherein trained observers are required to observe and, record their observation. In some cases, mechanical devices such as eye cameras are, used for observation. One of the major advantages of electrical/mechanical devices is, that their recordings are free from any subjective bias., , Advantages of Observation Method, 1. The original data can be collected at the time of occurrence of the event., 2. Observation is done in natural surroundings. Therefore, the facts emerge more, clearly, whereas in a questionnaire, experiments have environmental as well as, time constraints., 3. Sometimes, the respondents may not like to part with some of the information. Such, information can be obtained by the researcher through observation., 4. Observation can also be done on those who cannot articulate., 5. Any bias on the part of the researcher is greatly reduced in the observation method., , Limitations of Observation Method, 1. The observer might wait for longer period at the point of observation. And yet the, desired event may not take place. Observation is required over a long period of, time and hence may not occur., 60, , Self Learning Material
Page 61 :
2. For observation, an extensive training of observers is required., 3. This is an expensive method., 4. External observation provides only superficial indications. To delve beneath the, surface is very difficult. Only overt behaviour can be observed., 5. Two observers may observe the same event, but may draw different inferences., , Sampling and Data, Collection, , Notes, , 6. It is very difficult to gather information on (1) Opinions (2) Intentions., , Designing the Questionnaire, Questionnaire: A questionnaire is a tool used to collect the data., Importance of Questionnaire in MR: To study:, 1. Behaviour, past and present., 2. Demographic characteristics such as age, sex, income and occupation., 3. Attitudes and opinions., 4. Level of knowledge., , Characteristics of Questionnaire, 1. It must be simple. The respondents should be able to understand the questions., 2. It must generate replies that can be easily be recorded by the interviewer., 3. It should be specific, so as to allow the interviewer to keep the interview to the point., 4. It should be well arranged, to facilitate analysis and interpretation., 5. It must keep the respondent interested throughout., , Different Types of Questionnaire, 1. Structured and Non-disguised, 2. Structured and Disguised, 3. Non-structured and Disguised, 4. Non-structured and Non-disguised, 1. Structured and Non-disguised Questionnaire: Here, questions are structured so, as to obtain the facts. The interviewer will ask the questions strictly in accordance, with the pre-arranged order. For example: What are the strengths of soap A in, comparison with soap B?, (i), , Cost is less, , (ii), , Lasts longer, , (iii), , Better fragrance, , (iv), , Produces more lather, , (v), , Available in more convenient sizes, , Structured and non-disguised questionnaire is widely used in market research., Questions are presented with exactly the same wording and same order to all, Self Learning Material 61
Page 62 :
Research Methodology, , respondents. The reason for standardizing the question is to ensure that all, respondents reply the same question. The purpose of the question is clear. The, researcher wants the respondent to choose one of the five options given above., This type of questionnaire is easy to administer. The respondents have no difficulty, in answering, because it is structured, the frame of reference is obvious. In a nondisguised type, the purpose of the questionnaire is known to the respondent., , Notes, , Example: “Subjects attitude towards Cyber laws and the need for government, legislation to regulate it”., (i), , Certainly, not needed at present, , (ii), , Certainly not needed, , (iii), , I can’t say, , (iv), , Very urgently needed, , (v), , Not urgently needed, , If a radio manufacturer wanted to find out how many people own a radio, what, type it is, when they bought it, the respondents could be asked a set of questions, in the following given sequence., Does your family own a radio? Yes/No, (If yes, ask), What brand is it? Name ..................................., How many valves? Number ..................................., When did you purchase this radio? Date ..................................., This is an example of structured and non-disguised study., 2. Structured and disguised Questionnaire: This type of questionnaire is least used in, marketing research. This type of questionnaire is used to know the peoples’ attitude,, when a direct undisguised question produces a bias. In this type of questionnaire,, what comes out is “what does the respondent know” rather than what he feels., Therefore, the endeavour in this method is to know the respondent’s attitude., Currently, the “Office of Profit” Bill is:, (i), , In the Lok Sabha for approval., , (ii), , Approved by the Lok Sabha and pending in the Rajya Sabha., , (iii), , Passed by both the Houses, pending the presidential approval., , (iv), , The bill is being passed by the President., , Depending on which answer the respondent chooses, his knowledge on the subject, is classified., In a disguised type, the respondent is not informed of the purpose of the, questionnaire. Here the purpose is to hide “what is expected from the respondent?”, 62, , Self Learning Material
Page 63 :
Example 1: “Tell me your opinion about Mr. Ben’s healing effect show conducted, in Bangalore?”, , Sampling and Data, Collection, , Example 2: “What do you think about the Babri Masjid demolition?”, 3. Non-structured and Disguised Questionnaire: The main objective is to conceal the, topic of enquiry by using a disguised stimulus. Though the stimulus is standardized, by the researcher, the respondent is allowed to answer in an unstructured manner., The assumption made here is that individual’s reaction is an indication of, respondent’s basic perception. Projective techniques are examples of non-structured, disguised technique. The techniques involve the use of a vague stimulus, which, an individual is asked to expand or describe or build a story, three common types, under this category are (a) Word association (b) Sentence completion (c) Story, telling., , Notes, , 4. Non-structured and Non-disguised Questionnaire: Here the purpose of the study, is clear, but the responses to the question are open-ended. Example: “How do you, feel about the Cyber law currently in practice and its need for further modification”?, The initial part of the question is consistent. After presenting the initial question,, the interview becomes much unstructured as the interviewer probes more deeply., Subsequent answers by the respondents determine the direction the interviewer, takes next. The question asked by the interviewer varies from person to person., This method is called “the depth interview”. The major advantage of this method, is the freedom permitted to the interviewer. By not restricting the respondents to, a set of replies, the experienced interviewers will be able to get the information, from the respondent fairly and accurately. The main disadvantage of this method of, interviewing is that it takes time, and the respondents may not co-operate. Another, disadvantage is that coding of open-ended questions may pose a challenge. For, example: When a researcher asks the respondent “Tell me something about your, experience in this hospital”. The answer may be “Well, the nurses are slow to attend, and the doctor is rude. ‘Slow’ and ‘rude’ are different qualities needing separate, coding. This type of interviewing is extremely helpful in exploratory studies., , Table 2.1: Types of Questionnaires, 1. Structured and Nondisguised, , Questions are presented with exactly the same, wording and same order to all respondents., , 2. Structured and Disguised, , This type of questionnaire is used to know the, peoples’ attitude, when a direct undisguised, question produces a bias., , 3. Non-structured and, Disguised, , The main objective is to conceal the topic of, enquiry by using a disguised stimulus., , 4. Non-structured and Nondisguised, , Here the purpose of the study is clear, but the, responses to the question are open-ended., Self Learning Material 63
Page 64 :
Research Methodology Process of Questionnaire Designing, Questionnaire designing is a skillful task. It requires a series of steps to be followed., Given below are the main steps involved in the process of questionnaire designing., , Notes, , The following are the seven steps:, , Determine What Information is Required, The first question to be asked by the market researcher is “what type of information, does he need from the survey?” This is valid because if he omits some information on, relevant and vital aspects, his research is not likely to be successful. On the other hand,, if he collects information which is not relevant, he is wasting his time and money., At this stage, information required, and the scope of research should be clear., Therefore, the steps to be followed at the planning stage are:, 1. Decide on the topic for research., 2. Get additional information on the research issue, from secondary data and, exploratory research. The exploratory research will suggest “what are the relevant, variables?”, 3. Gather what has been the experience with similar study., 4. The type of information required. There are several types of information such as, (a) awareness, (b) facts, (c) opinions, (d) attitudes, (e) future plans, (f) reasons., Facts are usually sought out in marketing research., �Example: Which television programme did you see last Saturday? This requires, a reasonably good memory and the respondent may not remember. This is known, as recall loss. Therefore, questioning the distant past should be avoided. Memory, of events depends on (1) Importance of the events and (2) Whether it is necessary, for the respondent to remember. In the above case, both the factors are not fulfilled., Therefore, the respondent does not remember. On the other hand, a birthday or, wedding anniversary of individuals is remembered without effort since the event, is important. Therefore, the researcher should be careful while asking questions, about the past., First, he must make sure that the respondent has the answer., �, Example: Do you go to the club? He may answer ‘yes’, though it is untrue., This may be because the respondent wants to impress upon the interviewer that, he belongs to a well-to-do family and can afford to spend money on clubs. To, obtain facts, the respondents must be conditioned (by good support) to part with, the correct facts., , Mode of Collecting the Data Primary Data, The questionnaire can be used to collect information either through personal interview,, mail or telephone. The method chosen depends on the information required and also, 64, , Self Learning Material
Page 65 :
the type of respondent. If the information is to be collected from illiterate individuals,, a questionnaire would be the wrong choice., , Type of Questions, Open-ended Questions: These are the questions where respondents are free to answer, in their own words, for example, “What factor do you consider while buying a suit”?, If multiple choices are given, it could be colour, price, style, brand, etc., but some, respondents may mention attributes which may not occur to the researcher. Therefore,, open-ended questions are useful in exploratory research, where all possible alternatives, are explored. The greatest disadvantage of open-ended questions is that the researcher, has to note down the answer of the respondents verbatim. Therefore, there is a likelihood, of the researcher failing to record some information. Another problem with open-ended, question is that the respondents may not use the same frame of reference., , Sampling and Data, Collection, , Notes, , Example: “What is the most important attribute in a job?”, Ans: Pay, The respondent may have meant “basic pay” but interviewer may think that the, respondent is talking about “total pay including dearness allowance and incentive”. Since, both of them refer to pay, it is impossible to separate two different frames. Dichotomous, Question: These questions have only two answers, ‘Yes’ or ‘no’, ‘true’ or ‘false’ ‘use’, or ‘don’t use’., Do you use toothpaste? Yes ……….. No …………, There is no third answer. However sometimes, there can be a third answer: Example:, “Do you like to watch movies?”, Ans: Neither like nor dislike, Dichotomous questions are most convenient and easy to answer. A major, disadvantage of dichotomous question is that it limits the respondent’s response. This, may lead to measurement error., Close-ended Questions: There are two basic formats in this type:, 1. Make one or more choices among the alternatives, 2. Rate the alternatives, , Choice among Alternatives, Which of the following words or phrases best describes the kind of person you feel would, be most likely to use this product, based on what you have seen in the commercial?, 1. Young ………… old ……………., Single ………… Married ……….., Modern ………… Old fashioned …………(b) Rating Scale, (I) Please, tell us your overall reaction to this commercial?, Self Learning Material 65
Page 66 :
Research Methodology, , Notes, , (i), , A great commercial would like to see again., , (ii), , Just so-so, like other commercials., , (iii), , Another bad commercial., , (iv), , Pretty good commercial., , �(II) Based on what you saw in the commercial, how interested do you feel, you would, be buying the products?, (i), , Definitely, , (ii), , Probably, I would buy., , (iii), , I may or may not buy., , (iv), , Probably, I would not buy., , (v), , Definitely, I would not buy., , Closed-ended questionnaires are easy to answer. It requires less effort on the part of, the interviewer. Tabulation and analysis is easier. There are lesser errors, since the same, questions are asked to everyone. The time taken to respond is lesser. We can compare, the answer of one respondent with that of another respondent., One basic criticism of closed-ended questionnaires is that middle alternatives are, not included in this, such as “don’t know”. This will force the respondents to choose, among the given alternatives., , Wordings of Questions, Wordings of particular questions could have a large impact on how the respondent, interprets them. Even a small shift in the wording could alter the respondent’s answer., Example 1: “Don’t you think that Brazil played poorly in the FIFA cup?” The, answer will be ‘yes’. Many of them, who do not have any idea about the game, will, also say ‘yes’. If the question is worded in a slightly different manner, the response, will be different., Example 2: “Do you think that, Brazil played poorly in the FIFA cup?” This is a, straightforward question. The answer could be ‘yes’, ‘no’ or ‘don’t know’ depending, on the knowledge the respondents have about the game., Example 3: “Do you think anything should be done to make it easier for people, to pay their phone bill, electricity bill and water bill under one roof”?, Example 4: “Don’t you think something might be done to make it easier for people, to pay their phone bill, electricity bill, water bill under one roof”?, A change of just one word as above can generate different responses by respondents., , Guidelines Towards the Use of Correct Wording, zz Is, , 66, , Self Learning Material, , the vocabulary simple and familiar to the respondents?
Page 67 :
Example 5: Instead of using the word ‘reasonably’, ‘usually’, ‘occasionally’,, ‘generally’, ‘on the whole’., , Sampling and Data, Collection, , Example 6: “How often do you go to a movie?” “Often, may be once a week,, once a month, once in two months or even more.”, zz Avoid, , Double-Barreled Questions, , Notes, , These are questions, in which the respondent can agree with one part of the question,, but not agree with the other or cannot answer without making a particular assumption., Example 1: “Do you feel that firms today are employee-oriented and customer, oriented?”, There are two separate issues here – [yes] [no], Example 2: “Are you happy with the price and quality of branded shampoo?”, [yes] [no], zz Avoid, , Leading and Loading Questions, , Leading Questions, A leading question is one that suggests the answer to the respondent. The question itself, will influence the answer, when respondents get an idea that the data is being collected, by a company. The respondents have a tendency to respond positively., Example 1: “How do you like the programme on ‘Radio Mirchy’? The answer is, likely to be ‘yes’. The unbiased way of asking is “which is your favorite F.M. Radio, station? The answer could be any one of the four stations namely (1) Radio City (2), Mirchy (3) Rainbow (4) Radio-One., Example 2: Do you think that offshore drilling for oil is environmentally unsound?, The most probable response is ‘yes’. The same question can be modified to eliminate, the leading factor., What is your feeling about the environmental impact of offshore drilling for oil?, Give choices as follows:, zz Offshore, , drilling is environmentally sound., , zz Offshore, , drilling is environmentally unsound., , zz No, , opinion., , Loaded Questions, A leading question is also known as a loaded question. In a loaded question, special, emphasis is given to a word or a phrase, which acts as a lead to respondent. Example:, “Do you own a Kelvinator refrigerator.” A better question would be “what brand of, refrigerator do you own?” “Don’t you think the civic body is ‘incompetent’?” Here the, word incompetent is ‘loaded’., Self Learning Material 67
Page 68 :
Research Methodology Are the Questions Confusing?, , Notes, , If there is a question unclear or is confusing, the respondent becomes more biased rather, than getting enlightened. Example: “Do you think that the government publications are, distributed effectively”? This is not the correct way, since respondent does not know the, meaning of the word effective distribution. This is confusing. The correct way of asking, questions is “Do you think that the government publications are readily available when, you want to buy?” Example: “Do you think whether value price equation is attractive”?, Here, respondents may not know the meaning of value price equation., , Applicability, “Is the question applicable to all respondents?” Respondents may try to answer a question, even though they don’t qualify to do so or may lack from any meaningful opinion., Examples: (1) “What is your present education level” (2) “Where are you working”, (assuming he is employed)? (3) “From which bank have you taken a housing loan”, (assuming he has taken a loan)., , Avoid Implicit Assumptions, An implicit alternative is one that is not expressed in the options. Consider following, two questions:, zz Would, , you like to have a job, if available?, , zz Would, , you prefer to have a job, or do you prefer to do just domestic work?, , Even though, we may say that these two questions look similar, they vary widely., The difference is that Q-2 makes explicit the alternative implied in Q-1., , Split Ballot Technique, This is a procedure used wherein (1) The question is split into two halves and (2), Different sequencing of questions is administered to each half. There are occasions, when a single version of questions may not derive the correct answer and the choice is, not obvious to the respondent., Example: “Why do you use Ayurvedic soap”? One respondent might say “Ayurvedic soap, is better for skin care”. Another may say “Because the dermatologist has recommended”., A third might say “It is a soap used by my entire family for several years”. The first, respondent answers the reason for using it at present. The second respondent answers, how he started using and the third respondent cited the reason as “the family tradition, for using”. As can be seen, different reference frames are used. The question may be, balanced and rephrased., , Complex Questions, In which of the following do you like to park your liquid funds?, zz Debenture, , 68, , Self Learning Material
Page 69 :
zz Preferential, zz Equity, , share, , linked M.F, , Sampling and Data, Collection, , zz I.P.O, zz Fixed, , deposit, , Notes, , If this question is posed to the general public, they may not know the meaning of, liquid fund. Most of the respondents will guess and tick one of them., , Are the Questions too Long?, Generally as a thumb rule, it is advisable to keep the number of words in a question not, exceeding 20. The question given below is too long for the respondent to comprehend,, leave alone answer., Example: Do you accept that the people whom you know, and associate yourself, have been receiving ESI and P.F benefits from the government accept a reduction in, those benefits, with a view to cutting down government expenditure, to provide more, resources for infrastructural development?, Yes _________ No_________ Can’t say_________, , Participation at the Expense of Accuracy, Sometimes the respondent may not have the information that is needed by the researcher., Example 1: The husband is asked a question “How much does your family spend, on groceries in a week”? Unless the respondent does the grocery shopping himself, he, will not know how much has been spent. In a situation like this, it will be helpful to, groceries in your family”?, Example 2: “Do you have the information of Mr. Ben’s visit to Bangalore”? Not, only should the individual have the information but also s(he) should remember the, same. The inability to remember the information is known as “recall loss”., , Sequence and Layout, Some guidelines for sequencing the questionnaire are as follows:, Divide the questionnaire into three parts:, (1) Basic information, (2) Classification, and (3) Identification information. Items, such as age, sex, income, education, etc., are questioned in the classification section., The identification part involves body of the questionnaire. Always move from general, to specific questions on the topic. This is known as funnel sequence. Sequencing of, questions is illustrated below:, 1. Which TV shows do you watch?, Sports _________ News_________, Self Learning Material 69
Page 70 :
Research Methodology, , 2. Which among the following are you most interested in?, Sports _________ News_________, Music _________ Cartoon_________, , Notes, , 3. Which show did you watch last week?, World Cup Football_________, Bournvita Quiz Contest_________, War News in the Middle East _________, Tom and Jerry cartoon show_________, The above three questions follow a funnel sequence. If we reverse the order of, question and ask “which show was watched last week”? The answer may be biased., This example shows the importance of sequencing., Layout: How the questionnaire looks or appears., Example: Clear instructions, gaps between questions, answers and spaces are part, of layout. Two different layouts are shown below:, Layout 1: How old is your bike?, _____Less than 1 year _____1 to 2 years _____2 to 4 years _____ more than 4 years., Layout 2: How old is your bike?, ______Less than 1 year, ______1 to 2 years., ______2 to 4 years., ______ More than 4 years., From the above example, it is clear that layout – 2 is better. This is because likely, respondent’s error due to confusion is minimised., Therefore, while preparing a questionnaire start with a general question. This is, followed by a direct and simple question. This is followed by more focused questions., This will elicit maximum information., , Forced and Unforced Scales, Suppose the questionnaire is not provided with ‘don’t know’ or ‘no option’, then the, respondent is forced to choose one side or the other. A ‘don’t know’ is not a neutral, response. This may be due to genuine lack of knowledge., , Balanced and Unbalanced Scales, In a balanced scale, the number of favourable responses is equal to the number of, unfavorable responses. If the researcher knows that there is a possibility of a favourable, response, it is best to use unbalanced scale., 70, , Self Learning Material
Page 71 :
Use Funnel Approach, Funnel sequencing gets the name from its shape, starting with broad questions and, progressively narrowing down the scope. Move from general to specific examples., 1. How do you think this country is getting along in its relations with other countries?, 2. How do you think we are doing in our relations with the US?, , Sampling and Data, Collection, , Notes, , 3. Do you think we ought to be dealing with US?, 4. If yes, what should be done differently?, 5. Some say we are very weak on the nuclear deal with the US, while, some say we, are OK. What do you feel?, The first question introduces the general subject. In the next question, a specific, country is mentioned. The third and fourth questions are asked to seek views. The fifth, question is to seek a specific opinion., , Pre-testing of Questionnaire, Pre-testing of a questionnaire is done to detect any flaws that might be present. For, example, the word used by researcher must convey the same meaning to the respondents., Are instructions clear and skip questions clear? One of the prime conditions for pretesting is that the sample chosen for pre-testing should be similar to the respondents, who are ultimately going to participate. Just because a few chosen respondents fill in, all the questions going does not mean that the questionnaire is sound., , How Many Questions to be Asked?, The questionnaire should not be too long as the response will be poor. There is no rule, to decide this. However, the researcher should consider that if he were the respondent,, how he would react to a lengthy questionnaire. One way of deciding the length of the, questionnaire is to calculate the time taken to complete the questionnaire. He can give, the questionnaire to a few known people to seek their opinion., , Mail Questionnaire, Advantages of Mail Questionnaire, 1. Easier to reach a larger number of respondents throughout the country., 2. Since the interviewer is not present face to face, the influence of interviewer on, the respondent is eliminated., 3. Where the questions asked are such that they cannot be answered immediately, and, needs some thinking on the part of the respondent, the respondent can think over, leisurely and give the answer., 4. Saves cost (cheaper than interview)., 5. No need to train interviewers., 6. Personal and sensitive questions are well answered., Self Learning Material 71
Page 72 :
Research Methodology Limitations of Mail Questionnaire, 1. It is not suitable when questions are difficult and complicated. Example: “Do you, believe in value price relationship”?, , Notes, , 2. When the researcher is interested in a spontaneous response, this method is, unsuitable. Because thinking time allowed to the respondent will influence the, answer. Example: “Tell me spontaneously, what comes to your mind if I ask you, about cigarette smoking”., 3. In case of a mail questionnaire, it is not possible to verify whether the respondent, himself/herself has filled the questionnaire. If the questionnaire is directed towards, housewives, say, to know their expenditure on kitchen items, they alone are supposed, to answer it. Instead, if their husband answer the questionnaire, the answers may, not be correct., 4. Any clarification required by the respondent regarding questions is not possible., Example: Prorated discount, product profile, marginal rate, etc., may not be, understood by the respondents., 5. If the answers are not correct, the researcher cannot probe further., 6. Poor response (30%) – Not all reply., Additional Consideration for the Preparation of Mail Questionnaire, 1. It should be shorter than the questionnaire used for a personal interview., 2. The wording should be extremely simple., 3. If a lengthy questionnaire has to be made, first write a letter requesting the, cooperation of the respondents., 4. Provide clear guidance, wherever necessary., 5. Send a pre-addressed and stamped envelope to receive the reply., , Sample Questionnaires, A Study of Customer Retention as Adopted by Textile Retail Outlets, Note: Information gathered will be strictly confidential. We highly appreciate your, cooperation in this regard., 1. Name of the outlet:, 2. Address:, 3. Do you have regular customers?, Yes [ ] No [ ], 4. How often do your regular customers visit your outlet?, Weekly [ ] Once in a month [ ] Twice in a month [ ], Once in 2 months [ ] 2 – 3 months [ ] Once in 6 months [ ], 72, , Self Learning Material
Page 73 :
5. Do you maintain any records of your regular customers?, Yes [ ] No [ ], , Sampling and Data, Collection, , 6. What percentage of your customers is regular? % [ ], 7. Do you think that we can use the above as a retention strategy of customers for, your outlets?, , Notes, , Yes [ ] No [ ], 8. What are the different products that you handle in your outlets?, Formals [ ] Casuals/Kids wear [ ] Ladies dress materials [ ], Sarees [ ] Others (Specify), 9. What type of customers (socio-economic) visit your outlets?, Low income [ ] Middle income [ ] High income [ ], 10. Why do you think they come to your outlet?, Product variety [ ] Price discount [ ] Easy gain to products [ ], Parking facility [ ] Store layout [ ] Quality [ ], Reasonable price [ ] Others (Specify), 11. Rank the factors that influence customers to visit your outlet:, Credit facility [ ] Price discount [ ] Gifts [ ], Easy gain to products [ ] Parking facility [ ] Store layout [ ], Product variety [ ] Quality and reasonable price [ ], Others (Specify) ———————, 12. What do customers expect from the retail outlet?, Credit facility [ ] Gift coupon [ ] Price discount [ ], Price reduction easy accessibility of product [ ] Quality and reasonable price [ ], Others (Specify) ————————13. Do you have any retention strategy adopted to keep in touch with the customer?, Gifts on special occasion, Birthday gift [ ] Anniversary gift [ ], Festivals/Customer relationship [ ] Others (Specify) —————————, 14. Which one do you think is most effective? Please rank them?, Birthday gift [ ] Anniversary gift [ ], Festivals/Customer relationship [ ] Others (Specify) —————————, , Thanking You for Sparing Your Valuable Time, A Study on Customer Preferences of P.C., Date: Place:, Self Learning Material 73
Page 74 :
Research Methodology Form No: [ ] [ ] [ ] [ ] [ ], 1. Personal Profile, , Notes, , (i), , Name: [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ], , (ii), , Address: [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ], [][][][][][][][][][][][][][][][][], [][][][][][][][][][][][][][][][][], , (iii), , Sex: Male [ ] Female [ ], , (iv), , Age: [ ] [ ] years, , (v), , Occupation: Self-employed [ ] Professional [ ] Service [ ] Housewife [ ], , 2. Do you own a P.C? Yes [ ] No [ ], (i), , If yes, whether: branded [ ] unbranded [ ], , (ii), , If no, do you plan to buy one? Near future [ ] Distant future [ ] Can’t say [ ], (Less than 6 months) (Less than a year), If so, whether: branded [ ] unbranded [ ], , 3. What is the utility of the PC to you?, Education [ ] Business [ ] Infotainment [ ] Internet/Communication [ ], 4. What is the most important factor that matters while buying a PC?, Quality [ ] Price [ ] Service [ ] Finance facility [ ], 5. Before deciding on the vendor, which factor goes into your consideration?, Vendor’s Reputation [ ] Technical Expertise [ ] Client Base [ ], 6. How did you come to know about the vendor?, Friendly / Family [ ] Press/Ads[ ] Direct Mailers [ ] Reference Website [ ], 7. Which configuration would you decide on while buying a PC?, Standard [ ] Intermediate [ ] Latest/Advanced [ ], 8. In your PC, would you prefer? Conventional Design [ ] Innovative Design [ ], If new, why: New design distracts attention New design means increased price New design is hard to adapt If Innovative, why? To create own identity, Out of business need Space management 9. Rate the following four factors important for innovative design, starting with the, most preferred:, 74, , Self Learning Material
Page 75 :
(A) Size (B) Shape (C) Colour/Ordinary (D) Portability and Sturdiness, 1. ————————————— 3. ———————————, 2. ————————————— 4. ———————————, 10. To what extent would the computer increase your efficiency?, , Sampling and Data, Collection, , Notes, , Negligible [ ] 20 – 40% [ ] 40 – 60% [ ] More [ ], 11. How many hours on an average per week would you use your PC?, 0 to 5 hours [ ] 6 to 12 hours [ ] 13 to 18 hours [ ] More [ ], 12. While using your PC, most of the time would be for:, Education [ ] Accounting [ ] Net surfing [ ] Correspondence [ ], 13. Remarks ———————————————————————————, ——————————————————————————————, ———————————————————————————————, Signature of the Respondent ——————————-, , 2.15 Qualitative Versus Quantitative Research, These two research methods vary in a number of ways. They vary in terms of, 1. Measurability criteria, 2. Features, 3. Characteristics, , Quantitative Research, Measurability: Quantitative data is measurable, for example; size of market, rate of, product usage, etc., Features, 1. Data collected is numerical in nature., 2. Data collection methods are, (iii), , Mail questionnaire, , (iv), , Personal interview, , (v), , Telephonic interview, , Characteristics, 1. Sample size used is very large., 2. Structured questionnaire is used for data collection., Self Learning Material 75
Page 76 :
Research Methodology Qualitative Research, Measurability: Not possible or difficult to measure., Features: It is a kind of exploratory research., , Notes, , Characteristics:, 1. Unstructured questionnaire is used., 2. Sample size is usually small., There are four major techniques in Qualitative Research. They are:, 1. Depth Interview, 2. Delphi Technique, 3. Focus Group, 4. Projective Technique, 1. Depth Interview: Unstructured, direct interview is known as a depth interview., Here the interviewer will continue to ask probing questions of like, “What did you, mean by that statement?”, “Why did you feel this way?” and “What other reasons, do you have?” etc., until he is satisfied that he has obtained the information he, wants. The unstructured interview is free from restrictions imposed by a formal list, of questions. The interview may be conducted in a casual and informal manner in, which the flow of the conversation determines what questions are to be asked and, the order in which they should be asked., Advantages, (i), , The primary advantage of the depth interview technique is its ability to, discover motivations. Marketing decisions like the choice of product,, methods of selling and advertising appeals, etc., must be decided only after, receiving feedback from consumer., , (ii), , The second advantage of the depth interview procedure is that it encourages, respondents to express any ideas they have., , (iii), , The third advantage is that it provides a lot of flexibility to the interviewer. We, have a two-way communication where both interviewer and the interviewee, contribute to the knowledge gained., , Limitations, , 76, , Self Learning Material, , (i), , There are number of weaknesses in the depth interviewing approach. First,, depth interview takes much longer than a typical structured questionnaire, filling. It may lead to respondent fatigue and hence may lead to biased, response., , (ii), , The second weakness of the depth interview is the lack of systematic, structure for interpretation of the information obtained. This requires a
Page 77 :
trained psychoanalyst. It is difficult to find the qualified and trained people, for conducting depth interview., (iii), , Another difficulty is that no quantifiable data is obtained in the depth, interviewing process. This means that human judgement is involved in, summarizing the findings. Different results will often be obtained by different, people in the same situation. As a result, there is little or no opportunity for, verification. Flexibility on the part of the interviewer is sometimes a major, weakness., , Sampling and Data, Collection, , Notes, , 2. Delphi Technique: This is a process where a group of experts in the field gather., They may have to reach a consensus on forecasts. Sometimes, the judgement may, be made by some group members who have strong personalities. In the Delphi, approach, the group members are asked to make individual judgements about a, particular subject, say ‘sales forecast’. These judgements are compiled and returned, to the group members, so that they can compare their previous judgement with those, of others. Then they are given an opportunity to revise their judgements, especially, if it differs from the others. They can say why their judgement is accurate, even if, it differs, from that of the other group members. After 5 to 6 rounds of interaction,, the group members reach conclusion., 3. Focus Group Interview: They are the best known and most widely used type of, indirect interviews. Here, a group of people jointly participate in an unstructured, indirect interview conducted by a moderator. The group usually consists of six, to ten people. In general, the selected persons have similar backgrounds. The, moderator attempts to focus the discussion on the problem areas. Focus groups, are used primarily to provide background information and to generate hypothesis, rather than to provide solution to problems. The areas of application include:, (i), , Development of new product concept., , (ii), , The generation of ideas for improving established products., , (iii), , Development of creative concepts in advertising., , �An example of the use of the focus group technique in the development of, advertising may be looked at. Assume that company X wants to introduce, electrical cars. Just prior to the introduction of the new car, the company conducts, two focus group interviews to see “what is the dealers’ perception about key, benefits of the new type of car?” Assume that previous research indicated the, customers would buy the new car, provided they were less expensive than the, conventional cars. Since the new car was priced lower than price of a conventional, car, the company expected no problems with the dealers accepting the new car., Instead, the focus group interviews found that the dealers were doubtful about, the acceptance of electrical car in the Indian market, since it is new, despite the, Self Learning Material 77
Page 78 :
Research Methodology, , fact that it is cheaper than regular car. Customers were concerned about charging, mode, facilities for doing so, battery life and above all, newness of the concept., Advantages, , Notes, , (i), , This technique provides more sophisticated data because of the interaction, among different members of the group., , (ii), , It also offers other benefits of depth interviews and offers in addition the, advantages of saving cost, time and resources during data collection stage., , Disadvantages, (i), , As the samples are small and invariably non-probabilistic, extrapolation, offending is not permitted., , (ii), , Responses of individual members are not independent, and are influenced, by what others have to say. Some respondents dominate the proceeding, and try to force their opinion on others and some are very shy or nervous,, and have very little or nothing to say, though they may feel strongly on the, subject. The results of group interviews are difficult to quantify since they, are unstructured., , (iii), , The key component of a successful focus group interview is the skill of, the group moderator (interviewer). By carefully guiding the discussion,, avoiding dominance by a few group members and keeping the discussion, focused on the topic of interest, a moderator can obtain valuable data from, the participants., , 4. Indirect Interviews: The direct questioning of respondents may not yield the desired, results, because the respondent is usually unable and unwilling to give accurate, answers often to direct questions. To solve this, a number of techniques have been, devised to obtain information by indirect means. Most of the interviewing techniques, employ the principle of projection. That is, the respondent is given a non-personal,, ambiguous situation and is required to respond. These techniques include the word, association, sentence completion tests, interpretation of pictorial representation and, other devices– that have been developed as means of inducing people to project, their feelings. They have been most widely used for finding out attitude towards, products, such as automobiles,soaps and detergents, cigarettes, food products and, beverages. Indirect interviews are commonly referred to as projective techniques., 5. Projective Techniques: Projective techniques (Indirect method of gathering, information/indirect interview) are unstructured and involve indirect form of, questioning., I� n projective techniques, respondents are asked to interpret the behaviour of users,, rather than describe their own behaviour. In interpreting the behaviour of others,, respondents indirectly project their own motivation and feelings into the situation., 78, , Self Learning Material
Page 79 :
Example: Many a time, people do not want to reveal their true motive for fear of, being branded ‘old fashioned’. Questions such as “Do you do all household work, yourself?” The answer may be ‘no’, though the truth is ‘yes’. A ‘yes’ answer may, not be given because it may suggest that the family is not financially sound and, cannot afford a maid for help., , Sampling and Data, Collection, , Notes, , Two types of projective techniques are available:, (i), , An ambiguous stimulus is presented to respondents., , (ii), , In reacting to the stimulus, the respondents will indirectly reveal their own, feeling., , The general categories of projective techniques are:, 1. Word association test, 2. Completion technique, 3. TAT and, 4. Cartoon test, 1. Word Association Test: This test consists of presenting a series of stimulus words, to the respondent, who is asked to answer quickly with the first word that comes, to his mind. The respondent, by answering quickly, gives the word that s(he) or, she associates most closely with the stimulus word., �Example 1: What brand of detergent comes to your mind first, when I mention, washing of an expensive cloth?, (i), , Surf, , (ii), , Tide, , (iii), , Key, , (iv), , Ariel, , Example 2: Who drinks the milk most?, (i), , Athletes, , (ii), , Young boys, , (iii), , Adults, , (iv), , Children, , �Example 3: In a study of cigarettes, the respondent is asked to give the first word that, comes to his mind., (i), , Injurious, , (ii), , Style, , (iii), , Strong, , (iv), , Stimulus, , (v), , Bad manners, Self Learning Material 79
Page 80 :
Research Methodology, , (vi), , Disease, , (vii) Pleasure, 2. Completion Techniques, , Notes, , (i), , Sentence completion, , (ii), , Story completion, , (i), , Sentence Completion: Here the respondents have to finish a set of incomplete, sentences. Example: Let us make a study dealing with people’s inner feelings, towards software professionals., (p), , Earnings of a software professional ……………, , (q), , Being software professional means ……………, , (r), , Working hours for software professional are ……………, , (s), , The personal life of software professional is ……………, , (t), , The social status of software professional is ……………, , Suppose you want to study the attitude towards a periodical:, (a), , A person who reads Women’s Era periodical is ……………., , (b), , Business World periodical appeals to …………….., , (c), , Outlook periodical is read by ……………., , (d), , Investor periodical is mostly liked by ……………., , Suppose you want to provide a basis for developing advertising appeal for, a brand of cooking oil, the following sentence may be used:, , (ii), , (a), , People use cooking oil ……………., , (b), , Most of the new cooking oil ……………, , (c), , Costliest cooking oil …………………, , (d), , The thing I enjoy about cooking oil used by my family………….., , (e), , One important feature to be highlighted in the advertisement about, cooking oil is……………………………………., , Story Completion: A situation is described to a respondent who is asked to, complete the story based on his opinion and attitude. This technique will, reveal the interest of the respondent, but it is difficult to interpret. Example, 1: Mr. X belongs to the upper-middle class. He received a telephone call,, where the caller said, “I am from Globe Travels. Sir, I want to tell you about, our recent offer, that is, if you travel to the US this summer, you will get two, tickets free by the year-end to fly to the Far East., , What was Mr. X’s reaction? Why?, �, Example 2: Two children are quarreling at the breakfast table before, going to school. The younger of the two, has spilled coffee on her, brother’s shirt, which he was supposed to wear on the same day for, attending annual sports event., 80, , Self Learning Material
Page 81 :
What will the mother do?, �The story completion has numerous applications in solving marketing problem., The most important of which is to provide data to the seller, recognising the, image and feelings people have about the company’s products and services., This method is used before finalising an advertisement., , Sampling and Data, Collection, , Notes, , 3. Thematic Apperception Test (TAT), �, Definition: TAT is a projective technique. It is used to measure the attitude and, perception of the individual. Some picture cards are shown to respondents., The respondent is required to tell the story by looking at the picture. When the, subjects start telling the story, the researcher notices the respondents’ expression,, pauses and emotions to draw the inference., �, Administration: TAT is administered to individuals in an atmosphere free from, interruptions. The usual number of cards shown varies from 10 to 14., �The original TAT developer Murry recommended the use of 20 cards. The original, TAT consisted of 31 cards divided into 3 categories, viz, for use with men or, women only or for use with subjects of either sex. Of late, the use of separate, set of cards for men and women has been discontinued. The subject is then, instructed to tell a story about the picture on each card with specific instructions, to include a description of the event in the picture and the developments that led, to the event, the thoughts and feelings of people in the picture, and the outcome, of the story. The examiner keeps the cards in a pile, face down in front; gives, the respondent one card at a time, and asks the respondents to place each card, face down as the story is completed. Administering the TAT usually takes about, an hour., �, Recording: Murry’s original practice was to take notes by hand on the subject’s, responses, including his (her) non-verbal behaviours. Research has indicated,, however, that a great deal of significant material is lost when notes are recorded, in this way. As a result, some examiners now use a tape recorder to record the, respondent’s answers. Another option involves asking the respondent to write, down his (her) answers., �, Interpretation: In interpreting responses to the TAT, examiners typically, focus their attention on one of the three areas: the content of the stories that, the respondent tells; the feeling or tone of the stories; or the respondents’, behaviour apart from responses. These behaviours may include verbal remarks, (for example, comments about feeling stressed by the situation or not being a, good story teller) as well as non-verbal actions or signs (blushing, stammering,, fidgeting in the chair, difficulties in making eye contact with the examiner, etc.)., The story content usually reveals the respondents’ attitudes, fantasies, wishes,, inner conflicts, and views about the world outside. The story structure typically, Self Learning Material 81
Page 82 :
Research Methodology, , reflects the respondents’ feelings, assumptions about the world, and an underlying, attitude of optimism or pessimism., The respondent is helped by asking questions such as:, , Notes, , (i), , What is happening in the picture?, , (ii), , Why is it happening?, , (iii), , What is your feeling about the character shown in the picture?, , (iv), , Who is right?, , (v), , Who is the aggressor? Alternatively, who is right and who is wrong?, , 4. Cartoon Test or Balloon Test: Here a cartoon is shown. The cartoon character, belongs to a particular situation. One or more of ‘balloons’ including the, conversation of the character are left open and the respondent is asked to fill in., , 2.16, , Conditions for a Successful Interview, , An interview is an interaction between the researcher and the respondent. The purpose, of the interview is to elicit information from the respondent. Interview is the most, versatile and flexible method of communication. The questioning can be adapted to the, situation. Explanation, clarification can be requested if required. The drawback of the, interview is that it is costly., In order to complete an interview successfully, certain basic conditions should be, satisfied. They are as follows:, 1. Firstly, the interviewer should explain to the respondent what is expected from him., The respondent must know the subject matter before he begins answering there, searcher. If the respondent’s answer is incomplete, the researcher should re-phrase, the question and explain the same to the respondent. Example: How do you rate, the movie “The Devils Shock”? If the answer is ‘some what OK’, the researcher, cannot reach a conclusion about the perception of the respondent over the movie,, because the answer is incomplete. He should ask further questions like “Is it a, horror movie? ‘Was it shocking’? etc., 2. Secondly, the researcher must make sure that respondent possess the information, required at the time of conducting interview. The respondent may be facing many, problems due to which he is unable to give the information, e.g., Due to passage, of time, he has forgotten, or may be the subject is sensitive and the respondent, does not want to answer., 3. Thirdly, the respondents must be enthusiastic and co-operative. It is the job of the, interviewer to create trust and maintain a good rapport. The interaction between, the interviewer and respondent should not create a bias in the respondent’s replies., Therefore, it is the job of the interviewer to motivate the respondent. If the above, steps are not taken, there may be errors., 82, , Self Learning Material
Page 83 :
The job of the interviewer can be classified as follows:, (i), , Selecting the sample., , (ii), , Fixing interviews., , (iii), , Conduct interviews., , (iv), , Record the answers., , Sampling and Data, Collection, , Notes, , Selecting the Sample, There are two elements involved in the selection of a sample:, 1. The originally designated individuals from whom it is proposed to obtain, information., 2. Final determination of individuals from whom the information is actually obtained., The toughest problem in fixing the sample is the difficulty in getting together the, members of the universe. Unless obtained, it may not be possible to get a representative, sample. For example, personal interviews made at the shopping center, on different, days of the week or different times of the day. Here, there is no control on the sample., , Fixing the Interview, After locating the sample, the next step is to organize the interview. A letter in advance, is to be sent to the selected sample respondent. An ID cards have to be carried to identify, him/her- self, if the researcher is visiting an organisation. The respondent must be briefed, about the subject matter. He should be assured that confidentiality will be maintained, and he is required to feel free in answering. The interviewer must put the respondent at, ease and should not display any one-upmanship., , Conducting the Interview, At the commencement of the interview, start with simple and easy questions. Ask the, questions in the same order as given in the questionnaire. The interviewer should not, comment on the question’s meaning or indicate in any way, what kinds of answers are, acceptable. Care must be taken with respect to, not influencing the respondent with his, own ideas or thoughts or emphasizing on any particular aspect. Maintaining objectivity, throughout the interview process is the key to a successful interview. Any clarification, sought to various questions should be clarified by the interviewer., , Recording, The interviewer needs to record accurately, as answered by the respondent. If there, cording is not done properly, analysis of data will be difficult. In addition, the researcher, cannot come again to conduct another interview with the same respondent. It is better to, record the answers of the open-ended questions using a tape recorder instead of recording, by hands. Quick recording can be done by using abbreviations such as A.O (any other, Self Learning Material 83
Page 84 :
Research Methodology reason) or A.E (anything else). At the end of the interview, the researcher should thank, the respondent for spending his valuable time and co-operation extended., , Errors in Interviewing, , Notes, , 1. Interview involves social relationship between two persons. Respondents adjust, their conduct to what they consider to be appropriate to the situation. The interviewer, should be able to establish a good rapport. If a good rapport is lacking, the respondent, might answer half-heartedly. Errors can occur due to indifference of the respondent., 2. If the interviewer is biased, i.e., he suggests the answer by stressing some part of, the question or by his tone, errors can occur. The interview must be neutral and, objective, if this error is to be avoided., 3. Error can also occur due to inconsistencies in the reply of the respondent. The, interviewer should bring this to the notice of the respondent. The interviewer can, probe further to correct these inconsistencies., 4. There can be errors in recording or interpreting the response. One type of error, could be recording matter that were not said, as well as not recording matter that, were said. Clerical mistakes, add to errors. The interviewer’s experience, attitudes, and opinions also affect the recorded answers., 5. Cheating by interviewers is a serious problem leading to serious errors. The most, glaring example is the interviewer who fills the questions without making interviews., If respondents are difficult to locate and interview, cheating increases., How to minimize the errors:, (i), , Select and train the interviewers., , (ii), , Set up supervision to check the interviewers’ work., , 7.3.6, , Selection of Interviewers, , The following factors should be taken into account while selecting an interviewer:, zz He, , should be an enterprising person, social, freely mixing with people and, should have no hesitation in contacting strangers., , zz Should, , possess a pleasing personality., , zz Must, , be able to speak the language of the respondent., , zz Must, , possess good communication skills., , zz Must, , have patience and perseverance., , zz Must, , have flair to undertake fieldwork., , Training of Interviewers, Interviewers may be provided with two types of training. It should be:, 1. Field, 84, , Self Learning Material
Page 85 :
2. Classroom., Classroom training includes (i) fixing interviews (ii) asking questions(iii) recording, responses (iv) how to handle non-response, etc., For field training, the trainee, should accompany a senior and can be an observer, initially. After sometime, he may be asked to conduct interviews. The superior has to, point out his mistakes and correct the same. He must also suggest the ways and means, of improving., , Sampling and Data, Collection, , Notes, , Setting up Supervision to Check Interviewers Work, Some of the methods adopted are:, zz Check, , the forms filled in by the field workers., , zz Make surprise visits to those places, where the field worker conducted interviews,, , to cross verify., zz Re-interview, , the respondent, but this may not be practicable., , zz Send a self-addressed envelope to the respondent to verify whether the interview, , was held or not., zz In, , order to reduce cheating, the interviewer should be compensated, reasonably., , 2.17 Descriptive Research Design: Survey, How to conduct an accurate survey?, The Survey Research Design is often used because of the low cost and easy, accessible information., , Introduction, Conducting accurate and meaningful surveys is one of the most important facets of, market research in the consumer driven 21st century. Businesses, governments and media, spend billions of dollars on finding out what people think and feel. Accurate research, can generate vast amounts of revenue; bad or inaccurate research can cost millions, or, even bring down governments. The survey research design is a very valuable tool for, assessing opinions and trends. Even on a small scale, such as local government or small, businesses, judging opinion with carefully designed surveys can dramatically change, strategies. Television chat-shows and newspapers are usually full of facts and figures, gleaned from surveys but often no information is given as to where this information, comes from or what kind of people were asked. A cursory examination of these figures, usually shows that the results of these surveys are often manipulated or carefully sifted, to try to reflect distort the results to match the whims of the owners. Businesses are, often guilty of carefully selecting certain results to try to portray themselves as the, answer to all needs., Self Learning Material 85
Page 86 :
Research Methodology, , Notes, , When you decide to enter this minefield and design a survey, how do you avoid, falling into the trap of inaccuracy and bias? How do you ensure that your survey research, design reflects the views of a genuine cross-section of the population? The simple answer, is that you cannot; even with unlimited budget, time and resources, there is no way of, achieving 100% accuracy. Opinions, on all levels, are very fluid and can change on a, daily or even hourly basis., Despite this, surveys are still a powerful tool and can be an extremely powerful, research tool. As long as you design your survey well and are prepared to be selfcritical,you can still obtain an accurate representation of opinion., , Establishing the Aims of your Research, This is the single most important step of your survey research design and can make or, break your research; every single element of your survey must refer back to this design, or it will be fatally flawed., If your research is too broad, you will have to ask too many questions; too narrow, and you will not be researching the topic thoroughly enough., , Researching and Determining your Sample Group, This is the next crucial step in determining your survey and depends upon many factors., The first is accuracy; you want to try to interview as broad a base of people as possible., Quantity is not always the answer; if you were researching a detergent, for example, you, would want to target your questions at those who actually use such products., For a political or ethical survey, about which anybody can have a valid opinion,, you want to try to represent a well-balanced cross-section of society. It is always worth, checking beforehand what quantity and breadth of response you need to provide., Before you start the planning, it is important that you should consult somebody about, the statistical side of your survey research design. This way, you know what number, and type of responses you need to make it a valid survey and prevent inaccurate results., , Methodology, How do you make sure that your questionnaire reaches the target group? There are many, methods of reaching people but all have advantages and disadvantages. For a college or, university study it is unlikely that you will have the facilities to use the Internet, e-mail, or phone surveying so we will concentrate on only the likely methods you will use., , Face to Face, This is probably the most traditional method of the survey research design. It can be, very accurate. It allows you to be selective about to whom you ask questions and you, can explain anything that they do not understand. In addition, you can make a judgement, about who you think is wasting your time or giving stupid answers., 86, , Self Learning Material
Page 87 :
There are a few things to be careful of with this approach; firstly, people can be, reluctant to give up their time without some form of incentive. Another factor to bear, in mind is that it is difficult to ask personal questions face to face without embarrassing, people. It is also very time consuming and difficult to obtain are presentative sample., Finally, if you are going to be asking questions door-to-door, it is essential to ensure, that you have some official identification to prove whom you are., , Sampling and Data, Collection, , Notes, , Mail, This does not necessarily mean using the postal service; putting in the legwork and, delivering questionnaires around a campus or workplace is another method. This is a, good way of targeting a certain section of people and is excellent if you need to ask, personal or potentially embarrassing questions. The problems with this method are that, you cannot be sure of how many responses you will receive until a long time period has, passed. You must also be wary of collecting personal data; most countries have laws, about how much information you can keep about people so it is always wise to check, with some body more knowledgeable., , Structuring and Designing the Questionnaire, The design of your questionnaire depends very much upon the type of survey and the, target audience. If you are asking questions face to face, it is easy to explain if people, are unsure of a question. On the other hand, if your questionnaire is going to include, many personal questions then mailing methods are preferable., You must keep your questionnaire as short as possible; people will refuse to either, fill in a long questionnaire or get bored halfway through., If you do have lots of information it may be preferable to offer multiple-choice or, rating questions to make life easier., , Cover, It is also polite, especially with mailed questionnaires, to send a short cover note explaining, what you are doing and how the subject should return the surveys to you. You should, introduce yourself; explain why you are doing the research, what will happen with the, results and whom to contact if the subject has any queries, , Types of Question, Multiple choice questions allow many different answers, including do not know, to be, assessed. The main strength of this type of question is that the form is easy to fill in, and the answers can be checked easily and quantitatively; this is useful for large sample, groups., Rating, on some scale, is a tried and tested form of question structure. This way is, very useful when you are seeking to be a little more open-ended than is possible with, Self Learning Material 87
Page 88 :
Research Methodology multiple-choice questions. It is a little harder to analyze your responses. It is important, to make sure that the scale allows extreme views., , Notes, , Questions asking for opinions must be open-ended and allow the subject to give, their own response; you should avoid entrapment and appear to be as neutral as possible, during the procedure. The major problem is that you have to devise a numerical way of, analyzing and statistically evaluating the responses, which can lead to a biased view,, if care is not taken. These types of question should really be reserved for experienced, researchers., The order in which you ask the questions can be important. Try to start off with a few, friendly and non-threatening questions to put the interviewee at ease. Questions should, be simple and straightforward using everyday language rather than perfect grammar., Try to group questions about similar topics together; this makes it a lot quicker, for people to answer questions more quickly and easily., Some researchers advocate mixing up and randomizing questions for accuracy, but this approach tends to be more appropriate for advanced market research. For this, type of survey the researcher is trying to disguise the nature of the research and filter, out preconceptions., It is also a good idea to try out a test survey; ask a small group to give genuine, and honest feedback so that you can make adjustments., , Analyzing your Results, This is where the fun starts and it will depend upon the type of questions used. For, multiple-choice questions, it is a matter of counting up the answers to each question, and using statistics to ‘crunch the numbers’ and test relevance., Rating type question requires a little more work but follows broadly the same, principle. For opinion questions, you have to devise some way of judging the responses, numerically. The next step is to devise which statistical test you are going to use and, start to enter some numbers to judge the significance of your data., , Common Online Survey Mistakes to Avoid, Implementing online surveys is a fast and inexpensive way to gather key customer or, prospect data. Why is it that more companies are left either stymied by their survey, results or disappointed by the lack of participation? Unfortunately, many surveyors fall, into the same trap over and over again when it comes to building surveys. Although, online tools are widely available and easy-to use, the work of creating an effective, survey begins long before you logon to your chosen survey provider. Up front planning, ensures a meaningful, relevant, and highly successful survey. In addition, to help you, plan more efficiently, given below are five common survey mistakes to help you avoid, the “less-than-ideal” survey syndrome!, 88, , Self Learning Material
Page 89 :
1. Not determining your survey’s objective: So why are you conducting a survey?, Define what it is that you want to learn before you take another step (determinateness,, write questions, etc.). Do you want to measure your customer satisfaction or brand, perception? Do you want to probe for new features for your Product? Alternatively,, do you want to identify how to improve your current service offering? Each is an, excellent question, but heeds this warning: Do not try to do all of the above in one, survey. Your audience will not have the patience to answer all of those questions,, and—worse yet—they will get confused and irritated and your company’s brand, will suffer the consequences. Before you sit down to write your questions, determine, your survey’s objective and evaluate every question you pose against that objective., If the question does not serve your main goal, toss it., , Sampling and Data, Collection, , Notes, , 2. Failing to invite recipients to participate: Many companies create their survey, send, out an e-mail blast, and are puzzled when only a few folks respond. The missing, step an invitation! It is important to respect your audience’s time by asking for it., Send out a note from the CEO that announces a survey will arrive via e-mail within, the next 48 hours and invites the recipient to respond. Clearly, articulate the intent, of the survey and establish how long the survey should take to complete. Thank the, participants in advance for their time and participation. Remember, just because, this process is automated does not make it any less personal and you are asking, for information from some very busy people. Also,consider offering a “thank you”, gift as extra incentive., 3. Including poorly written or structured questions: Avoid ending up with, meaningless or difficult to understand survey results. Review your questions to, make sure you are not using double negatives, acronyms, or obscure technical or, industry jargon. Assuming your audience comprehends any out-of-the-ordinary, language is a costly assumption. The more clearly your questions are written, the, more quickly and clearly your participants will respond. Complicated questions, (i.e. “if this, then that, then what?”) are time-consuming to read and digest, and, are a turn-off to participants. The idea is to be concise, clear, and brief—other wise, you will watch your survey being abandoned over and over again., 4. Asking too many open-ended questions: Experts agree that open-ended questions, are more likely to yield vague, brief responses—or no response at all! If you want, specific information, ask specific questions. To collect the additional and cordial data, you are looking for, the best place for an open-ended question is as a follow-up to, a specific yes/no, multiple choice, or rate-response question. Focus the participant, on the concept or issue first, ask them a specific question, and then offer them the, opportunity to further elaborate on the topic at hand. If they have a comment, they, will give it. If not, they have moved on to the next question and are one-step closer, to completing the survey., 5. Sending out your survey on the less-optimum e-mail days: Friday, Saturday,, Sunday, or Monday. If your poll is not ready to send on a Tuesday, Wednesday,, Self Learning Material 89
Page 90 :
Research Methodology, , or Thursday, do not send it. To get maximum response, avoid the beginning and, end of the work week as well as the weekend. Everyone receives too much e-mail,, and clearing out our inboxes on Monday morning is a big part of starting the work, week. Do not let your survey fall victim to this routine “house-cleaning.” Also, do, not forget to test your survey before sending it. There is nothing more irritating, than deciding to fill out a survey and (a) it does not launch properly or (b) your, participant’s responses are not successfully submitted after they have taken the time, to thoughtfully answer the questions. Testing the survey with a few respondents, to make sure it is functioning properly and typo-free—and that the questions are, clearly written—is a quick and easy step to ensure success., , Notes, , Surveys are an excellent tool to reach out to customers, prospects, or employees,, and when executed properly, allow you to collect invaluable data quickly, easily, and, inexpensively. Avoid these common mistakes with your next survey, and reap the benefits, that timely, relevant information can provide to each aspect of your business., , 2.18, , Descriptive Research Design: Observation, , Observational research techniques solely involve the researcher or researchers making, observations. There are many positive aspects of the observational research approach., Namely, observations are usually flexible and do not necessarily need to be structured, around a hypothesis (remember a hypothesis is a statement about what you expect to, observe). For instance, before undertaking more structured research a researcher may, conduct observations in order to form a research question. This is called descriptive, research. In terms of validity, observational research findings are considered to be strong., Trochim states that validity is the best available approximation to the truth of a given, proposition, inference, or conclusion. Observational research findings are considered, strong in validity because the researcher is able to collect a depth of information about, a particular behaviour. However, there are negative aspects. There are problems with, reliability and generalizability., Reliability refers the extent that observations can be replicated. Seeing behaviours, occur over and over again may be a time consuming task., Generalizability, or external validity, is described by Trochim as the extent that the, study’s findings would also be true for other people, in other places, and at other times., In observational research, findings may only reflect a unique population and therefore, cannot be generalized to others. There are also problems with researcher bias. Often, it is assumed that the researcher may “see what they want to see.” Bias, however, can, often be overcome with training or electronically recording observations. Hence, overall,, observations are a valuable tool for researchers., First, we will discuss the appropriate situations to use observational field research., Second, the various types of observations research methods are explained. Finally,, 90, , Self Learning Material
Page 91 :
observational variables are discussed. This page’s emphasis is on the collection rather, the analysis of data., , Sampling and Data, Collection, , Should you or shouldn’t you collect your data through observation?, zz Questions, zz Is, , to consider:, , the topic sensitive?, , Notes, , zz Are, , people uncomfortable or unwilling to answer questions about a particular, subject?, , For instance, many people are uncomfortable when asked about prejudice. Selfreports of prejudice often bring biased answers. Instead, a researcher may choose to, observe black and white students interactions. In this case, observations are more likely, to bring about more accurate data. Thus, sensitive social issues are better suited for, observational research., , Can you Observe the Phenomena?, You must be able to observe what is relevant to your study. Let’s face it, you could, observe and observe but if you never see what you are studying, you are wasting your, time. You can’t see attitudes but you can observe behaviours and make inferences, about attitudes. In addition, you can’t be everywhere. There are certain things you can’t, observe. For example, questions regarding sexual behaviour are better left to a survey., , Do you have a lot of Time?, Many people don’t realize that observational research may be time consuming. In order, to obtain reliability, behaviours must be observed several times. In addition, there is, also a concern that the observer’s presence may change the behaviours being observed., As time goes on, however, the subjects are more likely to grow accustomed to your, presence and act normally. It is in the researcher’s best interest to observe for a long, period of time., , Are you not sure what you’re looking for, That’s okay! Known as descriptive research, observations are a great way to start a, research project. Let’s say you are interested in male and female behaviour in bars. You, have no idea what theory to use or what behaviour you are interested in looking for., So, you watch, and, wow, you see something. Like the amount of touching is related to, alcohol consumption. Therefore, you run to the library, gather your research, and may, be decide to do more observations or supplement your study with surveys. Then, these, observations turn into a theory once they are replicated (well, it’s not quite that simple)., , Types of Observations, There are various types of observation. Some of them are:, Self Learning Material 91
Page 92 :
Research Methodology Direct (Reactive) Observation, , Notes, , In direct observations, people know that you are watching them. The only danger is that, they are reacting to you. As stated earlier, there is a concern that individuals will change, their actions rather than showing you what they REALLY like. This is not necessarily, bad, however, for example, the contrived behaviour may reveal aspects of social, desirability, how they feel about sharing their feelings in front of others, or privacy in, a relationship. Even the most contrived behaviour is difficult to maintain over time. A, long-term observational study will often catch a glimpse of the natural behaviour. Other, problems concern the generalisability of findings. The sample of individuals may not be, representative of the population or the behaviours observed are not representative of the, individual (you caught the person on a bad day). Again, long-term observational studies, will often overcome the problem of external validity. What about ethical problems you, say? Ethically, people see you, they know you are watching them (sounds spooky, I, know) and they can ask you to stop., Now here are two commonly used types of direct observations:, 1. Continuous Monitoring: Continuous monitoring (CM) involves observing a subject, or subjects and recording (either manually, electronically, or both) as much of, their behaviour as possible. Continuous Monitoring is often used in organizational, settings, such as evaluating performance. Yet this may be problematic due to the, Hawthorne Effect. The Hawthorne Effect states that workers react to the attention, they are getting from the researchers and in turn, productivity increases. Observers, should be aware of this reaction. Other CM research is used in education, such as, watching teacher-student interactions. Also in nutrition where researchers record, how much an individual eats. CM is relatively easy but a time consuming endeavor., You will be sure to acquire many data., 2. Time Allocation: Time Allocation (TA) involves a researcher randomly selecting a, place and time and then recording what people are doing when they are first seen, and before they see you. This may sound rather bizarre but it is a useful tool when, you want to find out the percent of time people are doing things (i.e. playing with, their kids, working, eating, etc.). There are several sampling problems with this, approach. First, in order to make generalizations about how people are spending, their time the researcher needs a large representative sample. Sneaking up on people, all over town is tough way to spend your days. In addition, questions such as when,, how often, and where should you observe are often a concern. Many researchers, have overcome these problems by using non-random locations but randomly visiting, them at different times., , Unobtrusive Observation, Unobtrusive measures involves any method for studying behaviour where individuals do, not know they are being observed (don’t you hate to think that this could have happened, 92, , Self Learning Material
Page 93 :
to you!). Here, there is not the concern that the observer may change the subject’s, behaviour. When conducting unobtrusive observations, issues of validity need to be, considered. Numerous observations of a representative sample need to take place in, order to generalize the findings. This is especially difficult when looking at a particular, group. Many groups possess unique characteristics, which make them interesting studies., Hence, often such findings are not strong in external validity. In addition, replication is, difficult when using non-conventional measures (non-conventional meaning unobtrusive, observation). Observations of very specific behaviours are difficult to replicate in studies, especially if the researcher is a group participant (we’ll talk more about this later). The, main problem with unobtrusive measures, however, is ethical. Issues involving informed, consent and invasion of privacy are paramount here. An institutional review board may, frown upon your study if it is not really necessary for you not to inform your subjects., , Sampling and Data, Collection, , Notes, , Here is a description of two types of unobtrusive research measures you may decide to, undertake in the field:, 1. Behaviour Trace studies: Behavior trace studies involve finding things people, leave behind and interpreting what they mean. This can be anything to vandalism, to garbage. The University of Arizona Garbage Project is one of the most wellknown trace studies. Anthropologists and students dug through household garbage, to find out about such things as food preferences, waste behaviour, and alcohol, consumption. Again, remember, that in unobtrusive research individuals do not, know they are being studied. How would you feel about someone going through, your garbage? Surprisingly, Tucson residents supported the research as long as, their identities were kept confidential. As you might imagine, trace studies may, yield enormous data., 2. Disguised Field Observations: Okay, this gets a little sticky. In Disguised field, analysis, the researcher pretends to join or actually is a member of a group and, records data about that group. The group does not know they are being observed, for research purposes. Here, the observer may take on a number of roles. First, the, observer may decide to become a complete-participant in which they are studying, something they are already a member of. For instance, if you are a member of a, sorority and study female conflict within sororities you would be considered a, complete-participant observer. On the other hand, you may decide to only participate, casually in the group while collecting observations. In this case, any contact with, group members is by acquaintance only. Here you would be considered an observerparticipant. Finally, if you develop an identity with the group members but do not, engage in important group activities consider yourself a participant-observer. An, example would be joining a cult but not participating in any of their important rituals, (such as sacrificing animals). You are however, considered a member of the cult, and trusted by all of the members. Ethically, participant-observers have the most, problems. Certainly, there are degrees of deception at work. The sensitivity of the, topic and the degree of confidentiality are important issues to consider. Watching, Self Learning Material 93
Page 94 :
Research Methodology, , Notes, , classmates struggle with test-anxiety is a lot different than joining Alcoholics, Anonymous. In all, disguised field experiments are likely to yield reliable data but, the ethical dilemmas are a trade-off., , Observational Variables, Before you start on a research project, make sure how you are going to interpret your, observations., 1. Descriptive: Descriptive observational variables require no inference making on, the part of the researcher. You see something and write it down., 2. Inferential: Inferential observational variables require the researcher to make, inferences about what is observed and the underlying emotion. For example, you, may observe a girl banging on her keyboard. From this observation, you may, assume (correctly) that she is frustrated with the computer., 3. Evaluative: Evaluative observational variables require the researcher to make an, inference and a judgement from the behaviour. For example, you may question, whether computers and humans have a positive relationship. “Positive” is an, evaluative judgement. You observe the girl banging on her keyboard and conclude, that humans and computers do not have a positive relationship (you know you must, replicate these findings!)., While writing field notes the researcher should include descriptive as well as, inferential data. It is important to describe the setting and the mood in a detailed manner., All such things that may change behaviour need to be noted. Especially, those reflect, upon your presence. Do you think that you changed the behaviour noticeably?, , 2.19, , Why Sample?, , Sampling is done in a wide variety of research settings. Listed below are a few of the, benefits of sampling:, 1. Reduced Cost: It is obviously less costly to obtain data for a selected subset of a, population, rather than the entire population. Furthermore, data collected through, a carefully selected sample are highly accurate measures of the larger population., Public opinion researchers can usually draw accurate inferences for the entire, population of the United States from interviews of only 1,000 people., 2. Speed: Observations are easier to collect and summarize with a sample than with, a complete count. This consideration may be vital if the speed of the analysis is, important, such as through exit polls in elections., 3. Greater Scope: Sometimes highly trained personnel or specialized equipment limited, in availability must be used to obtain the data. A complete census (enumeration) is, not practical or possible. Thus, surveys that rely on sampling have greater flexibility, regarding the type of information that can be obtained., 94, , Self Learning Material
Page 95 :
It is important to keep in mind that the primary point of sampling is to create a, small group from a population that is as similar to the larger population as possible. In, essence, we want to have a little group that is like the big group. With that in mind, one, of the features we look for in a sample is the degree of representativeness–- how well, does the sample represent the larger population from which it was drawn? How closely, do the features of the sample resemble those of the larger population?, , Sampling and Data, Collection, , Notes, , There are, of course, good and bad samples, and different sampling methods have, different strengths and weaknesses. Before turning to specific methods, a few specialized, terms used in sampling should be defined., , 2.20 Distinction Between Census and Sampling, Census refers to complete inclusion of all elements in the population. A sample is a, sub-group of the population., , When a Census is Appropriate, 1. A census is appropriate if the size of population is small. For example: A researcher, may be interested in contacting firms in iron and steel or petroleum products, industry. These industries are limited in number, so a census will be suitable., 2. Sometimes, the researcher is interested in gathering information from every, individual. Example: Quality of food served in a mess., , When a Sample is Appropriate, 1. When the size of population is large., 2. When time and cost are the main considerations in research., 3. If the population is homogeneous., 4. Also, there are circumstances when a census is not possible. For example, Reactions, to global advertising by a company, , 2.21 Terms Used in Sampling, Samples are always drawn from a population, but we have not defined the term, “population.” By “population” we denote the aggregate from which the sample is, drawn. The population to be sampled (the sampled population) should coincide with, the population about which information is wanted (the target population). Sometimes,, for reasons of practicality or convenience, the sampled population is more restricted, than the target population. In such cases, precautions must be taken to secure that the, conclusions only refer to the sampled population., Before selecting the sample, the population must be divided into parts that are called, sampling units or units. These units must cover the whole of the population and they must, not overlap, in the sense that every element in the population belongs to one and only, Self Learning Material 95
Page 96 :
Research Methodology one unit. Sometimes the choice of the unit is obvious, as in the case of the population, of Americans so often used for opinion polling. In sampling, individuals in a town, the, unit might be an individual person, the members of a family, or all persons living in, the same city block. In sampling an agricultural crop, the unit might be a field, a farm,, Notes, or an area of land whose shape and dimensions are at our disposal. The construction of, this list of sampling units, called a frame, is often one of the major practical problems., Here are some important terms used in sampling:, zz A, , sample is a set of elements taken from a larger population., , zz The, , sample is a subset of the population which is the full set of elements or, people from which you are sampling., , zz A statistic, , is a numerical characteristic of a sample; a parameter is a numerical, characteristic of population., , zz Sampling, , error refers to the difference between the value of a sample statistic, (such as the sample mean) and the true value of the population parameter, (such as the population mean). Note: some error is always present in sampling., With random sampling methods, however, the error is random rather than, systematically wrong., , zz The, , response rate is the percentage of people in the sample selected for the, study who actually participate in the study., , zz A, , sampling frame is a list of all the people that are in the population., , In quantitative research, sampling is the selection of a group of persons from a, population with each person having an equal chance of being selected. The objective is to, draw a representative sample and the results obtained from the sample can be generalised, to the population. How is the issue of sampling dealt with in qualitative research? In, qualitative research, the concern is with the issue of ‘access’. What is meant by access?, When the researcher intends to observe or interview an individual or a group of, persons, he or she must gain access which means getting permission to be physically, present to gather the data. Once gaining access, the researcher is obliged to follow certain, social rules so as to maintain access. This is especially important in relatively private, settings where people do not want an outsider to interview or observe them. Related, to the issue of access, is the rationale or reason for selection of the particular sample, (which could be an individual or a group of individuals). In qualitative research, there, are two main reasons for selection of the sample (Potter, 1996)., zz First,, , the researcher might select person or persons to investigate because of, efficiency or convenience. Evidence is collected from the people who are easily, available to support the researcher’s arguments. For example:, A, , teacher might ask his or her students in the class to allow them to be, interviewed., , 96, , Self Learning Material
Page 97 :
The, , researcher might go into the community to which he or she belongs, and observe the behaviours of easily accessible parents., researcher might use the ‘snowball technique’ of interviewing those, people who are available and than asking them to suggest others who might, be willing to be interviewed. In the process, the number of people gradually, expands to those who have been referred., , Sampling and Data, Collection, , The, , Notes, , zz Second, the researcher might want to select a sample based on representativeness, , or a critical case or a typical case., If, , the researcher wants a sample that is representative, than the method, of sample selection used in quantitative research is adopted where each, individual case has an equal chance of being selected., , If, , the researcher wants a critical case, all possible cases are examined until, a critical case is found that best captures the unique features of what he or, she wants to illustrate., , If, , the researcher wants a typical case, he or she looks for the case that best, exemplifies the norm, and the extent to which cases are different or similar, to the typical case., , Lincoln and Guba (1985) emphasise that the guiding principle of sampling in, qualitative research is one of convenience. An important consideration in sampling is, whether there are people available who will allow the researcher to collect data about, them. For example, the researcher interested in preschoolers interacting during recess, may call up several kindergartens until he or she finds kindergartens that will allow him, or her to observe children during recess., If you read research using qualitative methods, you will see a range of positions on, the issue of sampling. Some studies do not give much information about how the people, interviewed or observed were selected. Other studies give some information about why, they selected certain people and how they gained access. The main issue with sampling, is the extent to which readers trust the findings of the research. If the researcher fails, to provide sufficient information about how he or she collected evidence especially in, relation to how and why particular persons were selected, it would be difficult for the, reader to trust the findings. Generally, readers will be more inclined to trust the findings, if the researcher provides detail description about the process of gaining access and, selection of the persons interviewed or observed., , 2.22 Sampling Process, Sampling process consists of seven steps. They are:, 1. Define the population., 2. Identify the sampling frame., Self Learning Material 97
Page 98 :
Research Methodology, , 3. Specify the sampling unit., 4. Selection of sampling method., 5. Determination of sample size., , Notes, , 6. Specify sampling plan., 7. Selection of sample., 1. Define the Population: Population is defined in terms of:, (i), , Elements, , (ii), , Sampling units, , (iii), , Extent, , (iv), , Time., , � xample: If we are monitoring the sale of a new product recently introduced by a, E, company, say (shampoo sachet) the population will be:, (i), , Element—Company’s product, , (ii), , Sampling unit—Retail outlet, super market, , (iii), , Extent—Hyderabad and Secunderabad, , (iv), , Time—April 10 to May 10, 2006, , 2. Identify the Sampling Frame: Sampling frame could be (a) Telephone Directory, (b) Localities of a city using the municipal corporation listing (c) Any other list, consisting of all sampling units., �, Example: You want to learn about scooter owners in a city. The RTO will be the, frame, which provides you names, addresses and the types of vehicles possessed., 3. Specify the Sampling Unit: Individuals who are to be contacted are the sampling, units. If retailers are to be contacted in a locality, they are the sampling units., Sampling unit may be husband or wife in a family. The selection of sampling, unit is very important. If interviews are to be held during office timings, when the, heads of families and other employed persons are away, interviewing would underrepresent employed persons, and over-represent elderly persons, housewives and, the unemployed., 4. Selection of Sampling Method: This refers to whether (a) probability or (b) nonprobability methods are used., 5. Determine the Sample Size: This means we need to decide “how many elements, of the target population are to be chosen?” The sample size depends upon the type, of study that is being conducted. For example, if it is an exploratory research, the, sample size will be generally small. For conclusive research, such as descriptive, research, the sample size will be large. The sample size also depends upon the, resources available with the company. It depends on the accuracy required in the, study and the permissible errors allowed., 98, , Self Learning Material
Page 99 :
6. Specify the Sampling Plan: A sampling plan should clearly specify the target, population. Improper defining would lead to wrong data collection. Example: This, means that, if a survey of a household is to be conducted, a sampling plan should, define a “household” i.e., “Does the household consist of husband or wife or both”,, minors, etc., “Who should be included or excluded.” Instructions to the interviewer, should include “How he should obtain a systematic sample of households, probability, sampling non-probability sampling”. Advise him on what he should do to the, household, if no one is available., , Sampling and Data, Collection, , Notes, , 7. Select the Sample: This is the final step in the sampling process., , 2.23 Sampling Techniques, Even if it were possible, it is not necessary to collect data from everyone in a community, in order to get valid findings. In qualitative research, only a sample (that is, a subset), of a population is selected for any given study. The study’s research objectives and the, characteristics of the study population (such as size and diversity) determine how many, people to select. In this section, we briefly describe some of the most common sampling, methods used in qualitative research., The two major types of sampling in quantitative research are random sampling and, non-random sampling., , Random Sampling Produces Representative Samples, 1. Random sampling., 2. Systematic random sampling., 3. Stratified random sampling, 4. Cluster sampling., 5. Multi-stage sampling., , Non-random Sampling does not Produce Representative Samples., Non-probability Sampling Techniques, 1. Deliberate sampling, 2. Shopping Mall Intercept Sampling, 3. Sequential sampling, 4. Quota sampling, 5. Snowball sampling, 6. Panel samples, We will study about these techniques in detail in the next unit., Self Learning Material 99
Page 100 :
Research Methodology, , 2.24, , Sample Sizes: Considerations, , When determining sample size for qualitative studies, it is important to remember that, there are no hard and fast rules. There are, however, at least two considerations:, , Notes, , 1. What sample size will reach saturation or redundancy? That is, how large does, the sample need to be to allow for the identification of consistent patterns? Some, researchers say the size of the sample should be large enough to leave you with, “nothing left to learn.” In other words, you might conduct interviews, and after the, tenth one, realize that there are no new concepts emerging. That is, the concepts,, themes, etc., begin be redundant., 2. How large a sample is needed to represent the variation within target population?, That is, how large must a sample be in order to assess an appropriate amount of, diversity or variation that is represented in the population of interest?, You may estimate sample size, based on the approach of the study or the data, collection method used. For each category there are some related rules of thumb,, represented in the tables below., , Rules of Thumb Based on Approach, Research approach, , Rule of thumb, , Biography/Case Study, , Select one case or one person., , Phenomenology, , Assess 10 people. If you reach saturation prior to, assessing, ten people you may use fewer., , Grounded theory/, ethnography/action, research, , Assess 20–30 people, which typically is enough to, reach saturation., , Rules of Thumb Based on Data Collection Method, Data Collection method, , 100 Self Learning Material, , Rule of thumb, , Interviewing key, informants, , Interview approximately five people., , In-depth interviews, , Interview approximately 30 people., , Focus groups, , Create groups that average 5–10 people each. In addition,, consider the number of focus groups you need based on, “groupings” represented in the research question. That, is, when studying males and females of three different, age groupings, plan for six focus groups, giving you one, for each gender and three age groups for each gender., , Ethnographic surveys, , Select a large and representative sample (purposeful, or random based on purpose) with numbers similar to, those in a quantitative study.
Page 101 :
There should also be consideration of the size of a good database, one that will, yield data that are of sufficient quality and quantity. While the quality of the data is, impacted by the quality of the interview protocol, the quantity of data is also a factor., For example, with a well-conceived interview protocol, a 10–20 hour database should, provide enough data to support a solid qualitative dissertation. In this case, the following, chart can be used:, , Sampling and Data, Collection, , Notes, , Guidelines for Length of Interviews, Number of interviews, , Length of each interview, , 10, , 1–2 hours, , 20, , 30 minutes–1 hour, , 30, , 20–40 minutes, , Adjustments may be made if there are other forms of qualitative data collection, involved. For example, if there are a 2-hour focus group and 10 interviews, the duration, of the interviews might be shortened., , 2.25 Sampling Challenges, Because researchers can seldom study the entire population, they must choose a subset, of the population, which can result in several types of error. Sometimes, there are, discrepancies between the sample and the population on a certain parameter that are, due to random differences. This is known as sampling error and can occur through no, fault of the researcher., Far more problematic is systematic error, which refers to a difference between the, sample and the population that is due to a systematic difference between the two rather, than random chance alone. The response rate problem refers to the fact that the sample, can become self-selecting, and that there may be something about people who choose, to participate in the study that affects one of the variables of interest. For example, in, our eye care case, we may experience this kind of error if we simply sample those who, choose to come to an eye clinic for a free eye exam as our experimental group and those, who have poor eyesight but do not seek eye care as our control group. It is very possible, in this situation that the people who actively seek help happen to be more proactive, than those who do not. Because these two groups vary systematically on an attribute, that is not the dependent variable (economic productivity), it is very possible that it is, this difference in personality trait and not the independent variable (if they received, corrective lenses or not) that produces any effects that the researcher observes on the, dependent variable. This would be considered a failure in internal validity., Another type of systematic sampling error is coverage error, which refers to the, fact that sometimes researchers mistakenly restrict their sampling frame to a subset, Self Learning Material 101
Page 102 :
Research Methodology of the population of interest. This means that the sample they are studying varies, systematically from the population for which they wish to generalize their results. For, example, a researcher may seek to generalize the results to the “population of developing, countries,” yet may have a coverage error by sampling only heavily urban areas. This, Notes, leaves out all of the more rural populations in developing countries, which have very, different characteristics than the urban populations on several parameters. Thus, the, researcher could not appropriately generalize the results to the broader population, and would therefore have to restrict the conclusions to populations in urban areas of, developing countries., First and foremost, a researcher must think very carefully about the population, that will be included in the study and how to sample that population. Errors in sampling, can often be avoided by good planning and careful consideration. However, in order to, improve a sampling frame, a researcher can always seek more participants. The more, participants a study has, the less likely the study is to suffer from sampling error. In, case of the response rate problem, the researcher can actively work on increasing the, response rate, or can try to determine if there is in fact a difference between those who, partake in the study and those who do not. The most important thing for a researcher to, remember is to eliminate any and all variables that the researcher cannot control. While, this is nearly impossible in field research, the closer a researcher comes to isolating the, variable of interest, the better the results., , 2.26, , Probability Samples, , The idea behind this type is random selection. More specifically, each sample from, the population of interest has a known probability of selection under a given sampling, scheme. There are four categories of probability samples described below., , Simple Random Sampling, The most widely known type of a random sample is the simple random sample (SRS)., This is characterized by the fact that the probability of selection is the same for every, case in the population. Simple random sampling is a method of selecting ‘n’ units from, a population of size ‘N’ such that every possible sample of size ‘n’ has equal chance, of being drawn., An example may make this easier to understand. Imagine you want to carry out a, survey of 100 voters in a small town with a population of 1,000 eligible voters. With a, town this size, there are “old-fashioned” ways to draw a sample. For example, we could, write the names of all voters on a piece of paper, put all pieces of paper into a box and, draw 100 tickets at random. You shake the box, draw a piece of paper and set it aside,, shake again, draw another, set it aside, etc., until we had 100 slips of paper. These 100, form our sample. And this sample would be drawn through a simple random sampling, procedure—at each draw, every name in the box had the same probability of being chosen., 102 Self Learning Material
Page 103 :
In real-world social research, designs that employ simple random sampling are, difficult to come by. We can imagine some situations where it might be possible that, you want to interview a sample of doctors in a hospital about work conditions. So you, get a list of all the physicians that work in the hospital, write their names on a piece of, paper and put those pieces of paper in the box, shake and draw. But in most real-world, instances it is impossible to list everything on a piece of paper and put it in a box, then, randomly draw numbers until desired sample size is reached., , Sampling and Data, Collection, , Notes, , There are many reasons why one would choose a different type of probability, sample in practice., , Example 1, Suppose you were interested in investigating the link between the family of origin and, income and your particular interest is in comparing incomes of Hispanic and NonHispanic respondents. For statistical reasons, you decide that you need at least 1,000, non-Hispanics and 1,000 Hispanics. Hispanics comprise around 6% or 7% of the, population. If you take a simple random sample of all races that would be large enough, to get you 1,000 Hispanics, the sample size would be near 15,000, which would be far, more expensive than a method that yields a sample of 2,000. One strategy that would be, more cost-effective would be to split the population into Hispanics and non-Hispanics,, then take a simple random sample within each portion (Hispanic and non-Hispanic)., , Example 2, Let’s suppose your sampling frame is a large city’s telephone book that has 2,000,000, entries. To take a SRS, you need to associate each entry with a number and choose n =, 200 numbers from N= 2,000,000. This could be quite an ordeal. Instead, you decide to, take a random start between 1 and N/n = 20,000 and then take every 20,000th name,, etc. This is an example of systematic sampling, a technique discussed more fully below., , Example 3, Suppose you wanted to study dance club and bar employees in NYC with a sample of, n = 600. Yet there is no list of these employees from which to draw a simple random, sample. Suppose you obtained a list of all bars/clubs in NYC. One way to get this would, be to randomly sample 300 bars and then randomly sample 2 employees within each, bar/club. This is an example of cluster sampling. Here the unit of analysis (employee), is different from the primary sampling unit (the bar/club)., In each of these three examples, a probability sample is drawn, yet none is an, example of simple random sampling. Each of these methods is described in greater, detail below., Although, simple random sampling is the ideal for social science and most of the, statistics used are based on assumptions of SRS, in practice, SRS are rarely seen. It can, Self Learning Material 103
Page 104 :
Research Methodology be terribly inefficient, and particularly difficult when large samples are needed. Other, probability methods are more common. Yet SRS is essential, both as a method and as, an easy-to-understand method of selecting a sample., , Notes, , To recap, though, that simple random sampling is a sampling procedure in which, every element of the population has the same chance of being selected and every element, in the sample is selected by chance., , Stratified Random Sampling, In this form of sampling, the population is first divided into two or more mutually, exclusive segments based on some categories of variables of interest in the research., It is designed to organize the population into homogenous subsets before sampling,, then drawing a random sample within each subset. With stratified random sampling the, population of ‘N’ units is divided into sub-populations of units respectively. These subpopulations, called strata, are non-overlapping and together they comprise the whole of, the population. When these have been determined, a sample is drawn from each, with, a separate draw for each of the different strata. The sample sizes within the strata are, denoted by respectively. If a SRS is taken within each stratum, the whole sampling, procedure is described as stratified random sampling., The primary benefit of this method is to ensure that cases from smaller strata of the, population are included in sufficient numbers to allow comparison. An example makes, it easier to understand. Say that you’re interested in how job satisfaction varies by race, among a group of employees at a firm. To explore this issue, we need to create a sample, of the employees of the firm. However, the employee population at this particular firm, is predominantly white, as the following chart illustrates:, , Fig. 2.3, If we were to take a simple random sample of employees, there’s a good chance, that we would end up with very small numbers of Blacks, Asians, and Latinos. That, could be disastrous for our research, since we might end up with too few cases for, comparison in one or more of the smaller groups., 104 Self Learning Material
Page 105 :
Rather than taking a simple random sample from the firm’s population at large, in, a stratified sampling design, we ensure that appropriate numbers of elements are drawn, from each racial group in proportion to the percentage of the population as a whole. Say, we want a sample of 1000 employees—we would stratify the sample by race (group, of White employees, group of African American employees, etc.), then randomly draw, out 750 employees from the White group, 90 from the African American, 100 from the, Asian, and 60 from the Latino. This yields a sample that is proportionately representative, of the firm as a whole., , Sampling and Data, Collection, , Notes, , Stratification is a common technique. There are many reasons for this, such as:, 1. If data of known precision are wanted for certain sub-populations, each of these, should be treated as a population in its own right., 2. Administrative convenience may dictate the use of stratification, for example, if, an agency administering a survey may have regional offices, which can supervise, the survey for a part of the population., 3. Sampling problems may be inherent with certain sub-populations, such as people, living in institutions (e.g. hotels, hospitals and prisons)., 4. Stratification may improve the estimates of characteristics of the whole population., It may be possible to divide a heterogeneous population into sub-populations,, each of which is internally homogenous. If these strata are homogenous, i.e., the, measurements vary little from one unit to another; a precise estimate of any stratum, mean can be obtained from a small sample in that stratum. The estimate can then, be combined into a precise estimate for the whole population., 5. There is also a statistical advantage in the method, as a stratified random sample, nearly always results in a smaller variance for the estimated mean or other population, parameters of interest., There are actually two different types of stratified sampling., The first and most common type of stratified sampling is called proportional, stratified sampling., zz In, , proportional stratified sampling you must make sure your sub-samples, (e.g., the samples of males and females) are proportional to their sizes in the, population., , zz Proportional, , stratified sampling is an equal probability sampling method (i.e.,, it is EPSEM), which is good!, , zz The, , second type of stratified sampling is called disproportional stratified, sampling., , zz In, , disproportional stratified sampling, the sub-samples are not proportional to, their sizes in the population., , zz Here, , is an example showing the difference between proportional and, disproportional stratified sampling:, Self Learning Material 105
Page 106 :
Research Methodology, , zz Assume, , that your population is 75% female and 25% male. Assume that you, want a sample of size 100 and you want to stratify on the variable called, gender., , zz For, , proportional stratified sampling, you would randomly select 75 females, and 25 males from the gender populations., , Notes, , zz For, , disproportional stratified sampling, you might randomly select 50 females, and 50 males from the gender populations., , Systematic Sampling, Systematic method of sampling is at first glance very different from SRS. In practice, it, is a variant of simple random sampling that involves some listing of elements – every, nth element of list is then drawn for inclusion in the sample. Say you have a list of, 10,000 people and you want a sample of 1,000., Creating such a sample includes three steps:, 1. Divide number of cases in the population by the desired sample size. In this example,, dividing 10,000 by 1,000 gives a value of 10., 2. Select a random number between one and the value attained in Step 1. In this, example, we choose a number between 1 and 10 - say we pick 7., 3. Starting with case number chosen in Step 2, take every tenth record (7, 17, 27, etc.)., More generally, suppose that the ‘N’ units in the population are ranked 1 to N in some, order (e.g., alphabetic). To select a sample of ‘n’ units, we take a unit at random, from, the 1st ‘k’ units and take every k-th unit thereafter., The advantages of systematic sampling method over simple random sampling include:, 1. It is easier to draw a sample and often easier to execute without mistakes. This is, a particular advantage when the drawing is done in the field., 2. Intuitively, you might think that systematic sampling might be more precise, than SRS. In effect it stratifies the population into ‘n’ strata, consisting of the, 1st ‘k’ units, the 2nd ‘k’ units, and so on. Thus, we might expect the systematic, sample to be as precise as a stratified random sample with one unit per stratum., The difference is that with the systematic one the units occur at the same relative, position in the stratum whereas with the stratified, the position in the stratum is, determined separately by randomization within each stratum., , Cluster Sampling, In some instances, the sampling unit consists of a group or cluster of smaller units that, we call elements or sub-units (these are the units of analysis for your study). There are, two main reasons for the widespread application of cluster sampling. Although, the first, intention may be to use the elements as sampling units, it is found in many surveys that no, reliable list of elements in the population is available and that it would0 be prohibitively, 106 Self Learning Material
Page 107 :
expensive to construct such a list. In many countries there are no complete and updated, lists of the people, the houses or the farms in any large geographical region., , Sampling and Data, Collection, , Primary Area, , Notes, , Chunk, , Sample Location, , Housing Unit, , Segment, , Fig. 2.3, Even when a list of individual houses is available, economic considerations may, point to the choice of a larger cluster unit. For a given size of sample, a small unit usually, gives more precise results than a large unit. For example, a SRS of 600 houses covers, a town more evenly than 20 city blocks containing an average of 30 houses apiece. But, greater field costs are incurred in locating 600 houses and in traveling between them, than in covering 20 city blocks. When cost is balanced against precision, the larger unit, may prove superior., We discuss two types of cluster sampling in the unit, one-stage and two-stage., The first type of cluster sampling is one-stage cluster sampling., zz To, , select a one-stage cluster sample, first randomly select a sample of, clusters., Self Learning Material 107
Page 108 :
Research Methodology, , zz Then, , you include in your final sample all of the individual units that are in, the randomly selected clusters. (For example, if you randomly selected 15, classrooms you would include all of the students in those 15 classrooms.), , The second type of cluster sampling is called two-stage cluster sampling., , Notes, , zz In, , the first stage, you randomly select a sample of clusters (i.e., just like you, did in one-stage cluster sampling)., , zz In, , the second stage, you take a random sample of the elements in each of, the clusters that you selected in the first stage (e.g., in stage two you might, randomly select 10 students from each of the 15 classrooms you selected in, stage one)., , Important things about cluster sampling:, 1. Most large scale surveys are done using cluster sampling;, 2. Clustering may be combined with stratification, typically by clustering within strata;, 3. In general, for a given sample size ‘n’ cluster samples are less accurate than the, other types of sampling in the sense that the parameters you estimate will have, greater variability than an SRS, stratified random or systematic sample., , 2.27, , Non-probability Sampling, , Social research is often conducted in situations where a researcher cannot select the, kinds of probability samples used in large-scale social surveys. For example, you want, to study homelessness—there is no list of homeless individuals nor are you likely to, create such a list. However, you need to get some kind of sample of respondents in, order to conduct your research. To gather such a sample, you would use some form of, non-probability sampling., To reiterate, the primary difference between probability methods of sampling and, non-probability methods is that in the latter you do not know the likelihood that any, element of a population will be selected for study., There are four primary types of non-probability sampling methods:, , Availability Sampling, Availability sampling is a method of choosing subjects which are available or easy to, find. This method is also sometimes referred to as haphazard, accidental, or convenience, sampling. The primary advantage of the method is that it is very easy to carry out,, relative to other methods. A researcher can merely stand out on his/her favorite street, corner or in his/her favorite tavern and hand out surveys. One place this used to show, up often is in university courses. Years ago, researchers often would conduct surveys, of students in their large lecture courses. For example, all students taking introductory, sociology courses would have been given a survey and compelled to fill it out. There, 108 Self Learning Material
Page 109 :
are some advantages to this design– it is easy to do, particularly with a captive audience,, and in some schools you can attain a large number of interviews through this method., , Sampling and Data, Collection, , The primary problem with availability sampling is that you can never be certain, what population the participants in the study represent. The population is unknown, the, method for selecting cases is haphazard, and the cases studied probably don’t represent, any population you could come up with., , Notes, , However, there are some situations in which this kind of design has advantages, for, example, survey designers often want to have some people respond to their survey before, it is given out in the “real” research setting as a way of making certain the questions, make sense to respondents. For this purpose, availability sampling is not a bad way to, get a group to take a survey, though in this case researchers care less about the specific, responses given than whether the instrument is confusing or makes people feel bad., Despite the known flaws with this design, it’s remarkably common. Ask a, provocative question, give telephone number and web site address (“Vote now at CNN., com) and announce results of poll. This method provides some form of statistical data, on a current issue, but it is entirely unknown what population the results of such polls, represent. At best, a researcher could make some conditional statement about people, who are watching CNN at a particular point in time who cared enough about the issue, in question to log on or call in., , Quota Sampling, Quota sampling is designed to overcome the most obvious flaw of availability sampling., Rather than taking just anyone, you set quotas to ensure that the sample you get represents, certain characteristics in proportion to their prevalence in the population. Note that for, this method, you have to know something about the characteristics of the population, ahead of time. Say, you want to make sure that you have a sample proportional to the, population in terms of gender – you have to know what percentage of the population, is male and female, then collect sample until yours matches. Marketing studies are, particularly fond of this form of research design., The primary problem with this form of sampling is that even when we know that, a quota sample is representative of the particular characteristics for which quotas have, been set, we have no way of knowing if sample is representative in terms of any other, characteristics. If we set quotas for gender and age, we are likely to attain a sample with, good representativeness on age and gender, but one that may not be very representative, in terms of income and education or other factors., Moreover, because researchers can set quotas for only a small fraction of the, characteristics relevant to a study, quota sampling is really not much better than availability, sampling. To reiterate, you must know the characteristics of the entire population to, set quotas; otherwise there’s not much point to setting up quotas. Finally, interviewers, Self Learning Material 109
Page 110 :
Research Methodology often introduce bias when allowed to self-select respondents, which is usually the case in, this form of research. In choosing males 18–25, interviewers are more likely to choose, those that are better-dressed, seem more approachable or less threatening. That may be, understandable from a practical point of view, but it introduces bias into research findings., , Notes, , Purposive Sampling, Purposive sampling is a sampling method in which elements are chosen based on purpose, of the study. Purposive sampling may involve studying the entire population of some, limited group (sociology faculty at Columbia) or a subset of a population (Columbia, faculty who have won Nobel Prizes). As with other non-probability sampling methods,, purposive sampling does not produce a sample that is representative of a larger population,, but it can be exactly what is needed in some cases–study of organization, community,, or some other clearly defined and relatively limited group., , Snowball Sampling, Snowball sampling is a method in which a researcher identifies one member of some, population of interest, speaks to him/her and then asks that person to identify others in, the population that the researcher might speak to. This person is then asked to refer the, researcher to yet another person, and so on., Snowball sampling is very good for cases where members of a special population, are difficult to locate. For example, several studies of Mexican migrants in Los Angeles, have used snowball sampling to get respondents., The method also has an interesting application to group membership. If you want, to look at pattern of recruitment to a community organization over time, you might, begin by interviewing fairly recent recruits, asking them who introduced them to the, group. Then interview the people named, asking them who recruited them to the group., The method creates a sample with questionable representativeness. A researcher, is not sure who is in the sample. In effect snowball sampling often leads the researcher, into a realm he/she knows little about. It can be difficult to determine how a sample, compares to a larger population. Also, there’s an issue of who respondents refer you, to – friends refer to friends, less likely to refer to ones they don’t like, fear, etc., , Panel Samples, Panel samples are frequently used in marketing research. To give an example, suppose, that one is interested in knowing the change in the consumption pattern of households., A sample of households is drawn. These households are contacted to gather information, on the pattern of consumption. Subsequently, say after a period of six months, the, same households are approached once again and the necessary information on their, consumption is collected., 110 Self Learning Material
Page 111 :
2.28 Random Selection and Random Assignment, In random selection, you select a sample from a population using one of the random, sampling techniques discussed earlier., zz Your, , purpose is to obtain a sample that represents the population., , Sampling and Data, Collection, , Notes, , zz If, , you use a EPSEM technique, the resulting sample will be like a “mirror, image” of the population, except for chance differences., , zz For example, if you randomly select (e.g., using simple random sampling) 1000, , people from the adult population in Ann Arbor, Michigan, the sample will look, like the adult population of Ann Arbor., In random assignment, you start with a set of people (you already have a sample,, which very well may be a convenience sample), and then you randomly divide that set, of people into two or more groups (i.e., you take the full set and randomly divide it, into subsets)., zz Your, , purpose it to produce two or more groups that are similar to each other, on all characteristics., , zz You, , are taking a set of people and randomly “assigning” them to two or more, groups., , zz The groups or subsets will be “mirror images” of each other (except for chance, , differences)., zz For example, if you start with a convenience sample of 100 people and randomly, , assign them to two groups of 50 people, the two groups will be “equivalent”, on all known and unknown variables., Random assignment generates similar groups; it is used in experimental research, to produce the strongest experimental research designs., , 2.29 Determining the Sample Size When Random Sampling is, used, Would you like to know the answer to the question “How big should my sample be?”, Given below are some “simple” answers to your important question:, zz Always, , try to get as big of a sample as you can for your study (up to say a, 1000 people or so)., , zz If, , your population is only 100 people or fewer, include the entire population, in your study rather than taking a sample (i.e., don’t take a sample; include, everyone)., , zz To, , get a feel for typical sample sizes, examine other studies in the research, literature on your topic and see how many they are selecting., Self Learning Material 111
Page 112 :
Research Methodology, , Here are a few more points about sample size. In particular, you will need larger, samples under these circumstances:, , Notes, , zz When, , the population is very heterogeneous., , zz When, , you want to break down the data into multiple categories., , zz When, , you want a relatively narrow confidence interval., , zz When, , you expect a weak relationship or a small effect., , zz When, , you use a less efficient technique of random sampling (e.g., cluster, sampling is less efficient than proportional stratified sampling)., , zz When you expect to have a low response rate. The response rate is the percentage, , of people in your sample who agree to be in your study., , Sampling in Qualitative Research, Sampling in qualitative research is usually purposive (see the above discussion of, purposive sampling). The primary goal in qualitative research is to select information, rich cases., There are several specific purposive sampling techniques that are used in qualitative, research:, Maximum variation sampling (i.e., you select a wide range of cases)., Homogeneous sample selection (i.e., you select a small and homogeneous case or, set of cases for intensive study)., Extreme case sampling (i.e., you select cases that represent the extremes on some, dimension)., Typical-case sampling (i.e., you select typical or average cases)., Critical-case sampling (i.e., you select cases that are known to be very important)., Negative-case sampling (i.e., you purposively select the cases which disconfirm, your generalizations, so that you can make sure that you are not just selectively finding, cases to support your personal theory)., Opportunistic sampling (i.e., you select useful cases as the opportunity arises)., Mixed purposeful sampling (i.e., you mix the sampling strategies we have discussed, into more complex designs tailored to your needs)., , 2.30, , Sampling in Mixed Research, , Sampling in mixed research builds on your knowledge of sampling in quantitative and, qualitative research. Typically, the researcher will select the quantitative sample using, one of the quantitative sampling techniques and the qualitative sample using one of the, qualitative sampling techniques., Sampling in mixed research can be classified into “mixed sampling designs.”, 112 Self Learning Material
Page 113 :
Mixed sampling designs are classified according to two major criteria:, zz The, , first criterion is called time orientation. Time orientation is provided by, the answer to this question: “Do the quantitative and qualitative phases occur, concurrently or sequentially?”, In, , a concurrent time orientation, the data are collected for the quantitative and, , Sampling and Data, Collection, , Notes, , qualitative phases of the study at approximately the same time. Both sets of, data are interpreted during data analysis and interpretation., In, , a sequential time orientation, the data obtained in stages; the data from the, , first stage are used to shape selection of data in the second stage., zz The, , second criterion is called sample relationship. Sample relationship, is determined by answering this question: “Is the relationship between, the quantitative and qualitative samples identical, parallel, nested, or, multilevel?”, , zz In, , an identical sample relation, the same people participate in the quantitative, and qualitative phases of your study., , zz In, , a parallel sample relation, separate quantitative and qualitative samples are, drawn from the same population and they participate in your study., , zz In, , a nested sample relation, the participants selected for one phase are a subset, of the participants selected for the other phase., , zz In, , a multilevel sample relation, the quantitative and qualitative samples are, selected from different levels of a population., , You can combine these two criteria just discussed—time orientation (which has two, types) and sample relationship (which has four types)—to form eight mixed sampling, designs:, 1. identical concurrent, 2. identical sequential, 3. parallel concurrent, 4. parallel sequential, 5. nested concurrent, 6. nested sequential, 7. multilevel concurrent, 8. multi-level sequential., For reference, these eight sampling designs are described (but you do not need to, memorize them!):, 1. In an identical concurrent sampling design, quantitative and qualitative data are, collected from the same people (identical) at approximately the same time (i.e.,, concurrently)., Self Learning Material 113
Page 114 :
Research Methodology, , 2. In an identical sequential sampling design, quantitative and qualitative data are, collected from the same people (identical) in stages (sequential)., 3. In a parallel concurrent sampling design, separate quantitative and qualitative, samples are selected from the same population (parallel), and data are collected at, approximately the same time (concurrently)., , Notes, , 4. In a parallel sequential sampling design, separate quantitative and qualitative, samples are selected from the same population (parallel), and data are collected, from these two samples in stages (sequentially)., 5. In a nested concurrent sampling design, the participants selected for one phase, are a subset of the participants selected for the other phase (nested), and data are, collected at approximately the same time (concurrently)., 6. In a nested sequential sampling design, the participants selected for one phase, are a subset of the participants selected for the other phase (nested), and data are, collected from these two samples in stages (sequentially)., 7. In a multilevel concurrent sampling design, the quantitative and the qualitative, samples are selected from different levels of a population (multilevel), and data, are collected at approximately the same time (concurrently)., In a multilevel sequential sampling design, the quantitative and the qualitative, samples are selected from different levels of a population (multilevel), and data are, collected from these two samples in stages (sequentially)., Last, once you have selected one of the eight mixed sampling designs, you must, select the sampling method and sample size for both quantitative and qualitative phases., zz For, , the quantitative phase, use one of the quantitative sampling methods, discussed earlier in the unit., , zz For the qualitative phase, use one of the qualitative sampling methods discussed, , earlier in the unit., , 2.31 Distinction between Probability Sample and Non-probability, Sample, Probability Sample, 1. Here, each member of a universe has a known chance of being selected and included, in the sample., 2. Any personal bias is avoided. The researcher cannot exercise his discretion in the, selection of sample items., Examples: Random Sample, cluster sample., , Non-Probability Sample, In this case, the likelihood of choosing a particular universe element is unknown. The, sample chosen in this method is based on aspects like convenience, quota, etc., Examples: Quota sampling, Judgment sampling., 114 Self Learning Material
Page 115 :
2.32 Errors in Sampling, , Sampling and Data, Collection, , Sampling Error, The only way to guarantee the minimization of sampling error is to choose the appropriate, sample size. As the sample keeps on increasing, the sampling error decreases. Sampling, error is the gap between the sample mean and population mean., , Notes, , Example, If a study is done amongst Maruti car-owners in a city to find the average monthly, expenditure on the maintenance of car, it can be done by including all Maruti car owners., It can also be done by choosing a sample without covering the entire population. There, will be a difference between the two methods with regard to monthly expenditure., , Non-sampling Error, One way of distinguishing between the sampling and the non-sampling error is that,, while sampling error relates to random variations which can be found out in the form, of standard error, non-sampling error occurs in some systematic way which is difficult, to estimate., , Sampling Frame Error, A sampling frame is a specific list of population units, from which the sample for a, study being chosen., , Example 1, An MNC bank wants to pick up a sample among the credit card holders. They can readily, get a complete list of credit card holders, which forms their data bank. From this frame,, the desired individuals can be chosen. In this example, sample frame is identical to, ideal population namely all credit card holders. There is no sampling error in this case., , Example 2, Assume that a bank wants to contact the people belonging to a particular profession, over phone (doctors and lawyers) to market a home loan product. The sampling frame, in this case is the telephone directory. This sampling frame may pose several problems:, 1. People might have migrated., 2. Numbers have changed., 3. Many numbers were not yet listed. The question is “Are the residents who are, included in the directory likely to differ from those who are not included”? The, answer is yes. Thus in this case, there will be a sampling error., , Non-response Error, This occurs, because the planned sample and the final sample vary significantly., Self Learning Material 115
Page 116 :
Research Methodology Example, , Notes, , Marketers want to know about the television viewing habits across the country. They, choose 500 households and mail the questionnaire. Assume that only 200 respondents, reply. This does not show a non-response error, which depends upon the discrepancy. If, those 200 who replied did not differ from the chosen 500, there is no non-response error., Consider an alternative. The people who responded are those who had plenty of, leisure time. Therefore, it is implied that non-respondents do not have adequate leisure, time. In this case, the final sample and the planned sample differ. If it was assumed that, all the 500 chosen have leisure time, but in the final analysis only 200 have leisure time, and not others. Therefore, a sample with respect to leisure time leads to response error., , Guidelines to Increase the Response Rate, Every researcher likes to get maximum possible response from the respondents, and, will be most delighted if all the respondents respond but unfortunately, this does not, happen. The non-response error can be reduced by increasing the response rate. Higher, the response rate, more accurate and reliable is the data. In order to achieve this, some, useful suggestions could be as follows:, 1. Intimate the respondents in advance through a letter. This will improve the, preparedness., 2. Personalized Questionnaire should be accompanied by a covering letter., 3. Ensure/Assure that confidentiality will be maintained., 4. Questionnaire’s length is to be restricted., 5. In case of personal interview, I.D. card is essential to prove the bona fide., 6. Monetary incentives are gifts which will act as motivator, 7. Reminder/Revisits would help., 8. Send self addressed/stamped envelope to return the completed questionnaire., , Data Error, This occurs during the data collection, analysis of data or interpretation. Respondents, sometimes give distorted answers unintentionally for questions which are difficult, or if, the question is exceptionally long and the respondent may not have answer. Data errors, can also occur depending on the physical and social characteristics of the interviewer and, the respondent. Things such as the tone and voice can affect the responses. Therefore,, we can say that the characteristics of the interviewer can also result in data error. Also,, cheating on the part of the interviewer leads to data error. Data errors can also occur, when answers to open-ended questions are being improperly recorded., , Failure of the Interviewer to Follow Instructions, The respondent must be briefed before beginning the interview, “What is expected”?, 116 Self Learning Material
Page 117 :
“To what extent he should answer”? Also, the interviewer must make sure that, respondent is familiar with the subject. If these are not made clear by the interviewer,, errors will occur., Editing mistakes made by the editors in transferring the data from questionnaire, to computers are other causes for errors., , Sampling and Data, Collection, , Notes, , The respondent could terminate his/her participation in data gathering, because it, may be felt that the questionnaire is too long and tedious., , How to Reduce Non-Sampling Error, 1. For non-response: Provide incentives such as a gift or cash. This enhances the, possibility as well as incidence of response., 2. Data Error: Don’t ask question, which respondents cannot answer. Also, do not, ask sensitive questions., 3. Train the interviewer to establish a good rapport with the respondents., 4. Avoid leading questions., 5. Pre-test the questionnaire., 6. Modify the sampling frame to make it a represe, , 2.33 Summary, In this unit, we discussed what a hypothesis is, the place of hypothesis testing in research, and what the steps for hypothesis testing are., zz Hypothesis: A prediction of the outcome of a study. Hypotheses are drawn from, , theories and research questions or from direct observations., zz The, , simplistic definition of the null is as the opposite of the alternative, hypothesis, H1, although the principle is a little more complex than that. The, null hypothesis (H0) is a hypothesis which the researcher tries to disprove,, reject or nullify. The ‘null’ often refers to the common view of something, while, the alternative hypothesis is what the researcher really thinks is the cause of a, phenomenon. An experiment conclusion always refers to the null, rejecting or, accepting H0 rather than H1., , zz The, , hypothesis guides us on the selection of a certain design, observations and, methods of researching over others., , zz The, , two steps of hypothesis testing:, , The, , first step is to formulate the alternative and null hypotheses., , The second step is to test the null hypothesis (rather than seeking to support, , the experimental hypothesis), by carrying out a statistical test of significance, to determine whether it can be rejected, and consequently, whether there is, a difference between the groups under investigation., Self Learning Material 117
Page 118 :
Research Methodology, , Notes, , Logically, there are two types of errors when drawing conclusions in research:, Type 1 error is when we accept the research hypothesis when the null hypothesis is, in fact correct. Type 2 error is when we reject the research hypothesis even if the null, hypothesis is wrong., Secondary data are statistics that already exists. These may not be readily used because, these data are collected for some other purpose. There are two types of secondary data (1), Internal and (2) External secondary data. Census is the most important among secondary, data. Syndicated data is an important form of secondary data which may be classified into, (a) Consumer purchase data (b) Retailer and wholesale data (c) Advertising data. Each has, advantages and disadvantages. Secondary data has its own advantages and disadvantages., Sometimes, secondary data may not be able to solve the research problem. In, that case, researcher needs to turn towards primary data. Primary data may pertain, to life style, income, awareness or any other attribute of individuals or groups. There, are two ways of collecting primary data namely. (a) Observation (b) By questioning, the appropriate sample. Observation method has a limitation, i.e., certain attitudes,, knowledge, motivation, etc., cannot be measured by this method. For this reason,, researcher needs to communicate., Communication method is classified based on whether it is structured or disguised., Structured questionnaire is easy to administer. This type is most suited for descriptive, research. If the researcher wants to do exploratory study, unstructured method is better., In unstructured method questions will have to be framed based on the answer by the, respondent. In disguised questionnaire, the purpose of research is not disclosed to, respondents. This is done so that the respondents might speak the truth instead of giving, some answer which satisfies the researcher., Questionnaire can be administered either in person or online or Mail questionnaire., Each of these methods has advantages and disadvantages. Questions in a questionnaire, may be classified into (a) Open question (b) Close-ended questions (c) Dichotomous, questions, etc. While formulating questions, care has to be taken with respect to, question’s wording, vocabulary, leading, loading and confusing questions should be, avoided. Further, it is desirable that questions should not be complex, or too long. It is, also implied that proper sequencing will enable the respondent to answer the question, easily. The researcher must maintain a balanced scale and must use a funnel approach., Pre-testing of the questionnaire is preferred before introducing to a large population., Personal interview is very costly to gather information. Therefore, sometimes mail, questionnaire is used by researcher to collect the data. However, it has its own limitations., Qualitative techniques are used in exploratory research. Depth interview allows, flexibility in gathering information, unstructured nature of the interview allows the, respondent to tell whatever he wishes. The greatest advantages of depth interview are, its ability to discover hidden motives. However, its limitation is subjectivity. Focus, , 118 Self Learning Material
Page 119 :
group is another method used for gathering information. It is nothing but an indirect, interview. However, focus group suffers from certain disadvantages, such as influence, of one member on others. Moreover, the success depends on the skill of the moderator., , Sampling and Data, Collection, , Projective techniques are indirect form of questioning, various techniques are, word association test, completion techniques, TAT, cartoon test, etc. In word association, consumer responds, with the first word that comes to his mind. In sentence competition, test, respondents are given a part of sentence. The remaining part has to be completed, with first thoughts that come to mind. Necessary instructions are given to the respondent, by researcher. In story telling, after reading the story, respondent is required to answer, the questions given. This provides data image or feelings of the respondent. TAT is a, projective technique used to measure perception of the individual. Picture cards are, shown to individual and response sought. For successful interview, interviewer need to, select the sample, organize the interview and record the response correctively. However,, errors can occur in interviewing due to inconsistency in the reply of interviewer, training, will help in reducing the error., , Notes, , Sample is a representative of population. Census represents hundred percent of, population. The most important factors distinguishing whether to choose sample or, census is cost and time. There are seven steps involved in selecting the sample. There, are two types of sample (a) Probability sampling (b) Non-probability sample., There are two types of sample (a) Probability sampling (b) Non-probability sample., Probability sampling includes random sampling, stratified random sampling systematic, sampling, cluster sampling, Multistage sampling. Random sampling can be chosen by, Lottery method or using random number table. Samples can be chosen either with equal, probability or varying probability. Random sampling can be systematic or stratified., In systematic random sampling, only the first number is randomly selected. Then by, adding a constant “K” remaining numbers are generated. In stratified sampling, random, samples are drawn from several strata, which have more or less same characteristics. In, multistage sampling, sampling is drawn in several stages., Purposive sampling is one of the most common sampling strategies in which, groups/participants are selected according to pre-selected criteria relevant to a particular, research question (for example, HIV-positive women in Capital City). Sample sizes, may or may not be fixed prior to data collection they depend on the resources and time, available, as well as the study’s objectives., In quota sampling, we decide while designing the study how many people with, what characteristics to include as participants. Characteristics might include age, place, of residence, gender, class, profession, marital status, use of a particular contraceptive, method, HIV status, etc., A third type of sampling is snowball sampling which is also known as chain referral, sampling – is considered a type of purposive sampling. In this method, participants or, Self Learning Material 119
Page 120 :
Research Methodology informants with whom, contact has already been made use their social networks to refer, the researcher to other people who could potentially participate in or contribute to the, study. Snowball sampling is often used to find and recruit “hidden populations,” that is,, groups not easily accessible to researchers through other sampling strategies., , Notes, , 2.34, , Glossary, zz Hypothesis:, , A prediction of the outcome of a study., , zz Null, , hypothesis: The null hypothesis (H0) is a hypothesis which the researcher, tries to disprove, reject or nullify., , zz Research hypothesis: A research hypothesis is the statement created by researchers, , when they speculate upon the outcome of a research or experiment., zz Type, , 1 error: Type 1 error is when we accept the research hypothesis when the, null hypothesis is in fact correct., , zz Type, , 2 error: Type 2 error is when we reject the research hypothesis even if, the null hypothesis is wrong., , zz Primary, , Data: The data directly collected by the researcher, with respect to, the problem under study, is known as primary data., , zz Observation Method: In the observation method, only present/current behaviour, , can be studied., zz Disguised Observation: In disguised observation, the respondents do not know, , that they are being observed., zz Undisguised Method: In the undisguised method, observations may be restrained, , due to induced error by the objects of observation., zz Open-ended, , questions: These are questions where respondents are free to, answer in their own words., , zz Dichotomous, , question: These questions have only two answers, ‘Yes’ or ‘no’,, ‘true’ or ‘false’ ‘use’ or ‘don’t use’., , zz Closed-ended questions: There are two basic formats in this type: (a) Make one, , or more choices among the alternatives and (b) Rate the alternatives., zz Leading, , question: A leading question is one that suggests the answer to the, respondent., , zz Depth, , interview: Unstructured, direct interview is known as a depth, interview., , zz Focus, , group: A group of people jointly participates in an unstructured indirect, interview conducted by a moderator., , zz Projective, , technique: Projective techniques (Indirect method of gathering, information/indirect interview) are unstructured and involve indirect form of, questioning., , 120 Self Learning Material
Page 121 :
zz Census:, , It refers to the complete inclusion of all elements in the population., A sample is a sub-group of the population., , Sampling and Data, Collection, , zz Statistic: A statistic, , is a numerical characteristic of a sample; a parameter is a, numerical characteristic of population., , zz Sampling, , error: Sampling error refers to the difference between the value of a, sample statistic (such as the sample mean) and the true value of the population, parameter (such as the population mean)., , Notes, , zz Random, , sampling: Simple random sample is a process in which every item of, the population has an equal probability of being chosen., , zz Stratified, , random sampling: A probability sampling procedure refers to in, which, simple random sub-samples are drawn from within different strata,, which are more or less equal on some characteristics., , zz Multistage, , sampling: The name implies that sampling is done in several, , stages., , 2.35, , Review Questions, , 1. What is a hypothesis? What are the steps in Hypothesis Testing?, 2. Differentiate between Type I and Type II Errors., 3. What is primary data? Discuss various methods available for collecting primary data., 4. What are the advantages and disadvantages of a structured questionnaire?, 5. Discuss the several methods used to collect data by observation method., 6. What are the advantages and limitations of collecting data by observation method?, 7. What is a questionnaire? What are the different types of questionnaire?, 8. Write the characteristics and limitations of a good questionnaire?, 9. Explain the steps involved in designing a questionnaire., 10. Explain Open ended and Closed ended questions in a questionnaire., 11. What is a split ballot method? When is it employed?, 12. What is questionnaire pre-testing?, 13. What is a dichotomous question? When is it most appropriate?, 14. How does a questionnaire suffer when it is compared to experimentation on account, of validity and reliability?, 15. What is meant by pre-testing of questionnaire? Why is it required?, 16. Distinguish qualitative and quantitative method of data collection., 17. What is mail questionnaire? Explain the advantages and limitations of the same., Self Learning Material 121
Page 122 :
Research Methodology, , 18. What is meant by leading/loading question give example?, 19. What is meant by double barreled questions?, 20. Design a questionnaire to study brand preference for a consumer durable product., , Notes, , 21. What is a method of data collection?, 22. What are the six main methods of data collection?, 23. What are the two “cardinal rules” of educational research mentioned in this chapter?, 24. What is the difference between a quantitative and a qualitative interview?, 25. Why would a researcher want to conduct a focus group?, 26. What are the main differences between quantitative and qualitative observations?, 27. What are the four main roles that a researcher can take during qualitative, observation?, 28. What is the difference between front stage and backstage behaviour?, 29. What are some examples of secondary or existing data?What is meant by qualitative, techniques of data collection? Explain., 30. What are the advantages of the observation method? Discuss., 31. Distinguish between open and disguised observation., 32. What is Delphi Technique? Explain., 33. What is focus group interview? What are the advantages and limitations of this, method?, 34. What are the qualities required for a focus group moderator?, 35. Why is training of interviewers important for fieldwork?, 36. What is TAT? When and why is it useful?, 37. What are the conditions that are prerequisite for a successful interview?, 38. What are the sources of error in interviewing?, 39. How to conduct an accurate survey?, 40. How to collect data through observation methods?, 41. What are the two broad categories of sampling?, 42. When is Sample Appropriate?, 43. Distinguish census from sampling., 44. What is sampling frame? Give an example., 45. What are the steps involved in the process of sampling?, 46. What are the different types of sample designs?, 47. What are the steps involved in determining the appropriate sample size?, 48. Discus types of probability sampling techniques., , 122 Self Learning Material
Page 123 :
49. What is systematic random sampling? How are the random start number and the, sampling interval determined?, , Sampling and Data, Collection, , 50. Discuss the types of non-probability sampling techniques., 51. Explain the steps to be followed in the process of cluster sampling., 52. Write the advantages and disadvantages of multistage sampling?, , Notes, , 53. Discuss the advantages and disadvantages of probability sampling technique., Distinguish probability and non-probability sampling., 54. What are the guidelines to determine the sample size of a population?, , 2.36 Further Readings, Kothari, Research Methodology, Willey International Ltd., New, , zz C.R., , Delhi, J. Goode and Paul K. Hatt, Methods in Social Research, McGraw, Hill, New Delhi, , zz William, , Moser and G. Kalton, Survey Methods in Social Investigation, , zz C.A., , Bhandar Kar and T.S. Wilkinson, Methodology and Techniques of Social, Research, Himalaya Publishing House, Delhi, , zz P.L., , Michael, Research Methodology in Management, Himalaya Publishing, House, Delhi, , zz V.P., , zz S.R., , Bajpai, Methods of Social Survey and Research, Kitab Ghar, Kanpur, , Gopal, An Introduction to Research Procedure in Social Sciences, Asian, Publishing House, Bombay, , zz M.H., , Self Learning Material 123
Page 124 :
Research Methodology, , UNIT–3, , Measurement and Scaling, , Notes, , (Structure), 3.1, , Learning Objectives, , 3.2, , Introduction, , 3.3, , Measurement Scales: Tools of Sound Measurement, , 3.4, , Techniques of Developing Measurement Tools, , 3.5, , Scaling – Meaning, , 3.6, , Comparative and Non-comparative Scaling Techniques, , 3.7, , Criteria for the Good Test, , 3.8, , Summary, , 3.9, , Keywords, , 3.10, , Review Questions, , 3.11, , Further Readings, , 3.1, , Learning Objectives, , After studying the chapter, students will be able to:, zz Recognize, zz Explain, , the tools of sound measurement;, , the techniques of developing measurement tools;, , zz Describe, , the meaning and techniques of scaling;, , zz Differentiate, zz Describe, , 3.2, , among Comparative and non-comparative scales;, , the Multi-dimensional scaling techniques., , Introduction, , Measurement is assigning numbers or other symbols to characteristics of objects being, measured, according to predetermined rules. Concept (or Construct) is a generalized, idea about a class of objects, attributes, occurrences, or processes., Relatively concrete constructs comprises of aspects such as Age, gender, number, of children, education, income. Relatively abstract constructs take into accounts the, aspects such as Brand loyalty, personality, channel power, satisfaction., 124 Self Learning Material
Page 125 :
Scaling is the generation of a continuum upon which measured objects are located. Measurement and Scaling, Scale is a quantifying measure – a combination of items that is progressively, arranged according to value or magnitude. The purpose is to quantitatively represent, an item's, person's, or event's place in the scaling continuum., , 3.3, , Notes, , Measurement Scales: Tools of Sound Measurement, , These are of four kinds of scales, namely:, 1. Nominal scale, 2 Ordinal scale, 3. Interval scale, 4. Ratio scale, , Nominal Scale, In this scale, numbers are used to identify the objects. For example, University, Registration numbers assigned to students, numbers on their jerseys., The purpose of marking numbers, symbols, labels etc. in this type of scaling is, not to establish an order but it is to simply put labels in order to identify events and, count the objects and subjects. This measurement scale is used to classify individuals,, companies, products, brands or other entities into categories where no order is implied., Indeed, it is often referred to as a categorical scale. It is a system of classification and, does not place the entity along a continuum. It involves a simple count of the frequency, of the cases assigned to the various categories, and if desired numbers can be nominally, assigned to label each category., , Characteristics, 1. It has no arithmetic origin., 2. It shows no order or distance relationship., 3. It distinguishes things by putting them into various groups., Use: This scale is generally used in conducting in surveys and ex-post-facto research., Example: Have you ever visited Bangalore?, 'Yes' is coded as 'One' and 'No' is coded as 'Two'. The numeric attached to the, answers has no meaning, and is a mere identification. If numbers are interchanged as, one for 'No' and two for 'Yes', it won't affect the answers given by respondents. The, numbers used in nominal scales serve only the purpose of counting., The telephone numbers are an example of nominal scale, where one number is, assigned to one subscriber. The idea of using nominal scale is to make sure that no, two persons or objects receive the same number. Similarly, bus route numbers are the, example of nominal scale., Self Learning Material 125
Page 126 :
Research Methodology, , "How old are you"? This is an example of a nominal scale. "What is your PAN, Card number?, Arranging the books in the library, subject wise, author wise - we use nominal scale., It should be kept in mind that nominal scale has certain limitation, viz., , Notes, , 1. There is no rank ordering., 2. No mathematical operation is possible., 3. Statistical implication - Calculation of the standard deviation and the mean is, not possible. It is possible to express the mode., , Ordinal Scale (Ranking Scale), The ordinal scale is used for ranking in most market research studies. Ordinal scales, are used to ascertain the consumer perceptions, preferences, etc. For example, the, respondents may be given a list of brands which may be suitable and were asked to, rank on the basis of ordinal scale:, 1. Lux, 2. Liril, 3. Cinthol, 4. Lifebuoy, 5. Hamam, Rank, , Item, , Number of respondents, , I, , Cinthol, , 150, , II, , Liril, , 300, , III, , Hamam, , 250, , IV, , Lux, , 200, , V, , Life buoy, , 100, , Total, , 1,000, , In the above example, II is mode and III is median., Statistical implications: It is possible to calculate the mode and the median., In market research, we often ask the respondents to rank the items, like for example,, "A soft drink, based upon flavour or colour". In such a case, the ordinal scale is used., Ordinal scale is a ranking scale., Rank the following attributes of 1-5 scale according to the importance in the, microwave oven:, Attributes, , 126 Self Learning Material, , Rank, , (A), , Company Image, , 5, , (B), , Functions, , 3
Page 127 :
(C), , Price, , 2, , (D), , Comfort, , 1, , (E), , Design, , 4, , Measurement and Scaling, , Ordinal scale is used to arrange things in order. In qualitative researches, rank, , Notes, , ordering is used to rank characteristics units from the highest to the lowest., , Characteristics, 1. The ordinal scale ranks the things from the highest to the lowest., 2. Such scales are not expressed in absolute terms., 3. The difference between adjacent ranks is not equal always., 4. For measuring central tendency, median is used., 5. For measuring dispersion, percentile or quartile is used., Scales involve the ranking of individuals, attitudes or items along the continuum, of the characteristics being scaled., From the information provided by ordinal scale, the researcher knows the order of, preference but nothing about how much more one brand is preferred to another i.e., there, is no information about the interval between any two brands. All of the information, a, nominal scale would have given, is available from an ordinal scale. In addition, positional, statistics such as the median, quartile and percentile can be determined. It is possible, to test for order correlation with ranked data. The two main methods are Spearman's, Ranked Correlation Coefficient and Kendall's Coefficient of Concordance which shall, be discussed later in the unit., In nominal scale numbers can be interchanged, because it serves only for the purpose, of counting. Numbers in Ordinal scale have meaning and it won't allow interchangeability., 1. Students may be categorized according to their grades of A, B, C, D, E, F etc., where A is better than B and so on. The classification is from the highest grade, to the lowest grade., 2. Teachers are ranked in the University as professor, associate professors, assistant, professors and lecturers, etc., 3. Professionals in good organizations are designated as GM, DGM, AGM,, SR.MGR, MGR, Dy. MGR., Asstt. Mgr. and so on., 4. Ranking of two or more households according to their annual income or, expenditure, e.g., Households, Annual Income (`), , A, 5,000, , B, 9,000, , C, 7,000, , D, 13,000, , E, 21,000, , If highest income is given #1, than we write as, Self Learning Material 127
Page 128 :
Research Methodology, , Households, , Order of Households on the Basis of Annual, Income, , A, , E(1), , B, , D(2), , C, , B(3), , D, , C(4), , E, , A(5), , Notes, , One can ask respondents questions on the basis of one or more attributes such as, flower, colour, etc., and ask about liking or disliking, e.g., whether the respondent likes, soft drinks or not., I strongly like it, , +2, , I like it, , +1, , I am indifferent, , 0, , I dislike it, , –1, , I strongly dislike it, , –2, , In this manner, ranking can be obtained by asking the respondent their level of, acceptability. One can then combine the individual ranking and get a collective ranking, of the group., Interval scale uses the principle of "equality of interval" i.e., the intervals are used, as the basis for making the units equal assuming that intervals are equal., It is only with an interval scaled data that researchers can justify the use of the, arithmetic mean as the measure of average. The interval or cardinal scale has equal units, of measurement thus, making it possible to interpret not only the order of scale scores, but also the distance between them. However, it must be recognized that the zero point, on an interval scale is arbitrary and is not a true zero. This, of course, has implications, for the type of data manipulation and analysis we can carry out on data collected in this, form. It is possible to add or subtract a constant to all of the scale values without affecting, the form of the scale but one cannot multiply or divide the values. It can be said that, two respondents with scale positions 1 and 2 are as far apart as two respondents with, scale positions 4 and 5, but not that a person with score 10 feels twice as strongly as, one with score 5. Temperature is interval scaled, being measured either in Centigrade or, Fahrenheit. We cannot speak of 50°F being twice as hot as 25°F since the corresponding, temperatures on the centigrade scale, 100°C and -3.9°C, are not in the ratio 2:1., Interval scales may be either numeric or semantic., , Characteristics, 1. Interval scales have no absolute zero. It is set arbitrarily., 2., 128 Self Learning Material, , For measuring central tendency, mean is used.
Page 129 :
3., , For measuring dispersion, standard deviation is used., , Measurement and Scaling, , 4. For test of significance, t-test and f-test are used., 5., , Scale is based on the equality of intervals., , Use: Most of the common statistical methods of analysis require only interval, scales in order that they might be used. These are not recounted here because they are, so common and can be found in virtually all basic texts on statistics., , Notes, , Interval Scale, Interval scale is more powerful than the nominal and ordinal scales. The distance given, on the scale represents equal distance on the property being measured. Interval scale, may tell us "How far the objects are apart with respect to an attribute?" This means, that the difference can be compared. The difference between "1" and "2" is equal to the, difference between "2" and "3"., Interval scale uses the principle of "equality of interval" i.e., the intervals are used, as the basis for making the units equal assuming that intervals are equal., It is only with an interval scaled data that researchers can justify the use of the, arithmetic mean as the measure of average. The interval or cardinal scale has equal units, of measurement thus, making it possible to interpret not only the order of scale scores, but also the distance between them. However, it must be recognized that the zero point, on an interval scale is arbitrary and is not a true zero. This, of course, has implications, for the type of data manipulation and analysis we can carry out on data collected in this, form. It is possible to add or subtract a constant to all of the scale values without affecting, the form of the scale but one cannot multiply or divide the values. It can be said that, two respondents with scale positions 1 and 2 are as far apart as two respondents with, scale positions 4 and 5, but not that a person with score 10 feels twice as strongly as, one with score 5. Temperature is interval scaled, being measured either in Centigrade or, Fahrenheit. We cannot speak of 50°F being twice as hot as 25°F since the corresponding, temperatures on the centigrade scale, 100°C and -3.9°C, are not in the ratio 2:1., Interval scales may be either numeric or semantic., Characteristics, 1. Interval scales have no absolute zero. It is set arbitrarily., 2. For measuring central tendency, mean is used., 3. For measuring dispersion, standard deviation is used., 4. For test of significance, t-test and f-test are used., 5. Scale is based on the equality of intervals., Use: Most of the common statistical methods of analysis require only interval, scales in order that they might be used. These are not recounted here because they are, so common and can be found in virtually all basic texts on statistics., Self Learning Material 129
Page 130 :
Example:, , Research Methodology, , 1. Suppose we want to measure the rating of a refrigerator using interval scale., It will appear as follows:, , Notes, , (a) Brand name, , Poor …………………… Good, , (b) Price, , High …………………….. Low, , (c) Service after-sales, , Poor …………………… Good, , (d) Utility, , Poor …………………….Good, , The researcher cannot conclude that the respondent who gives a rating of 6 is 3, times more favourable towards a product under study than another respondent, who awards the rating of 2., 2. How many hours you spend to do class assignment every day?, (a) < 30 min., (b) 30 min. to 1 hr., (c) 1 hr. to 1½ hrs., (d) > 1½ hrs., Statistical implications: We can compute the range, mean, median, etc., , Ratio Scale, Ratio scale is a special kind of internal scale that has a meaningful zero point. With this, scale, length, weight or distance can be measured. In this scale, it is possible to say, how, many times greater or smaller one object is being compared to the other., These scales are used to measure actual variables. The highest level of measurement, is a ratio scale. This has the properties of an interval scale together with a fixed origin, or zero point. Examples of variables which are ratio scaled include weights, lengths and, times. Ratio scales permit the researcher to compare both differences in scores and in the, relative magnitude of scores. For instance, the difference between 5 and 10 minutes is the, same as that between 10 and 15 minutes, and 10 minutes is twice as long as 5 minutes., Given that sociological and management research seldom aspires beyond the, interval level of measurement, it is not proposed that particular attention be given to, this level of analysis. Suffice it, to say that virtually all statistical operations can be, performed on ratio scales., , Characteristics, 1. This scale has an absolute zero measurement., 2. For measuring central tendency, geometric and harmonic means are used., Use: Ratio scale can be used in all statistical techniques., Example: Sales this year for product A are twice the sales of the same product, last year., Statistical implications: All statistical operations can be performed on this scale., 130 Self Learning Material
Page 131 :
3.4 Techniques of Developing Measurement Tools, The scale construction techniques are used for measuring the attitude of a group or an, individual. In other words, scale construction technique helps in estimate the interest or, behaviour of an individual or a group towards others or another's environment rather than, oneself. While performing a scale construction technique, you need to consider various, decisions related to the attitude of the individual or group. A few of these decisions are:, , Measurement and Scaling, , Notes, , zz Determining, , the level of the involved data; identifying whether it is nominal,, ordinal, interval or ratio., , zz Identifying, , the useful statistical analysis for the scale construction., , zz Identifying, , the scale construction technique to be used., , zz Selecting, , the physical layout of the scales., , zz Determining, , the scale categories that need to be used., , There are two primary scale construction techniques, comparative and noncomparative. The comparative technique is used to determine the scale values of multiple, items by performing comparisons among the items. In the non-comparative technique,, scale value of an item is determined without comparing with another item. Furthermore,, these two techniques are also of many types. The various types of comparative techniques, are:, 1. Pairwise comparison scale: This is an ordinal level scale construction, technique, where a respondent is provided with two items and then asked him, to select his/her choice., 2. Rasch model scale: In this technique, multiple respondents are simultaneously, involved with several items and from their responses comparisons are derived, to determine the scale values. Rank-order scale: This is also an ordinal level, scale constructing technique, where a respondent is provided with multiple, items, which he needs to rank accordingly., 3. Constant sum scale: In this scale construction technique, a respondent is usually, provided with a constant amount of money, credits or points that he needs to, allocate to various items for determining the scale values of the items., The various types of non-comparative techniques are:, 1. Continuous rating scale: In this technique, respondents generally use a series, of numbers known as scale points for rating an item. This technique is also, known as graphic rating scaling., 2. Likert scale: This technique allows the respondents to rate the items on a, scale of five to seven points depending upon the amount of their agreement or, disagreement on the item., 3. Semantic differential scale: In this technique, respondents are asked to rate, the different attributes of an item on a seven-point scale., Self Learning Material 131
Page 132 :
Research Methodology, , Notes, , 3.5, , Scaling – Meaning, , Scaling is a process or set of procedures, which is used to assess the attitude of an, individual. Scaling is defined as the assignment of objects to numbers according to a, rule. The objects in the definition are text statements, which can be the statements of, attitude or principle. Attitude of an individual is not measured directly by scaling. It is, first migrated to statements and then the numbers are assigned to them. Figure below, shows the how to scale the attitude of individuals., Do you permit drinkers, to live in your country?, Do you permit drinkers to, live in your neighbourhood?, Do you let your child to, marry a drinker?, , Figure 3.1, In the above figure, we are going to assess the attitude of an individual by analysing, his thoughts about drinkers. You can see that as you move down, the attitude or behaviour, of people towards drinkers become more provisional. If an individual agrees with a, statement in the list, then it is more likely that he will also agree with all of the assertions, above that statement. Thus in this example, the rule is growing one. So this is called, scaling. Scaling is done in the research process to test the hypothesis. Sometimes, you, can also use scaling as the part of probing research., , 3.6, , Comparative and Non-comparative Scaling Techniques, 1. Comparative Scales: It involve the direct comparison of two or more objects., Scaling, Techniques, Comparative, Scales, , Paired, Comparison, , Non-comparative, Scales, , Constant, Sum, Rank, Order, , Continuous, Rating Scales, , Itemized, Rating Scales, , Likert, , Stapel, Semantic, Differential, , Figure 3.2: Classifying Scaling Techniques, 132 Self Learning Material
Page 133 :
2. Non-comparative Scales: Objects or stimuli are scaled independently of each Measurement and Scaling, other., , Comparative Scaling Techniques, , Notes, , Paired Comparison, Example: Here a respondent is asked to show his preferences from among five, brands of coffee – A, B, C, D and E with respect to flavours. He is required to indicate, his preference in pairs. A number of pairs are calculated as follows. The brands to be, rated are presented two at a time, so each brand in the category is compared once to every, other brand. In each pair, the respondents were asked to divide 100 points on the basis, of how much they liked one compared to the other. The score is totally for each brand., No. of pairs =, , N(N – 1), 2, , In this case, it is, , 5(5 – 1), 2, , A&B, , B&D, , A&C, , B&E, , A&D, , C&D, , A&E, , C&E, , B&C, , D&E, , If there are 15 brands to be evaluated, then we have 105 paired comparison(s) and, that is the limitation of this method., Example: For each pair of professors, please indicate the professor from whom, you prefer to take classes with a 1., Cunningham, Cunningham, Day, Parker, Thomas, # of times, Preferred, , 1, 1, 1, 3, , Day, 0, 0, 1, 1, , Parker, 0, 1, 1, 2, , Thomas, 0, 0, 0, 0, 0, , Rank Order Scaling, 1. Respondents are presented with several objects simultaneously, 2. Then asked to order or rank them according to some criterion, 3. Data obtained are ordinal in nature-Arranged or ranked in order of magnitude, 4. Commonly used to measure preferences among brands and brand attributes, Self Learning Material 133
Page 134 :
Research Methodology, , Notes, , Example: Please rank the instructors listed below in order of preference. For the, instructor you prefer the most, assign a "1", assign a "2" to the instructor you prefer the, 2nd most, assign a "3" to the instructor that you prefer 3rd most, and assign a "4" to the, instructor that you prefer the least., Instructor, , Ranking, , Cunningham, , 1, , Day, , 3, , Parker, , 2, , Thomas, , 4, , Constant Sum Scaling, 1. Respondents are asked to allocate a constant sum of units among a set of, stimulus objects with respect to some criterion, 2. Units allocated represent the importance attached to the objects, 3. Data obtained are interval in nature, 4. Allows for fine discrimination among alternatives, Example: Listed below are 4 marketing professors, as well as 3 aspects that students, typically find important. For each aspect, please assign a number that reflects how well, you believe each instructor performs on the aspect. Higher numbers represent higher, scores. The total of all the instructors' scores on an aspect should equal 100., Instructor, , Availability, , Fairness, , Easy Tests, , Cunningham, , 30, , 35, , 25, , Day, , 30, , 25, , 25, , Parker, , 25, , 25, , 25, , Thomas, , 15, , 15, , 25, , Sum Total, , 100, , 100, , 100, , Non-comparative Scale, Continuous Rating Scale, VERY POOR ………………………………………….............VERY GOOD, 0, , 10, , 20, , 30, , 40, , 50, , 60, , 70, , 80, , 90, , 100, , Likert Scale, It is known as summated rating scale. This consists of a series of statements concerning, an attitude object. Each statement has '5 points', Agree and Disagree on the scale. They, are also called summated scales, because scores of individual items are summated to, produce a total score for the respondent. The Likert Scale consists of two parts-item part, 134 Self Learning Material
Page 135 :
and evaluation part. Item part is usually a statement about a certain product, event or Measurement and Scaling, attitude. Evaluation part is a list of responses like "strongly agree" to "strongly disagree"., The five point-scale is used here. The numbers like +2, +1, 0, –1, –2 are used. Now,, let us see with an example how the attitude of a customer is measured with respect to, Notes, a shopping mall., Table 3.1: Evaluation of Globus-the Super Market by Respondent, S.No., , Likert scale items, , Strongly Disagree, disagree, , Neither Agree Strongly, agree nor, agree, disagree, , 1., , Salesmen at the, shopping mall are, courteous, , -, , -, , -, , -, , -, , 2., , Shopping mall does, not have enough, parking space, , -, , -, , -, , -, , -, , 3., , Prices of items are, reasonable., , -, , -, , -, , -, , -, , 4., , Mall has wide range, of products to choose, , -, , -, , -, , -, , -, , 5., , Mall operating hours are inconvenient, , -, , -, , -, , -, , 6., , The arrangement of items in the mall is, confusing, , -, , -, , -, , -, , The respondents' overall attitude is measured by summing up his (her) numerical, rating on the statement making up the scale. Since some statements are favourable and, others unfavourable, it is the one important task to be done before summing up the, ratings. In other words, "strongly agree" category attached to favourable statement and, "strongly disagree" category attached to unfavourable. The statement must always be, assigned the same number, such as +2, or –2. The success of the Likert Scale depends, on "How well the statements are generated?" The higher the respondent's score, the more, favourable is the attitude. For example, if there are two shopping malls, ABC and XYZ, and if the scores using the Likert Scale are 30 and 60 respectively, we can conclude that, the customers' attitude towards XYZ is more favourable than ABC., , Semantic Differential Scale, This is very similar to the Likert Scale. It also consists of a number of items to be rated, by the respondents. The essential difference between Likert and Semantic Differential, Scale is as follows:, Self Learning Material 135
Page 136 :
Research Methodology, , It uses "Bipolar" adjectives and phrases. There are no statements in the Semantic, Differential Scale., Each pair of adjective is separated by a seven point scale., , Notes, , Notes: Some individuals have favourable descriptions on the right side, while, some have on the left side. The reason for the reversal is to have a combination of both, favourable and unfavourable statements., , Semantic Differential Scale Items, Please rate the five real estate developers mentioned below on the given scales for each, of the five aspects. Developers are, S., No., , Scale items, , –3, , –2, , –1, , 0, , +1, , +2, , +3, , -, , 1., , Not reliable, , _, , _, , _, , _, , _, , _, , _, , Reliable, , 2., , Expensive, , _, , _, , _, , _, , _, , _, , _, , Not expensive, , 3., , Trustworthy, , _, , _, , _, , _, , _, , _, , _, , Not trustworthy, , 4., , Untimely delivery _, , _, , _, , _, , _, , _, , _, , Timely delivery, , 5., , Strong Brand, Image, , _, , _, , _, , _, , _, , _, , Poor brand image, , _, , The respondents were asked to tick one of the seven categories which describes, their views on attitude. Computation is being done exactly the same way as in the Likert, Scale. Suppose, we are trying to evaluate the packaging of a particular product. The, seven point scale will be as follows:, "I feel ………….., 1. Delighted, 2. Pleased, 3. Mostly satisfied, 4. Equally satisfied and dissatisfied, 5. Mostly dissatisfied, 6. Unhappy, 7. Terrible., , Thurstone Scale, This is also known as an equal appearing interval scale. The following are the steps to, construct a Thurstone Scale:, Step 1: To generate a large number of statements, relating to the attitude to be, measured., 136 Self Learning Material
Page 137 :
Step 2: These statements (75 to 100) are given to a group of judges, say 20 to Measurement and Scaling, 30, who were asked to classify them according to the degree of favourableness and, unfavourableness., Step 3: 11 piles are to be made by the judges. The piles vary from "most, unfavourable" in pile 1 to neutral in pile 6 and most favourable statement in pile 11., , Notes, , Step 4: Study the frequency distribution of ratings for each statement and eliminate, those statements, which different judges have given widely scattered ratings., Step 5: Select one or two statements from each of the 11 piles for the final scale., List the selected statements in random order to form the scale., Step 6: The respondents whose attitudes are to be scaled were given the list of, statements and asked to indicate their agreement or disagreement with each statement., Some may agree with one statement while some may agree with more than one statement., Example:, 1. Crime and violence in movies:, (a) All movies with crime and violence should be prohibited by law., (b) Watching crime and violence in movies is a waste of time., (c) Most movies with crime are bad and harmful., (d) The direction and theme in most crime movies are monotonous., (e) Watching a movie with crime and violence does not interfere with my, routine life., (f) I have no opinion one way or the other, about watching movies with crime, and violence., (g) I like to watch movies with crime and violence., (h) Most movies with crime and violence are interesting and absorbing., (i) Crime movies act as a knowledge bank gained by the audience., (j) People learn "how to be safe and protect oneself" by seeing a movie on, crime., (k) Watching crime in a movie does not harm our life-style., Conclusion: A respondent might agree with statements 8, 9 and 10. Such, agreement represents a favourable attitude towards crime and violence. On the, contrary, if items 1, 3, 4 are chosen by respondents, it shows that respondents, are unfavourably disposed towards crime in movies. If the respondent chooses, 1, 5 and 11, it could be interpreted to indicate that s(he) is not consistent in, his(her) attitude about the subject., 2. Suppose, we are interested in the attitude of certain socio-economic class of, respondents towards savings and investments. The final list of statements would, be as follows:, Self Learning Material 137
Page 138 :
Research Methodology, , (a) One should live for the present and not the future. So, savings are absolutely, not required., (b) There are many attractions to spend the money saved., (c) It is better to spend savings than risk them in investments., , Notes, , (d) Investments are unsafe as the money is also blocked., (e) You earn to spend and not to invest., (f) It is not possible to save these days., (g) A certain amount of income should be saved and invested., (h) The future is uncertain and investments will protect us., (i) Some amount of savings and investments are a must for every individual., (j) One should try to save more so that most of it could be invested., (k) All savings should be invested for the future., Conclusion: A respondent agreeing to statements 8, 9 and 11 would be, considered having a favourable attitude towards savings and investments. The, person agreeing with statements 2, 3 and 4 is an individual with an unfavourable, attitude. Also, if a respondent chooses statements 1, 3, 7 or 9, his attitude is, not considered consistent., , Multidimensional Scaling, This is used to study consumer attitudes, particularly with respect to perceptions and, preferences. These techniques help identify the product attributes that are important to, the customers and to measure their relative importance. Multi-Dimensional Scaling is, useful in studying the following:, 1. (a) What are the major attributes considered while choosing a product (soft, drinks, modes of transportation)? (b) Which attributes do customers compare, to evaluate different brands of the product? Is it price, quality, availability etc.?, 2. Which is the ideal combination of attributes according to the customer? (i.e.,, which two or more attributes consumer will consider before deciding to buy.), 3. Which advertising messages are compatible with the consumer's brand, perceptions?, The multidimensional scaling is used to describe similarity and preference of, brands. The respondents were asked to indicate their perception, or the similarity between, various objects (products, brands, etc.) and preference among objects. This scaling is, also known as perceptual mapping., There are two ways of collecting the input data to plot perceptual mapping:, 1. Non-attribute method: Here, the researcher asks the respondent to make a, judgment about the objects directly. In this method, the criteria for comparing, the objects is decided by the respondent himself., 138 Self Learning Material
Page 139 :
2. Attribute method: In this method, instead of respondents selecting the criteria, Measurement and Scaling, they were asked to compare the objects based on the criteria specified by the, researcher., Unit 5: Measurement and Scaling Technique, For example, to determine the perception of a consumer: Assume there are five, insurance companies to be evaluated on two attributes namely (1) convenient locality, (2) courteous personal service. Customers' perception regarding the five insurance, companies are as follows: Figure 5.4: Scale Evaluation, , Notes, Notes, , Scale, Evaluation, Reliability, , Validity, , Internal, Consistency, , Test-Retest, , Alternative, Forms, , Content, Criterion, Construct, Convergent, Validity, Discriminant, Validity, , 5.5.1 Reliability Analysis, , Nomological, Validity, , Figure 3.3, , A, B, C, D and E are five insurance companies., , Reliability means the extent to which the measurement process is free from errors. Reliability, 1. According, to the map, B, & scale, E are is, dissimilar, insurance, deals with accuracy, and consistency., The, said to be, reliable,companies., if it yields the same results, when repeated, arevery, made, under constant conditions., 2. Cmeasurements, is being located, conveniently., , 3. A is a less convenient in location compared to E., Example:, towards, a product, or brand, 4. Attitude, D is a less, convenient, in location, than preference., C., Reliability can, beisensured, by using location, the same, scale ontothe, 5. E, a less convenient, compared, D. same set of respondents, using the, same method. However, in actual practice, this becomes difficult as:, 1., 2., , Software such as SPSS, SAS and Excel are the packages used in MDS. Brand, Extent, to which, a scale, produces, consistent, results, positioning, research, is one, of SPSS's, important, features. SAS is a business intelligence, software. Excel, is also used, to a certain, extent., Test-retest, Reliability:, Respondents, are, administered scales at 2 different times under, , nearly equivalent conditions, , Stapel Scales, , 3., , Alternative-form Reliability: 2 equivalent forms of a scale are constructed, then tested, 1. same, Modern, versions ofat, the2 Stapel, scale, place a single adjective as a substitute for, with the, respondents, different, times, , 4., , Internal Consistency Reliability:, , the semantic differential when it is difficult to create pairs of bipolar adjectives., , (a), , 2. The advantage and disadvantages of a Stapel scale, as well as the results, are, The consistency with which each item represents the construct of interest, very similar to those for a semantic differential., , (b), , Used to assess, the reliability, summated, scale and administer., However,, the stapel, scale tendsoftoabe, easier to conduct, , (c), , Split-half Reliability, , 5., , Self Learning Material 139, Items constituting the scale divided into 2 halves, and resulting half scores are correlated:, Coefficient alpha (most common test of reliability), , 6., , Average of all possible split-half coefficients resulting from different splitting of the scale, items.
Page 140 :
Table 5.2: Basic Non-comparative Scales, , Research Methodology, Scale, , Basic, , Rating Scale, , Itemized Rating Scales, Likert Scale Degree of, agreement on a, numbered scale, Semantic, Differential, , Stapel Scale, , 3.7, , Advantages, , Characteristics, Place a mark on Reaction to TV Easy to, a continuous line commercials, construct, , Continuous, , Notes, , Examples, , Measurement, of attitudes,, perceptions, , Numbered scale, with bipolar, labels, , Brand,, product, &, company, images, , Unipolar, numbered scale,, no neutral point, , Measurement, of attitudes &, images, , Easy to, construct,, administer, &, understand, Versatile, , Easy to, construct, can, administer, over telephone, , Disadvantages, Cumbersome, scoring unless, computerized, More time, consuming, , Difficult to, construct, appropriate, bipolar, adjectives, Confusing, difficult to, apply, , Criteria for the Good Test, , There are two criteria to decide whether the scale selected is good or not. They are:, 1. Reliability; and, 2. Validity, Scale, Evaluation, Reliability, , Validity, , Internal, Consistency, , Test-Retest, , Alternative, Forms, , Content, Criterion, Construct, Convergent, Validity, Discriminant, Validity, , Figure 3.4: Scale Evaluation, 140 Self Learning Material, , Nomological, Validity
Page 141 :
Reliability Analysis, Reliability means the extent to which the measurement process is free from errors., Reliability deals with accuracy and consistency. The scale is said to be reliable, if it, yields the same results when repeated measurements are made under constant conditions., Attitude towards a product or brand preference., , Measurement and Scaling, , Notes, , Reliability can be ensured by using the same scale on the same set of respondents,, using the same method. However, in actual practice, this becomes difficult as:, 1. Extent to which a scale produces consistent results, 2. Test-retest Reliability: Respondents are administered scales at 2 different times, under nearly equivalent conditions, 3. Alternative-form Reliability: 2 equivalent forms of a scale are constructed, then, tested with the same respondents at 2 different times, 4. Internal Consistency Reliability:, (a) The consistency with which each item represents the construct of interest, (b) Used to assess the reliability of a summated scale, (c) Split-half Reliability, 5. Items constituting the scale divided into 2 halves, and resulting half scores are, correlated: Coefficient alpha (most common test of reliability), 6. Average of all possible split-half coefficients resulting from different splitting, of the scale items., , Validity Analysis, The paradigm of validity focused in the question "Are we measuring, what we think,, we are measuring?" Success of the scale lies in measuring "What is intended to be, measured?" Of the two attributes of scaling, validity is the most important., There are several methods to check the validity of the scale used for measurement:, 1. Construct Validity: A sales manager believes that there is a clear relation, between job satisfaction for a person and the degree to which a person is an, extrovert and the work performance of his sales force. Therefore, those who, enjoy high job satisfaction, and have extrovert personalities should exhibit high, performance. If they do not, then we can question the construct validity of the, measure., 2. Content Validity: A researcher should define the problem clearly. Identify the, item to be measured. Evolve a suitable scale for this purpose. Despite these, the, scale may be criticised for being lacking in content validity. Content validity is, known as face validity. An example can be the introduction of new packaged, food. When new packaged food is introduced, the product representing a major, change in taste. Thousands of consumers may be asked to taste the new packaged, Self Learning Material 141
Page 142 :
Research Methodology, , food. Overwhelmingly, people may say that they liked the new flavour. With, such a favourable reaction, the product when introduced on a commercial scale, may still meet with failure. So, what is wrong? Perhaps a crucial question that, was omitted. The people may be asked if liked the new packaged food, to which, the majority might have "yes" but the same respondents were not asked, "Are, you willing to give up the product which you are consuming currently?" In, this case, the problem was not clearly identified and the item to be 'measured', was left out., , Notes, , 3. Predictive Validity: This pertains to "How best a researcher can guess the, future performance from the knowledge of attitude score"?, Example: An opinion questionnaire, which is the basis for forecasting the, demand for a product has predictive validity. The procedure for predictive, validity is to first measure the attitude and then predict the future behaviour., Finally, this is followed by the measurement of future behaviour at an appropriate, time. Compare the two results (past and future). If the two scores are closely, associated, then the scale is said to have predictive validity., 4. Criterion Validity:, (a) Examines whether measurement scale performs as expected in relation to, other variables selected as meaningful criteria, i.e., predicted and actual, behavior should be similar, (b) Addresses the question of what construct or characteristic the scale is, actually measuring, 5. Convergent Validity: Extent to which scale correlates positively with other, measures of the same construct., 6. Discriminant Validity: Extent to which a measure does not correlate with, other constructs from which it is supposed to differ., Scale, Evaluation, Reliability, , Validity, , Internal, Consistency, , Test-Retest, , Alternative, Forms, , Content, Criterion, Construct, Convergent, Validity, Discriminant, Validity, , Figure 3.5: Reliability and Validity on Target, 142 Self Learning Material, , Nomological, Validity
Page 143 :
7. Nomological Validity: Extent to which scale correlates in theoretically predicted Measurement and Scaling, ways with measures of different but related constructs., , 3.8 Summary, Measurement can be made using nominal, ordinal, interval or ratio scale. The scales show, the extent of likes/dislikes, agreement disagreement or belief towards an object. Each of, the scale has certain statistical implications. There are four types of scales used in market, research namely paired comparison, Likert, semantic differential and thurstone scale., , Notes, , Likert is a five point scale whereas semantic differential scale is a seven point, scale. Bipolar adjectives are used in semantic differential scale., Thurstone scale is used to assess attitude of the respondents group regarding any, issue of public interest. Validity and reliability of the scale is verified before the scale, is used for measurement. Validity refers to "Does the scale measure what it intends to, measure". There are three methods to check the validity which type of validity is required, depends on "What is being measured"., , 3.9 Keywords, zz Interval, , Scale: Interval scale may tell us "How far the objects are apart with, respect to an attribute?", , zz Likert, , Scale: This consists of a series of statements concerning an attitude, object. Each statement has '5 points', Agree and Disagree on the scale., , zz Ordinal, , Scale: The ordinal scale is used for ranking in most market research, , studies., zz Ratio Scale: Ratio scale is a special kind of internal scale that has a meaningful, , zero point., zz Reliability: It means the extent to which the measurement process is free from, , errors., , 3.10 Review Questions, 1. What do you analyse as the merits of Thurstone Scale?, 2. What might be the limitations of Thurstone Scale?, 3. Which do you find to be more favorable of the attribute and non-attribute, method of perceptual mapping and why?, 4. In your opinion, what might be the uses of multi dimensional scaling?, 5. One of the limitations of MDS can be that it keeps changing from time to time., What else than this do you see as the major drawbacks it has?, 6. What can be the reasons for which you think that maintaining reliability can, become difficult?, Self Learning Material 143
Page 144 :
Research Methodology, , 7. Does measurement scale always perform as expected in relation to other variables, selected as meaningful criteria? Why/why not?, 8. On an average, how many cups of tea do you drink in a day and why? Reply, technically., , Notes, , 9. Explain the construction of, (a) Likert scale, (b) Semantic differential scale, (c) Thurstone scale, 10. Despite reliability, a scale may not have content validity. Comment., 11. Identify the type of scale, you will use in each of the following (ordinal, nominal,, internal, ratio). Justify your answer., , 3.11, , Further Readings, Murthy & U. Bhojanna, Business Research Methods, 3rd Edition, Excel, Books. Tull and Donalds, Marketing Research, MMIL., , zz S.N., , Kothari, Research Methodology, Willey International Ltd., New, , zz C.R., , Delhi, J. Goode and Paul K. Hatt, Methods in Social Research, McGraw, Hill, New Delhi, , zz William, , Moser and G. Kalton, Survey Methods in Social Investigation, , zz C.A., , Bhandar Kar and T.S. Wilkinson, Methodology and Techniques of Social, Research, Himalaya Publishing House, Delhi, , zz P.L., , Michael, Research Methodology in Management, Himalaya Publishing, House, Delhi, , zz V.P., , zz S.R., , Bajpai, Methods of Social Survey and Research, Kitab Ghar, Kanpur, , Gopal, An Introduction to Research Procedure in Social Sciences, Asian, Publishing House, Bombay, , zz M.H., , 144 Self Learning Material
Page 145 :
UNIT–4, , Analysis of Data, , Analysis of Data, , Notes, , (Structure), 4.1, , Learning Objectives, , 4.2, , Introduction, , 4.3, , Processing and Analysis of Data, , 4.4, , Processing Operations, , 4.4, , Some Problems In Processing, , 4.5, , Elements/Types of Analysis, , 4.6, , Descriptive or Summary Statistics, , 4.7, , Parametric and non-parametric tests, , 4.8, , Univariate Analyses of Parametric Data, , 4.9, , The Confidence Interval, , 4.10, , The Normal Distribution, , 4.11, , Measures of Relative Position, , 4.12, , Standard Scores (z-Scores), , 4.13, , Measures of Relationship, , 4.14, , Interpretation of Correlation Coefficient, , 4.15, , Central Limit Theorem, , 4.16, , Parametric Tests, , 4.17, , Sign Test, , 4.18, , One-sample z test, , 4.19, , One-Sample z-Test for Proportions, , 4.20, , Students’ t distribution, , 4.21, , Homogeneity of variance, , 4.22, , Analysis of Co-variance (ANOCOVA), , 4.23, , Partial Correlation, , 4.24, , Multiple Correlation and Regression, , 4.25, , Non-parametric tests, , 4.26, , Use of Statistical Software’s in Research, Self Learning Material 145
Page 146 :
Research Methodology, , 4.27 �The Statistical ProgramMe for Social Scientists (SPSS), , Notes, , 4.28, , Organization of the SPSS Package, , 4.29, , Data analysis using SPSS, , 4.30, , Using SPSS to Describe Data, , 4.31, , Summary, , 4.32, , Glossary, , 4.33, , Review Questions, , 4.34, , Further Readings, , 4.1 Learning Objectives, After studying the chapter, students will be able to:, zz Know, , what are the steps involved in processing the data;, , zz Explain, , how to edit and code the data collected;, , zz Describe, , what is tabulation and what are the kinds of tabulation;, , zz Discuss, , what is data interpretation;, , zz Various, , types of descriptive statistics;, , zz Different, zz The, , types of parametric and non-parametric tests;, , importance of normal distribution;, , zz Discuss, zz Know, , the technique of regression;, , the basic principles of the CLT;, , zz Discuss, , the use of sign test;, , zz Explain, , the use of z-test;, , zz Understand, zz Test, , the application of student’s t distribution;, , whether or not there are differences between three or more groups;, , zz Test the effect of a treatment or compare the difference in means for two groups, , when we have small sample sizes;, zz Compare and test frequencies for categorical data.Test whether or not there are, , differences between three or more groups;, zz Test the effect of a treatment or compare the difference in means for two groups, , when we have small sample sizes;, zz Compare, , and test frequencies for categorical data;, , zz Discuss, , the use of SPSS in research;, , zz Discuss, , the use of Excel in statistical data analysis;, , zz Understand, , 146 Self Learning Material, , data analysis using SPSS.
Page 147 :
4.2, , Introduction, , Processing data is very important in market research. After collecting the data, the next, task of the researcher is to analyse and interpret the data. The purpose of analysis is to, draw conclusions. There are two parts in processing the data:, 1. Data analysis, , Analysis of Data, , Notes, , 2. Interpretation of data, Analysis of the data involves organising the data in a particular manner. Interpretation, of data is a method for deriving conclusions from the data analysed. Analysis of data is, not complete, unless it is interpreted., Descriptive statistics are used to describe the basic features of the data in a study., They provide simple summaries about the sample and the measures. Together with simple, graphics analysis, they form the basis of virtually every quantitative analysis of data., Descriptive statistics are typically distinguished from inferential statistics. With, descriptive statistics you are simply describing what is or what the data shows. With, inferential statistics, you are trying to reach conclusions that extend beyond the immediate, data alone. For instance, we use inferential statistics to try to infer from the sample data, what the population might think. Or, we use inferential statistics to make judgements of, the probability that an observed difference between groups is a dependable one or one, that might have happened by chance in this study. Thus, we use inferential statistics to, make inferences from our data to more general conditions; we use descriptive statistics, simply to describe what’s going on in our data., In the previous unit, we have already discussed basic descriptive data analysis. In, this unit, we will proceed further in descriptive data analysis and discuss the measures, of relative position and measures of relationship., In this unit, you will study about percentiles, quartiles, standards score and, correlation and regression analysis. You will also learn how to interpret correlation, coefficients., The heart of statistics is inferential statistics. Descriptive statistics are typically, straight forward and easy to interpret. Unlike descriptive statistics, inferential statistics, are often complex and may have several different interpretations., The goal of inferential statistics is to discover some property or general pattern, about a large group by studying a smaller group of people in the hopes that the results, will generalise to the larger group. For example, we may ask residents of New York City, their opinion about their mayor. We would probably poll a few thousand individuals, in New York City in an attempt to find out how the city as a whole views their mayor., The following section examines how this is done., In the previous unit, we have already discussed basic descriptive data analysis. In, this unit, we will proceed further in descriptive data analysis and discuss central limit, theorem and various parametric tests., Self Learning Material 147
Page 148 :
Research Methodology, , Notes, , In the previous unit, you have already studied about basic inferential data analysis., You have studied that inferential statistics allows us to draw conclusions from data that, might not be immediately obvious. This unit will focus on enhancing your ability to, develop hypotheses and use common tests such as t-tests, ANOVA tests, and regression, to validate your claims., This unit provides an introduction to statistical analysis, particularly in regard, to survey data. Some of the features of the Statistical Package for the Social Sciences, (SPSS) are then explained, with reference to a farm forestry survey. Of necessity, this, is a brief overview to the highly complex and powerful SPSS package., , 4.3 Processing and Analysis of Data, The data, after collection, has to be processed and analysed in accordance with the outline, laid down for the purpose at the time of developing the research plan. It is essential for a, scientific study and for ensuring that we have all relevant data for making contemplated, comparisons and analysis. Technically speaking, processing implies editing, coding,, classification and tabulation of collected data so that they are amenable to analysis. The, term analysis refers to the computation of certain measures along with searching for, patterns of relationship that exist among data-groups. Thus, “in the process of analysis,, relationships or differences supporting or conflicting with original or new hypotheses, should be subjected to statistical tests of significance to determine with what validity data, can be said to indicate any conclusions”. But there are persons (Selltiz, Jahoda and others), who do not like to make difference between processing and analysis. They opine that, analysis of data in a general way involves a number of closely related operations which, are performed with the purpose of summarising the collected data and organising these, in such a manner that they answer the research question(s). We, however, shall prefer, to observe the difference between the two terms as stated here in order to understand, their implications more clearly., , 4.4 Processing Operations, With this brief introduction concerning the concepts of processing and analysis, we can, now proceed with the explanation of all the processing operations., 1. Editing: Editing of data is a process of examining the collected raw data (especially, in surveys) to detect errors and omissions and to correct these when possible. As a, matter of fact, editing involves a careful scrutiny of the completed questionnaires, and/or schedules. Editing is done to assure that the data are accurate, consistent, with other facts gathered, uniformly entered, as completed as possible and have, been well arranged to facilitate coding and tabulation., �With regard to points or stages at which editing should be done, one can talk, of field editing and central editing. Field editing consists in the review of the, 148 Self Learning Material
Page 149 :
reporting forms by the investigator for completing (translating or rewriting), what the latter has written in abbreviated and/or in illegible form at the time, of recording the respondents’ responses. This type of editing is necessary in, view of the fact that individual writing styles often can be difficult for others, to decipher. This sort of editing should be done as soon as possible after the, interview, preferably on the very day or on the next day. While doing field editing,, the investigator must restrain himself and must not correct errors of omission by, simply guessing what the informant would have said if the question had been asked., Central editing should take place when all forms or schedules have been completed, and returned to the office. This type of editing implies that all forms should get, a thorough editing by a single editor in a small study and by a team of editors in, case of a large inquiry. Editor(s) may correct the obvious errors such as an entry, in the wrong place, entry recorded in months when it should have been recorded, in weeks, and the like. In case of inappropriate on missing replies, the editor, can sometimes determine the proper answer by reviewing the other information, in the schedule. At times, the respondent can be contacted for clarification. The, editor must strike out the answer if the same is inappropriate and he has no basis, for determining the correct answer or the response. In such a case an editing, entry of ‘no answer’ is called for. All the wrong replies, which are quite obvious,, must be dropped from the final results, especially in the context of mail surveys., Editors must keep in view several points while performing their work: They should, be familiar with instructions given to the interviewers and coders as well as with, the editing instructions supplied to them for the purpose. While crossing out an, original entry for one reason or another, they should just draw a single line on it, so that the same may remain legible. They must make entries (if any) on the form, in some distinctive colur and that too in a standardised form. They should initial, all answers which they change or supply. Editor’s initials and the date of editing, should be placed on each completed form or schedule., , Analysis of Data, , Notes, , 2. Coding: Coding refers to the process of assigning numerals or other symbols, to answers so that responses can be put into a limited number of categories, or classes. Such classes should be appropriate to the research problem under, consideration. They must also possess the characteristic of exhaustiveness (i.e.,, there must be a class for every data item) and also that of mutual exclusively, which means that a specific answer can be placed in one and only one cell in, a given category set. Another rule to be observed is that of unidimensionality, by which is meant that every class is defined in terms of only one concept., Coding is necessary for efficient analysis and through it the several replies may, be reduced to a small number of classes which contain the critical information, required for analysis. Coding decisions should usually be taken at the designing, stage of the questionnaire. This makes it possible to pre code the questionnaire, Self Learning Material 149
Page 150 :
Research Methodology, , Notes, , choices and which in turn is helpful for computer tabulation as one can straight, forward key punch from the original questionnaires. But in case of hand coding, some standard method may be used. One such standard method is to code in the, margin with a coloured pencil. The other method can be to transcribe the data, from the questionnaire to a coding sheet. Whatever method is adopted, one should, see that coding errors are altogether eliminated or reduced to the minimum level., 3. Classification: Most research studies result in a large volume of raw data which, must be reduced into homogeneous groups if we are to get meaningful relationships., This fact necessitates classification of data which happens to be the process of, arranging data in groups or classes on the basis of common characteristics. Data, having a common characteristic are placed in one class and in this way the entire, data get divided into a number of groups or classes. Classification can be one of, the following two types, depending upon the nature of the phenomenon involved:, , 150 Self Learning Material, , (i), , Classification according to attributes: As stated above, data are classified, on the basis of common characteristics which can either be descriptive, (such as literacy, sex, honesty, etc.) or numerical (such as weight,, height, income, etc.). Descriptive characteristics refer to qualitative, phenomenon which cannot be measured quantitatively; only their presence, or absence in an individual item can be noticed. Data obtained this way, on the basis of certain attributes are known as statistics of attributes and, their classification is said to be classification according to attributes., Such classification can be simple classification or manifold classification., In simple classification, we consider only one attribute and divide the, universe into two classes—one class consisting of items possessing the, given attribute and the other class consisting of items which do not possess, the given attribute. But in manifold classification, we consider two or more, attributes simultaneously, and divide that data into a number of classes, (total number of classes of final order is given by 2n, where n = number of, attributes considered). Whenever data are classified according to attributes,, the researcher must see that the attributes are defined in such a manner that, there is least possibility of any doubt/ambiguity concerning the said attributes., , (ii), , Classification according to class-intervals: Unlike descriptive characteristics,, the numerical characteristics refer to quantitative phenomenon which can be, measured through some statistical units. Data relating to income, production,, age, weight, etc., come under this category. Such data are known as statistics, of variables and are classified on the basis of class intervals. For instance,, persons whose incomes, say, are within ` 201 to ` 400 can form one group,, those whose incomes are within ` 401 to ` 600 can form another group and, so on. In this way, the entire data may be divided into a number of groups, or classes or what are usually called, ‘class-intervals.’ Each group of class-
Page 151 :
interval, thus, has an upper limit as well as a lower limit which are known, as class limits. The difference between the two class limits is known as, class magnitude. We may have classes with equal class magnitudes or with, unequal class magnitudes. The number of items which fall in a given class, is known as the frequency of the given class. All the classes or groups, with, their respective frequencies taken together and put in the form of a table, are, described as group frequency distribution or simply frequency distribution., Classification according to class intervals usually involves the following, three main problems:, (a), , (b), , Analysis of Data, , Notes, , How many classes should be there and what should be their, magnitudes? There can be no specific answer with regard to, the number of classes. The decision about this calls for skill and, experience of the researcher. However, the objective should be to, display the data in such a way as to make it meaningful for the analyst., Typically, we may have 5 to 15 classes. With regard to the second part, of the question, we can say that, to the extent possible, class-intervals, should be of equal magnitudes, but in some cases unequal magnitudes, may result in better classification. Hence researcher’s objective, judgement plays an important part in this connection. Multiples of 2,, 5 and 10 are generally preferred while determining class magnitudes., Some statisticians adopt the following formula, suggested by H.A., Sturges, determining the size of class interval:, i = R/(1 + 3.3 log N), where, i = size of class interval;, R = Range (i.e., difference between the values of the largest item and, smallest item among the given items);, N = Number of items to be grouped., It should also be kept in mind that in case one or two or very few, items have very high or very low values, one may use what are known, as open-ended intervals in the overall frequency distribution. Such, intervals may be expressed like under ` 500 or ` 10001 and over. Such, intervals are generally not desirable, but often cannot be avoided. The, researcher must always remain conscious of this fact while deciding, the issue of the total number of class intervals in which the data are, to be classified., How to choose class limits?, While choosing class limits, the researcher must take into, consideration the criterion that the mid-point (generally worked out, first by taking the sum of the upper limit and lower limit of a class, Self Learning Material 151
Page 152 :
Research Methodology, , Notes, , (c), , 152 Self Learning Material, , and then divide this sum by 2) of a class-interval and the actual, average of items of that class interval should remain as close to, each other as possible. Consistent with this, the class limits should, be located at multiples of 2, 5, 10, 20, 100 and such other figures., Class limits may generally be stated in any of the following forms:, Exclusive type class intervals: They are usually stated as follows:, 10–20, 20–30, 30–40, 40–50, The above intervals should be read as under:, 10 and under 20, 20 and under 30, 30 and under 40, 40 and under 50, Thus, under the exclusive type class intervals, the items whose values, are equal to the upper limit of a class are grouped in the next higher, class. For example, an item whose value is exactly 30 would be put in, 30–40 class interval and not in 20–30 class interval. In simple words,, we can say that under exclusive type class intervals, the upper limit of a, class interval is excluded and items with values less than the upper limit, (but not less than the lower limit) are put in the given class interval., Inclusive type class intervals: They are usually stated as follows:, 11–20, 21–30, 31–40, 41–50, In inclusive type class intervals, the upper limit of a class interval is, also included in the concerning class interval. Thus, an item whose, value is 20 will be put in 11–20 class interval. The stated upper, limit of the class interval 11–20 is 20 but the real limit is 20.99999, and as such 11–20 class interval really means 11 and under 21., When the phenomenon under consideration happens to be a discrete, one (i.e., can be measured and stated only in integers), then we should, adopt inclusive type classification. But when the phenomenon happens, to be a continuous one capable of being measured in fractions as well,, we can use exclusive type class intervals., How to determine the frequency of each class?, This can be done either by tally sheets or by mechanical aids. Under, the technique of tally sheet, the class-groups are written on a sheet
Page 153 :
of paper (commonly known as the tally sheet) and for each item a, stroke (usually a small vertical line) is marked against the class group, in which it falls. The general practice is that after every four small, vertical lines in a class group, the fifth line for the item falling in the, same group is indicated as slant line through the said four lines and, the resulting figure IIII represents five items. All this facilitates the, counting of items in each one of the class groups. An illustrative tally, sheet can be shown as under:, �An Illustrative Tally Sheet for Determining the Number of 70 Families in, Different Income Groups, Income groups, , Tally mark, , Number of families or, (Class frequency), , IIII IIII III, , 13, , 401–800, , IIII IIII IIII IIII, , 20, , 801–1200, , IIII IIII III, , 12, , 1201–1600, , IIII IIII IIII III, , 18, , IIII II, , 7, , (Rupees), Below 400, , 1601 and above, Total, , Analysis of Data, , Notes, , 70, , �Alternatively, class frequencies can be determined, especially in case, of large inquires and surveys, by mechanical aids, i.e., with the help of, machines, viz., sorting machines that are available for the purpose. Some, machines are hand operated, whereas others work with electricity. There, are machines which can sort out cards at a speed of something like 25000, cards per hour. This method is fast but expensive., 4. Tabulation: When a mass of data has been assembled, it becomes necessary, for the researcher to arrange the same in some kind of concise and logical order., This procedure is referred to as tabulation. Thus, tabulation is the process of, summarising raw data and displaying the same in compact form (i.e., in the form, of statistical tables) for further analysis. In a broader sense, tabulation is an orderly, arrangement of data in columns and rows. Tabulation is essential because of the, following reasons., (i), , It conserves space and reduces explanatory and descriptive statement to a, minimum., , (ii), , It facilitates the process of comparison., Self Learning Material 153
Page 154 :
Research Methodology, , Notes, , (iii), , It facilitates the summation of items and the detection of errors and omissions., , (iv), , It provides a basis for various statistical computations., , Tabulation can be done by hand or by mechanical or electronic devices. The, choice depends on the size and type of study, cost considerations, time pressures and, the availability of tabulating machines or computers. In relatively large inquiries, we, may use mechanical or computer tabulation if other factors are favourable and necessary, facilities are available. Hand tabulation is usually preferred in case of small inquiries, where the number of questionnaires is small and they are of relatively short length., Hand tabulation may be done using the direct tally, the list and tally or the card sort, and count methods. When there are simple codes, it is feasible to tally directly from, the questionnaire. Under this method, the codes are written on a sheet of paper, called, tally sheet, and for each response a stroke is marked against the code in which it falls., Usually after every four strokes against a particular code, the fifth response is indicated, by drawing a diagonal or horizontal line through the strokes. These groups of five are, easy to count and the data are sorted against each code conveniently. In the listing, method, the code responses may be transcribed onto a large work-sheet, allowing a line, for each questionnaire. In this way, a large number of questionnaires can be listed on, one work sheet. Tallies are then made for each question. The card sorting method is the, most flexible hand tabulation. In this method, the data are recorded on special cards of, convenient size and shape with a series of holes. Each hole stands for a code and when, cards are stacked, a needle passes through particular hole representing a particular code., These cards are then separated and counted. In this way, frequencies of various codes, can be found out by the repetition of this technique. We can as well use the mechanical, devices or the computer facility for tabulation purpose in case we want quick results,, our budget permits their use and we have a large volume of straight forward tabulation, involving a number of cross-breaks., Tabulation may also be classified as simple and complex tabulation. The former, type of tabulation gives information about one or more groups of independent questions,, whereas the latter type of tabulation shows the division of data in two or more categories, and as such is designed to give information concerning one or more sets of inter-related, questions. Simple tabulation generally results in one-way tables which supply answers, to questions about one characteristic of data only. As against this, complex tabulation, usually results in two-way tables (which give information about two inter-related, characteristics of data), three-way tables (giving information about three interrelated, characteristics of data) or still higher order tables, also known as manifold tables, which, supply information about several interrelated characteristics of data. Two-way tables,, three-way tables or manifold tables are all examples of what is sometimes described, as cross tabulation., Generally accepted principles of tabulation: Such principles of tabulation,, particularly of constructing statistical tables, can be briefly stated as follows:, , 154 Self Learning Material
Page 155 :
1. Every table should have a clear, concise and adequate title so as to make the table, , Analysis of Data, , intelligible without reference to the text and this title should always be placed just, above the body of the table., 2. Every table should be given a distinct number to facilitate easy reference., 3. The column headings (captions) and the row headings (stubs) of the table should, , Notes, , be clear and brief., 4. The units of measurement under each heading or sub-heading must always be, indicated., 5. Explanatory footnotes, if any, concerning the table should be placed directly beneath, the table, along with the reference symbols used in the table., 6. Source or sources from where the data in the table have been obtained must be, indicated just below the table., 7. Usually, the columns are separated from one another by lines which make the table, more readable and attractive. Lines are always drawn at the top and bottom of the, table and below the captions., 8. There should be thick lines to separate the data under one class from the data under, another class and the lines separating the sub-divisions of the classes should be, comparatively thin lines., 9. The columns may be numbered to facilitate reference., 10. Those columns whose data are to be compared should be kept side by side. Similarly,, percentages and/or averages must also be kept close to the data., 11. It is generally considered better to approximate figures before tabulation as the, same would reduce unnecessary details in the table itself., 12. In order to emphasise the relative significance of certain categories, different kinds, of type, spacing and indentations may be used., 13. It is important that all column figures be properly aligned. Decimal points and (+), or (–) signs should be in perfect alignment., 14. Abbreviations should be avoided to the extent possible, and ditto marks should, not be used in the table., 15. Miscellaneous and exceptional items, if any, should be usually placed in the last, row of the table., 16. Table should be made as logical, clear, accurate and simple as possible. If the data, happen to be very large, they should not be crowded in a single table that would, make the table unwieldy and inconvenient., 17. Total of rows should normally be placed in the extreme right column and that of, columns should be placed at the bottom., Self Learning Material 155
Page 156 :
Research Methodology, , Notes, , 18. The arrangement of the categories in a table may be chronological, geographical,, alphabetical or according to magnitude to facilitate comparison. Above all, the, table must suit the needs and requirements of an investigation., , 4.4, , Some Problems In Processing, , We can take up the following two problems of processing the data for analytical purposes:, The problem concerning “Don’t know” (or DK) responses: While processing the, data, the researcher often comes across some responses that are difficult to handle. One, category of such responses may be ‘Don’t Know Response’ or simply DK response. When, the DK response group is small, it is of little significance. But when it is relatively big,, it becomes a matter of major concern in which case the question arises: Is the question, which elicited DK response useless? The answer depends upon two points viz., the, respondent actually may not know the answer or the researcher may fail in obtaining the, appropriate information. In the first case, the concerned question is said to be alright and, DK response is taken as legitimate DK response. But in the second case, DK response, is more likely to be a failure of the questioning process., How DK responses are to be dealt with by researchers? The best way is to design, better type of questions. Good rapport of interviewers with respondents will result in, minimising DK responses. But what about the DK responses that have already taken, place? One way to tackle this issue is to estimate the allocation of DK answers from other, data in the questionnaire. The other way is to keep DK responses as a separate category, in tabulation where we can consider it as a separate reply category if DK responses, happen to be legitimate, otherwise we should let the reader make his own decision. Yet, another way is to assume that DK responses occur more or less randomly and as such, we may distribute them among the other answers in the ratio in which the latter have, occurred. Similar results will be achieved if all DK replies are excluded from tabulation, and that too without inflating the actual number of other responses., Use of percentages: Percentages are often used in data presentation for they simplify, numbers, reducing all of them to a 0 to 100 range. Through the use of percentages,, the data are reduced in the standard form with base equal to 100 which fact facilitates, relative comparisons. While using percentages, the following rules should be kept in, view by researchers:, 1. Two or more percentages must not be averaged unless each is weighted by the, group size from which it has been derived., 2. Use of too large percentages should be avoided, since a large percentage is difficult, to understand and tends to confuse, defeating the very purpose for which percentages, are used., 3. Percentages hide the base from which they have been computed. If this is not kept, in view, the real differences may not be correctly read., 156 Self Learning Material
Page 157 :
4. Percentage decreases can never exceed 100 per cent and as such for calculating the, percentage of decrease, the higher figure should invariably be taken as the base., 5. Percentages should generally be worked out in the direction of the causal-factor, in case of two-dimension tables and for this purpose we must select the more, significant factor out of the two given factors as the causal factor., , Analysis of Data, , Notes, , 4.5 Elements/Types of Analysis, The terms “statistical analysis” and “data analysis” can be said to mean the same thing–, the study of how we describe, combine, and make inferences based on numbers. A lot, of people are scared of numbers (quantiphobia), but data analysis with statistics has got, less to do with numbers, and more to do with rules for arranging them. It even lets you, create some of those rules yourself, so instead of looking at it like a lot of memorization,, it’s best to see it as an extension of the research mentality, something researchers do, anyway (i.e., play with or crunch numbers). Once you realize that YOU have complete, and total power over how you want to arrange numbers, your fear of them will disappear., It helps, of course, if you know some basic algebra and arithmetic, at a level where, you might be comfortable solving the following equation (answer at bottom of page):, x – 3/x – 1 = x – 4/x – 5, Without statistics, all you’re doing is making educated guesses. In social science,, that may seem like all that’s necessary, since we’re studying the obvious anyway., However, there’s a difference between something socially, or meaningfully significant,, and something statistically significant. Statistical significance is first of all, short and, simple. You communicate as much with just one number as a paragraph of description., Some people don’t like statistics because of this reductionism, but it has become the, settled way researchers communicate with one another. Secondly, statistical significance, is what policy and decision making is based on. Policymakers will dismiss anything nonstatistical as anecdotal evidence. Anecdotal means something interesting and amusing, but, hardly serious enough to be published or promulgated. Finally, just because something, is statistically significant doesn’t make it true. It’s better than guessing, but you can lie, and deceive with statistics. Since they can mislead you, there’s no substitute for knowing, something about the topic so that, as is the most common interpretative approach, the, researcher is able to say what is both meaningful and statistically significant. , There are three general areas that make up the field of statistics: descriptive statistics,, relational statistics, and inferential statistics., 1. Descriptive Statistics Fall into One of Two Categories: measures of central, tendency (mean, median, and mode) or measures of dispersion (standard deviation, and variance). Their purpose is to explore hunches that may have come up during, the course of the research process, but most people compute them to look at the, Self Learning Material 157
Page 158 :
Research Methodology, , normality of their numbers. Examples include descriptive analysis of sex, age,, race, social class, and so forth. , 2. Relational Statistics Fall into One of Three Categories: univariate, bivariate,, and multivariate analysis. Univariate analysis is the study of one variable for a, subpopulation, for example, age of murderers, and the analysis is often descriptive,, but you’d be surprised how many advanced statistics can be computed using just, one variable. Bivariate analysis is the study of a relationship between two variables,, for example, murder and meanness, and the most commonly known technique here, is correlation. Multivariate analysis is the study of relationship between three or, more variables, for example, murder, meanness, and gun ownership, and for all, techniques in this area, you simply take the word “multiple” and put it in front of, the bivariate technique used, as in multiple correlation., , Notes, , 3. Inferential Statistics, also called Inductive Statistics, Fall into One of Two, Categories: Tests for difference of means and tests for statistical significance, the, latter which are further subdivided into parametric or non-parametric, depending, upon whether you’re inferring to the larger population as a whole (parametric) or, the people in your sample (non-parametric). The purpose of difference of means, tests is to test hypotheses, and the most common techniques are called Z-tests. The, most common parametric tests of significance are the F-test, t-test, ANOVA, and, regression. The most common non-parametric tests of significance are chi-square,, the Mann-Whitney U-test, and the Kruskal-Wallis test. To summarize:, , 4.6, , (i), , Descriptive statistics (mean, median, mode; standard deviation, variance), , (ii), , Relational statistics (correlation, multiple correlation), , (iii), , Inferential tests for difference of means (Z-tests), , (iv), , Inferential parametric tests for significance (F-tests, t-tests, ANOVA,, regression), , (v), , Inferential non-parametric tests for significance (chi-square, Mann-Whitney,, Kruskal-Wallis) , , Descriptive or Summary Statistics, , Quantitative research may well generate masses of data. For example, a comparatively, small study that distributes 200 questionnaires with maybe 20 items on each can generate, potentially 4000 items of raw data., To make sense of this data it needs to be summarised in some way, so that the, reader has an idea of the typical values in the data, and how these vary. To do this,, researchers use descriptive or summary statistics, they describe or summarise the data,, so that the reader can construct a mental picture of the data and the people, events or, objects they relate to., 158 Self Learning Material
Page 159 :
Types of Descriptive Statistics, All quantitative studies will have some descriptive statistics, as well as frequency tables., For example, sample size, maximum and minimum values, averages and measures of, variation of the data about the average. In many studies this is a first step, prior to more, complex inferential analysis., , Analysis of Data, , Notes, , The two main types of descriptive statistics encountered in research papers are:, zz Measures, , of central tendency, (averages) and, , zz Measures, , of dispersion., , Note: The choice of particular descriptive statistics for reporting will affect the, “picture” presented by the data, and there is the potential to mislead., Measures of Central Tendency, The Mean, Possibly the most widely known measure of centre or average is the MEAN, sometimes, known as the arithmetic mean., The mean is calculated by adding together all the measurements and dividing by, the total number of measurements., For example, the mean or average quiz score is determined by summing all the, scores and dividing by the number of students taking the exam. For example, consider, the test score values:, 15, 20, 21, 20, 36, 15, 25, 15, The sum of these 8 values is 167, so the mean is 167/8 = 20.875., Most packages (and hand held calculators) have a facility for automatically, calculating the mean of a set of values., The Median, Another common measure of central tendency is MEDIAN. This is the value that falls, halfway along the frequency distribution, the ‘middle value’. This is the value that falls, halfway along the frequency distribution. If the data are sorted into order, from smallest, to largest, the median is the number such that 50% of the values are higher than this, number and 50% are lower. It is sometimes known as the 50th centile., If, there is an odd number of values, the median will take one of those values. For, example, if there are 21 values then the 11th highest value will have 10 less than and, 10 greater than it. Hence the 11th highest value of a set consisting of 21 values will be, the median., If there is an even number of values, the median will lie halfway between two of, those values. For example, if there are 20 values then the median will lie between 10th, and 11th highest values, since 10 measurements are less than this and 10 are greater., Self Learning Material 159
Page 160 :
Research Methodology Hence the mean of the 10th and 11th highest values in a set consisting of 20 values, will be the median. (Add together the 10th and 11th highest values and divide by 2)., , Notes, , The median is the number that falls in the middle of a range of numbers. It’s not, the average; it’s the halfway point. There are always just as many numbers above the, median as below it. In cases where there is an even set of numbers, you average the, two middle numbers. The median is best suited for data that are ordinal, or ranked. It, is also useful when you have extremely low or high scores., Mode, The mode is the most frequently occurring number in a list of numbers. It’s the closest, thing to what people mean when they say something is average or typical. The mode, doesn’t even have to be a number. It will be a category when the data are nominal or, qualitative. The mode is useful when you have a highly skewed set of numbers, mostly, low or mostly high. You can also have two modes (bimodal distribution) when one group, of scores are mostly low and the other group is mostly high, with few in the middle., Measures of Dispersion, In data analysis, the purpose of statistically computing a measure of dispersion is to, discover the extent to which scores differ, cluster, or spread from around a measure, of central tendency. The most commonly used measure of dispersion is the standard, deviation. You first compute the variance, which is calculated by subtracting the mean, from each number, squaring it, and dividing the grand total (Sum of Squares) by how, many numbers there are. The square root of the variance is the standard deviation. , , Standard Deviation, The Standard Deviation is a more accurate and detailed estimate of dispersion because, an outlier can greatly exaggerate the range (as was true in this example where the single, outlier value of 36 stands apart from the rest of the values. The Standard Deviation, shows the relation that set of scores has to the mean of the sample. Again let’s take the, set of scores:, 15,20,21,20,36,15,25,15, to compute the standard deviation, we first find the distance between each value, and the mean. We know from above that the mean is 20.875. So, the differences from, the mean are:, 15 – 20.875 = –5.875, 20 – 20.875 = –0.875, 21 – 20.875 = +0.125, 20 – 20.875 = –0.875, 36 – 20.875 = 15.125, 160 Self Learning Material
Page 161 :
15 – 20.875 = –5.875, , Analysis of Data, , 25 – 20.875 = +4.125, 15 – 20.875 = –5.875, Notice that values that are below the mean have negative discrepancies and values, above it have positive ones. Next, we square each discrepancy:, , Notes, , –5.875 * –5.875 = 34.515625, –0.875 * –0.875 = 0.765625, +0.125 * +0.125 = 0.015625, –0.875 * –0.875 = 0.765625, 15.125 * 15.125 = 228.765625, –5.875 * –5.875 = 34.515625, +4.125 * +4.125 = 17.015625, –5.875 * –5.875 = 34.515625, Now, we take these “squares” and sum them to get the Sum of Squares (SS) value., Here, the sum is 350.875. Next, we divide this sum by the number of scores minus 1., Here, the result is 350.875 / 7 = 50.125. This value is known as the variance. To get the, standard deviation, we take the square root of the variance (remember that we squared, the deviations earlier). This would be SQRT(50.125) = 7.079901129253., Although this computation may seem convoluted, it’s actually quite simple. To, see this, consider the formula for the standard deviation:, –, S(X – X)2, (n – 1), where:, X = each score, –, X = the mean or average, n = the number of values, S means we sum across the values, In the top part of the ratio, the numerator, we see that each score has the the mean, subtracted from it, the difference is squared, and the squares are summed. In the bottom, part, we take the number of scores minus 1. The ratio is the variance and the square, root is the standard deviation. In English, we can describe the standard deviation as:, the square root of the sum of the squared deviations from the mean divided by, the number of scores minus one., Although we can calculate these univariate statistics by hand, it gets quite tedious, when you have more than a few values and variables. Every statistics programme is, capable of calculating them easily for you. For instance, I put the eight scores into, SPSS and got the following table as a result:, Self Learning Material 161
Page 162 :
Research Methodology, , N, Mean, Median, Mode, Std. Deviation, Variance, Range, , Notes, , 8, 20.8750, 20.0000, 15.00, 7.0799, 50.1250, 21.00, , which confirms the calculations I did by hand above., The standard deviation is important for many reasons. One reason is that, once you, know the standard deviation, you can standardize by it. Standardization is the process, of converting raw scores into what are called standard scores, which allow you to better, compare groups of different sizes. Standardization isn’t required for data analysis, but, it becomes useful when you want to compare different subgroups in your sample, or, between groups in different studies., A standard score is called a z-score (not to be confused with a z-test), and is, calculated by subtracting the mean from each and every number and dividing by the, standard deviation. Once you have converted your data into standard scores, you can, then use probability tables that exist for estimating the likelihood that a certain raw, score will appear in the population. This is an example of using a descriptive statistic, (standard deviation) for inferential purposes. , , 4.7, , Parametric and non-parametric tests, , Parametric Tests, Parametric tests usually assume certain properties of the parent population from which, we draw samples. Assumptions like observations come from a normal population,, sample size is large, assumptions about the population parameters like mean, variance,, etc., must hold good before parametric tests can be used., But there are situations when the researcher cannot or does not want to make such, assumptions. In such situations, we use statistical methods for testing hypotheses which, are called non-parametric tests because such tests do not depend on any assumption, about the parameters of the parent population. Besides, most non-parametric tests assume, only nominal or ordinal data, whereas parametric tests require measurement equivalent, to at least an interval scale. As a result, non-parametric tests need more observations, than parametric tests to achieve the same size of Type I and Type II errors. We take up, in the present unit some of the important parametric tests, whereas non-parametric tests, will be dealt with in a separate unit later in the book., The important parametric tests are:, 1. z-test;, 162 Self Learning Material
Page 163 :
2. t-test;, , Analysis of Data, , 3. χ2-test, and, 4. F-test., All these tests are based on the assumption of normality i.e., the source of data is, considered to be normally distributed., , Notes, , In some cases the population may not be normally distributed, yet the tests will, be applicable on account of the fact that we mostly deal with samples and the sampling, distributions closely approach normal distributions., 1. z-test is based on the normal probability distribution and is used for judging the, significance of several statistical measures, particularly the mean. The relevant, test statistic, z, is worked out and compared with its probable value (to be read, from table showing area under normal curve) at a specified level of significance, for judging the significance of the measure concerned. This is a most frequently, used test in research studies. This test is used even when binomial distribution or, t-distribution is applicable on the presumption that such a distribution tends to, approximate normal distribution as ‘n’ becomes larger. z-test is generally used for, comparing the mean of a sample to some hypothesised mean for the population in, case of large sample, or when population variance is known. z-test is also used for, judging the significance of difference between means of two independent samples, in case of large samples, or when population variance is known. z-test is also used, for comparing the sample proportion to a theoretical value of population proportion, or for judging the difference in proportions of two independent samples when ‘n’, happens to be large. Besides, this test may be used for judging the significance of, median, mode, coefficient of correlation and several other measures., 2. t-test is based on t-distribution and is considered an appropriate test for judging the, significance of a sample mean or for judging the significance of difference between, the means of two samples in case of small sample(s) when population variance, is not known (in such a case we use variance of the sample as an estimate of the, population variance). In case two samples are related, we use paired t-test (or what, is known as difference test) for judging the significance of the mean of difference, between the two related samples. It can also be used for judging the significance, of the coefficients of simple and partial correlations. The relevant test statistic,, t, is calculated from the sample data and then compared with its probable value, based on t-distribution (to be read from the table that gives probable values of t for, different levels of significance for different degrees of freedom) at a specified level, of significance for concerning degrees of freedom for accepting or rejecting the, null hypothesis. It may be noted that t-test applies only in case of small sample(s), when population variance is unknown., Self Learning Material 163
Page 164 :
Research Methodology, , 3. χ2-test is based on chi-square distribution and as a parametric test is used for, comparing a sample variance to a theoretical population variance., 4. F-test is based on F-distribution and is used to compare the variance of the twoindependent samples. This test is also used in the context of analysis of variance, (ANOVA) for judging the significance of more than two sample means at one and, the same time. It is also used for judging the significance of multiple correlation, coefficients. Test statistic, F, is calculated and compared with its probable value, (to be seen in the F-ratio tables for different degrees of freedom for greater and, smaller variances at specified level of significance) for accepting or rejecting the, null hypothesis., , Notes, , Non-Parametric Tests, Non-parametric methods are often called distribution-free methods because the inferences, are based on a test statistic whose sampling distribution does not depend upon the, specific distribution of the population from which the sample is drawn (Gibbons, 1993,, p., 2). Thus, the methods of hypothesis testing and estimation are valid under much, less restrictive assumptions than classical parametric techniques—such as independent, random samples drawn from normal distributions with equal variances, interval level, measurement. These techniques are appropriate for many marketing applications where, measurement is often at ordinal or nominal level., There are many parametric and non-parametric tests. The one that is appropriate, for analyzing a set of data depends on: (1) the level of measurement of the data, (2) the, number of variables that are involved, and for multiple variables, how they are assumed, to be related. As measurement scales become more restrictive and move from nominal, to ordinal, and interval levels of measurement, the amount of information and power to, extract that information from the scale increases., Corresponding to this spectrum of available information is an array of nonparametric and parametric statistical techniques that focus on describing (i.e., measures, of central tendency and dispersion) and making inferences about the variables contained, in the analysis—i.e., tests of statistical significance (as shown in Table below)., Level of Measurement, What types of, Nominal, analysis do you want?, Measure of central, Mode, tendency, Measure of Dispersion None, One-sample test of, statistical significance, , Binomial test, n2 one-sample, test, , 164 Self Learning Material, , Ordinal, Median, Percentile, Kolmogo, rov-Smirnov, On-sample test, One-sample runs, test, , Interval, (Parametric), Mean, Standard, Deviation, t-test, z-test
Page 165 :
Our discussion of statistical inference has emphasized that analytical procedures, require assumptions about the distribution of the population of interest. For example,, for normally distributed variables, we assume normality and homogeneity of variances., When a variable to be analyzed conforms to the assumptions of a given distribution, the, distribution of the variable can be expressed in terms of its parameters (μ and s). This, process of making inferences from the sample to the population’s parameters is called, parametric analysis. Sometimes, however, problems occur: what if we cannot assume, normality, or we must question the measurement scale used. Parametric methods rely, almost exclusively on either interval or ratio scaled data. In cases where data can be, obtained only using ordinal or categorical scales the interpretation of the results may be, questionable especially if the ordinal categories are not of equal interval. When data do, not meet the rigorous assumptions of parametric method, we must rely on non-parametric, methods which free us of the assumptions about the distribution., , Analysis of Data, , Notes, , The parametric methods make inferences about parameters of the population (μ, and s), non-parametric methods may be used to compare entire distributions that are, based on nominal data. Other non-parametric methods that use an ordinal measurement, scale test for the ordering of observations in the data set., Problems that may be solved with parametric methods may often be solved by a, non-parametric method designed to address a similar question. Often, the researcher will, find that the same conclusion regarding significance is made when data are analysed, by a parametric method and by its “corresponding” non-parametric method. Now, we, will discuss the univariate parametric and non-parametric analyses. In the next section,, bivariate parametric and non-parametric analyses are presented., , 4.8 Univariate Analyses of Parametric Data, Marketing researchers are often concerned with estimating parameters of a population., In addition, many studies go beyond estimation and compare population parameters, by testing hypotheses about differences between them. Often, the means, proportions, and variances are the summary measures of concern. Our concern at this point is with, differences between the means and proportions of the sample and those of the population, as a whole., , 4.9 The Confidence Interval, The concept of a confidence interval is central to all parametric hypothesis testing., The confidence interval is a range of values with a given probability (.95, .99, etc.) of, covering the true population parameter., , 4.10 The Normal Distribution, Some shapes of frequency distribution have special names since they are quite common., The best known and most useful is called the normal distribution. The standard deviation, is a particularly useful measure if the data is normally distributed., Self Learning Material 165
Page 166 :
Research Methodology, , Notes, 4.1: The Normal Distribution is Symmetric and Bell-shaped, Many variables follow this distribution:, E.g., , 10,000, , Frequency, , 8,000, 6,000, 4,000, 2,000, 0, 55, , 60, , 65, , 70, , 75, , 80, , Height (in), , 4.2: A Distribution of Heights in Young Adult Males with an Approximating, Normal Distribution {Martin, 1949, Table 17(Grade 1)}., 30, , Frequency, , 20, , 10, , 40, , 50, , 60, , 70, , 80, , Diastolic blood pressure (mm Hg), , 4.3: A Distribution of Diastolic Blood Pressures of Schoolboys with an, Approximating Normal Distribution Rose, 1962, Table 1), 166 Self Learning Material
Page 167 :
Analysis of Data, , 30, , Frequency, , 24, , Notes, , 18, , 12, , 6, , 0, , 0.9, , 2.1, , 3.3, 4.5, log (serum bilirubin), , 5.7, , 6.9, , 4.4: Log (serum bilirubin) Values in 216 Patients with Primary Biliary Cirrhosis, The normal distribution is by definition symmetric with most values towards the, centre and with values tailing off evenly in either direction. Because of the symmetry, of the distribution, the mean always lies in the centre of the distribution (where the, peak is). The standard deviation of the distribution tells us how spread the values are, around the mean., As the mean and standard deviation change, the distribution may alter its’ position, on the horizontal axis, become ‘taller and thinner’ or ‘shorter and fatter’:-, , Mean, , Fig. 4.5, Effect of reducing mean:, , Shift to the left, Mean, , Fig. 4.6, Self Learning Material 167
Page 168 :
Research Methodology Effect of decreasing standard deviation:, , Distribution ‘latter and thinner’, , Notes, , Mean, , Fig. 4.7, If we know that a variable is normally distributed and we know the mean and, standard deviation of the distribution, we have complete information about the values, taken and the frequency with which they occur., 95% of the values in the distribution will lie within a range ± 1.96 standard deviations, either side of the mean, 68% will lie within ± 1 standard deviation., Since 1.96 is so close to 2, it is common for ease of calculation to construct the interval, ± 2 standard deviations either side of the mean and this will contain approximately 95%, of the values., For example: Suppose the heights of 5 year old children are normally distributed, with mean 100 cm and standard deviation 10 cm and that the heights are known to be, normally distributed. Approximately 95% of the values will lie in the interval ± 2 standard, deviations (= 2 × 10 = 20 cm) either side of the mean (100 cm). This interval is (100 ±, 20) = (80, 120 cm). So, approximately 95% (or 19 out of every 20) of 5 year old children, lies within this height range. The remaining 5% (or 1 in 20) will be either shorter than, 80 cm or taller than 120 cm. The symmetry of the distribution means that 2.5% (1 in, 40) will be shorter than 80 cm and the other 2.5% (1 in 40) will be taller than 120 cm., , Normal Tables, It is possible to quantify the exact percentage of values that lie within a selected number, of standard deviations either side of the mean. The range is from 0% at 0 standard, deviations either side up to 100% for an infinite number of standard deviations either side., The greater the number of standard deviations, the greater the percentage contained. The, percentage contained can be automatically calculated using the linked excel spreadsheet., The table given below shows the percentages contained within intervals for, selected numbers of standard deviations either side of the mean. The table also gives the, proportions excluded on each side. The last two columns are readily calculated from the, information given in the ‘% contained in interval column’. For example, the table shows, that 99% of the values lies within the interval (mean ± 2.58 standard deviations), this, implies that 1% lies outside this interval and this will be 0.5% either side. In the table, the 1% and 0.5% are expressed as proportions (0.01 and 0.005 respectively)., 168 Self Learning Material
Page 169 :
Table 4.1: Normal Distribution, , Analysis of Data, , Notes, No. of standard, deviations, 3.09, 2.58, 2.33, 1.96, 1.64, 1.28, 0.84, 0.52, 0.25, , % contained in, interval, 99.8, 99, 98, 95, 90, 80, 60, 40, 20, , 1-sided p-value, , 2-sided p-value, , 0.001, 0.005, 0.01, 0.025, 0.05, 0.1, 0.2, 0.3, 0.4, , 0.002, 0.01, 0.02, 0.05, 0.1, 0.2, 0.4, 0.6, 0.8, , Note: At this stage p-values have not been introduced and the headings for the last two, columns (‘1-sided p-value’ and ‘2-sided p-value’) may be meaningless. The table given, above will be referred back to in later Units and these headings should then be useful., A further spreadsheet can be used to obtain these values., , 4.11, , Measures of Relative Position, , Statisticians often talk about the position of a value, relative to other values in a set of, observations. The most common measures of position are percentiles, quartiles, and, standard scores (aka, z-scores)., Percentiles, Assume that the elements in a data set are rank ordered from the smallest to the largest., The values that divide a rank-ordered set of elements into 100 equal parts are called, percentiles., An element having a percentile rank of Pi would have a greater value than i percent, of all the elements in the set. Thus, the observation at the 50th percentile would be denoted, P50, and it would be greater than 50 % of the observations in the set. An observation, at the 50th percentile would correspond to the median value in the set., Quartiles, Quartiles divide a rank-ordered data set into four equal parts. The values that divide, each part are called the first, second, and third quartiles; and they are denoted by Q1,, Self Learning Material 169
Page 170 :
Research Methodology Q2, and Q3, respectively. Note the relationship between quartiles and percentiles. Q1, corresponds to P25, Q2 corresponds to P50, Q3 corresponds to P75. Q2 is the median, value in the set., , Notes, , 4.12, , Standard Scores (z-Scores), , A standard score (aka, a z-score) indicates how many standard deviations an element is, from the mean. A standard score can be calculated from the following formula., z = (X – μ) / σ, Where z is the z-score, X is the value of the element, μ is the mean of the population,, and σ is the standard deviation., , Here is How to Interpret Z-scores, 1. A z-score less than 0 represents an element less than the mean., 2. A z-score greater than 0 represents an element greater than the mean., 3. A z-score equal to 0 represents an element equal to the mean., 4. A z-score equal to 1 represents an element that is 1 standard deviation greater than, the mean; a z-score equal to 2, 2 standard deviations greater than the mean; etc., 5. A z-score equal to –1 represents an element that is 1 standard deviation less than, the mean; a z-score equal to –2, 2 standard deviations less than the mean; etc., , 4.13, , Measures of Relationship, , When data are obtained for two or more traits on the same sample, it may be important to, discover whether there is a relationship between the measures. For example, statisticians, may try to answer questions such as the following: Is there a relationship between a, person’s height and weight? Can one judge a person’s intelligence from any physical, characteristic? Is personality related to job success? How consistent are repeated measures, of achievement in school? Is income related to how far a person went in school? Can one, predict a person’s reading comprehension from reading speed or word comprehension?, Correlation and Regression, Correlation and linear regression are the most commonly used techniques for investigating, the relationship between two quantitative variables., The goal of a correlation analysis is to see whether two measurement variables, vary, and to quantify the strength of the relationship between the variables, whereas, regression expresses the relationship in the form of an equation., For example, in students taking a Maths and English test, we could use correlation to, determine whether students who are good at Maths tend to be good at English as well,, and regression to determine whether the marks in English can be predicted for given, marks in Maths., 170 Self Learning Material
Page 171 :
What a Scatter Diagram Tells Us, , Analysis of Data, , The starting point is to draw a scatter of points on a graph, with one variable on the, X-axis and the other variable on the Y-axis, to get a feel of the relationship (if any), between the variables as suggested by the data. The closer the points are to a straight, line, the stronger the linear relationship between two variables., , Notes, , Why Use Correlation?, We can use the correlation coefficient, such as the Pearson Product Moment Correlation, Coefficient, to test if there is a linear relationship between the variables. To quantify the, strength of the relationship, we can calculate the correlation coefficient (r). Its numerical, value ranges from +1.0 to –1.0. r > 0 indicates positive linear relationship, r < 0 indicates, negative linear relationship while r = 0 indicates no linear relationship., , A Caveat, It must, however, be considered that there may be a third variable related to both of, the variables being investigated, which is responsible for the apparent correlation., Correlation, also, a nonlinear relationship may exist between two variables that would, be inadequately described, or possibly even undetected, by the correlation coefficient., , Cause, (independent variable), , Effect/outcome, (dependent variable), , Other Factors, (confounding variable), , Fig. 4.8, , Why Use Regression, In regression analysis, the problem of interest is the nature of the relationship itself, between the dependent variable (response) and the (explanatory) independent variable., The analysis consists of choosing and fitting an appropriate model, done by the, method of least squares, with a view to exploiting the relationship between the variables to, help estimate the expected response for a given value of the independent variable. For, example, if we are interested in the effect of age on height, then by fitting a regression, line, we can predict the height for a given age., Self Learning Material 171
Page 172 :
Research Methodology Assumptions, Some underlying assumptions governing the uses of correlation and regression are as, follows., , Notes, , The observations are assumed to be independent. For correlation, both variables, should be random variables, but for regression only the dependent variable Y must be, random. In carrying out hypothesis tests, the response variable should follow Normal, distribution and the variability of Y should be the same for each value of the predictor, variable. A scatter diagram of the data provides an initial check of the assumptions for, regression., , Uses of Correlation and Regression, There are three main uses for correlation and regression., zz One, , is to test hypotheses about cause-and-effect relationships. In this case, the, experimenter determines the values of the X-variable and sees whether variation, in X causes variation in Y. For example, giving people different amounts of a, drug and measuring their blood pressure., , zz The, , second main use for correlation and regression is to see whether two, variables are associated, without necessarily inferring a cause-and-effect, relationship. In this case, neither variable is determined by the experimenter;, both are naturally variable. If an association is found, the inference is that, variation in X may cause variation in Y, or variation in Y may cause variation, in X, or variation in some other factor may affect both X and Y., , zz The third common use of linear regression is estimating the value of one variable, , corresponding to a particular value of the other variable., Linear Regression Analysis, Linear regression analysis is a powerful technique used for predicting the unknown, value of a variable from the known value of another variable. More precisely, if X and, Y are two related variables, then linear regression analysis helps us to predict the value, of Y for a given value of X or vice-verse., For example, age of a human being and maturity are related variables. Then linear, regression analyses can predict level of maturity given age of a human being., , Dependent and Independent Variables, By linear regression, we mean models with just one independent and one dependent, variable. The variable whose value is to be predicted is known as the dependent, variable and the one whose known value is used for prediction is known as the independent, variable., 172 Self Learning Material
Page 173 :
Two Lines of Regression, There are two lines of regression–that of Y on X and X on Y. The line of regression, of Y on X is given by Y = a + bX where ‘a’ and ‘b’ are unknown constants known as, intercept and slope of the equation. This is used to predict the unknown value of variable, Y when value of variable X is known., , Analysis of Data, , Notes, , Y = a + bX, On the other hand, the line of regression of X on Y is given by X = c + dY which, is used to predict the unknown value of variable X using the known value of variable, Y. Often, only one of these lines make sense., Exactly, which of these will be appropriate for the analysis in hand will depend on, labelling of dependent and independent variable in the problem to be analysed., , Choice of Line of Regression, For example, consider two variables crop yield (Y) and rainfall (X). Here construction, of regression line of Y on X would make sense and would be able to demonstrate the, dependence of crop yield on rainfall. We would then be able to estimate crop yield, given rainfall., Careless use of linear regression analysis could mean construction of regression line, of X on Y which would demonstrate the laughable scenario that rainfall is dependent on, crop yield; this would suggest that if you grow really big crops you will be guaranteed, a heavy rainfall., , Regression Coefficient, The coefficient of X in the line of regression of Y on X is called the regression coefficient, of Y on X. It represents change in the value of dependent variable (Y) corresponding to, unit change in the value of independent variable (X)., For instance if the regression coefficient of Y on X is 0.53 units, it would indicate, that Y will increase by 0.53 if X increased by 1 unit. A similar interpretation can be, given for the regression coefficient of X on Y., Once a line of regression has been constructed, one can check how good it is (in, terms of predictive ability) by examining the coefficient of determination (R2). R2 always, lies between 0 and 1. All software provides it whenever regression procedure is run., , R2—coefficient of Determination, The closer R2 is to 1, the better is the model and its prediction. A related question, is whether the independent variable significantly influences the dependent variable., Statistically, it is equivalent to test the null hypothesis that the regression coefficient is, zero. This can be done using t-test., Self Learning Material 173
Page 174 :
Research Methodology Assumption of Linearity, , Notes, , Linear regression does not test whether data is linear. It finds the slope and the intercept, assuming that the relationship between the independent and dependent variable can be best, explained by a straight line. One can construct the scatter plot to confirm this assumption., If the scatter plot reveals nonlinear relationship, often a suitable transformation can be, used to attain linearity., These questions are examples of correlation, or relationship, problems. In every, case, there has to be a pair of measurements for each person in the group before one, can measure the correlation. For example, to determine the correlation between height, and weight for high-school students, each student’s height and weight must be known., By tabulating each pair of measurements on a scattergram, or scatter diagram, a visual, idea of the correlation is possible., , Correlation, Statistical correlation is a statistical technique which tells us if two variables are related., For example, consider the variables family income and family expenditure. It is, well known that income and expenditure increase or decrease together. Thus they are, related in the sense that change in any one variable is accompanied by change in the, other variable., Again price and demand of a commodity are related variables; when price increases, demand will tend to decrease and vice versa., If the change in one variable is accompanied by a change in the other, the variables, are said to be correlated. We can therefore say that family income and family expenditure,, price and demand are correlated., , Relationship between Variables, Correlation can tell you something about the relationship between variables. It is used, to understand:, 1. Whether the relationship is positive or negative, 2. The strength of relationship., Correlation is a powerful tool that provides these vital pieces of information., In the case of family income and family expenditure, it is easy to see that they both, rise or fall together in the same direction. This is called positive correlation., In case of price and demand, change occurs in the opposite direction so that increase, in one is accompanied by decrease in the other. This is called negative correlation., , Coefficient of Correlation, Statistical correlation is measured by what is called coefficient of correlation (r). Its numerical, value ranges from +1.0 to –1.0. It gives us an indication of the strength of relationship., 174 Self Learning Material
Page 175 :
In general, r > 0 indicates positive relationship, r < 0 indicates negative relationship, while r = 0 indicates no relationship (or that the variables are independent and not, related). Here r = +1.0 describes a perfect positive correlation and r = –1.0 describes, a perfect negative correlation., Closer the coefficients are to +1.0 and –1.0; greater is the strength of the relationship, between the variables., , Analysis of Data, , Notes, , As a rule of thumb, the following guidelines on strength of relationship are often, useful (though many experts would somewhat disagree on the choice of boundaries)., Value of r, , Strength of relationship, , –1.0 to –0.5 or 1.0 to 0.5, , Strong, , –0.5 to –0.3 or 0.3 to 0.5, , Moderate, , –0.3 to –0.1 or 0.1 to 0.3, , Weak, , –0.1 to 0.1, , None or very weak, , Correlation is only appropriate for examining the relationship between meaningful, quantifiable data (e.g., air pressure and temperature) rather than categorical data such, as gender, favorite colour, etc., , Disadvantages, While ‘r’ (correlation coefficient) is a powerful tool, it has to be handled with care., 1. The most used correlation coefficients only measure linear relationship. It is, therefore perfectly possible that while there is strong nonlinear relationship between, the variables, r is close to 0 or even 0. In such a case, a scatter diagram can roughly, indicate the existence or otherwise of a nonlinear relationship., 2. One has to be careful in interpreting the value of ‘r’. For example, one could, compute ‘r’ between the size of shoe and intelligence of individuals, heights and, income. Irrespective of the value of ‘r’, it makes no sense and is hence termed, chance or non-sense correlation., 3. ‘r’ should not be used to say anything about cause and effect relationship. Put, differently, by examining the value of ‘r’, we could conclude that variables X and, Y are related. However, the same value of ‘r’ does not tell us if X influences Y or, the other way round. Statistical correlation should not be the primary tool used, to study causation, because of the problem with third variables., , Pearson Product-Moment Correlation, Pearson Product-Moment Correlation is one of the measures of correlation which, quantifies the strength as well as direction of such relationship. It is usually denoted, by Greek letter ρ., In the study of relationships, two variables are said to be correlated if change in one, variable is accompanied by change in the other either in the same or reverse direction., Self Learning Material 175
Page 176 :
Research Methodology Conditions, This coefficient is used if two conditions are satisfied, 1. the variables are in the interval or ratio scale of measurement, , Notes, , 2. a linear relationship between them is suspected, , Positive and Negative Correlation, The coefficient (ρ) is computed as the ratio of covariance between the variables to the, product of their standard deviations. This formulation is advantageous., First, it tells us the direction of relationship. Once the coefficient is computed, ρ > 0, will indicate positive relationship, ρ < 0 will indicate negative relationship while ρ = 0, indicates non-existence of any relationship., Second, it ensures (mathematically) that the numerical value of ρ ranges from, –1.0 to +1.0. This enables us to get an idea of the strength of relationship – or rather, the strength of linear relationship between the variables. The closer the coefficients are, to +1.0 or –1.0, the greater is the strength of the linear relationship., , Properties of Ρ, This measure of correlation has interesting properties, some of which are enunciated, below:, 1. It is independent of the units of measurement. It is in fact unit free. For example,, ρ between highest day temperature (in Centigrade) and rainfall per day (in mm) is, not expressed either in terms of centigrade or mm., 2. It is symmetric. This means that ρ between X and Y is exactly the same as ρ, between Y and X., 3. Pearson’s correlation coefficient is independent of change in origin and scale. Thus, ρ between temperature (in Centigrade) and rainfall (in mm) would numerically be, equal to ρ between temperature (in Fahrenheit) and rainfall (in cm)., 4. If the variables are independent of each other, one would obtain ρ = 0. However,, the converse is not true. In other words, ρ = 0 does not imply that the variables, are independent – it only indicates the non-existence of a non-linear relationship., , Caveats and Warnings, While ρ is a powerful tool, it is a much abused one and hence has to be handled carefully., 1. People often tend to forget or gloss over the fact that ρ is a measure of linear, relationship. Consequently, a small value of ρ is often interpreted to mean, nonexistence of relationship when actually it only indicates nonexistence of a linear, relationship or at best a very weak linear relationship., Under such circumstances it is possible that a nonlinear relationship exists., 176 Self Learning Material
Page 177 :
�A scatter diagram can reveal the same and one is well advised to observe the same, before firmly concluding nonexistence of a relationship. If the scatter diagram, points to a nonlinear relationship, an appropriate transformation can often attain, linearity in which case ρ can be recomputed., 2. One has to be careful in interpreting the value of ρ., , Analysis of Data, , Notes, , � or example, one could compute ρ between size of a shoe and intelligence of, F, individuals, heights and income. Irrespective of the value of ρ, such a correlation, makes no sense and is hence termed chance or non-sense correlation., 3. ρ should not be used to say anything about cause and effect relationship. Put, differently, by examining the value of ρ, we could conclude that variables X and, Y are related., However, the same value of ρ does not tell us if X influences Y or the other way, round – a fact that is of grave import in regression analysis., , Spearman Rank Correlation Coefficient, Spearman Rank Correlation Coefficient is a non-parametric measure of correlation,, using ranks to calculate the correlation., Spearman Rank Correlation Coefficient uses ranks to Calculate Correlation., Whenever we are interested to know if two variables are related to each other, we, use a statistical technique known as correlation. If the change in one variable brings, about a change in the other variable, they are said to be correlated., A well-known measure of correlation is the Pearson product moment correlation, coefficient which can be calculated if the data is in interval/ ratio scale., It is also known as the “spearman rho” or “spearman r correlation”., The Spearman Rank Correlation Coefficient is its analogue when the data is in, terms of ranks. One can therefore also call it correlation coefficient between the ranks., The correlation coefficient is sometimes denoted by rs., , Example, As an example, let us consider a musical (solo vocal) talent contest where 10 competitors, are evaluated by two judges, A and B. Usually, judges award numerical scores for each, contestant after his/her performance., A product moment correlation coefficient of scores by the two judges hardly makes, sense here as we are not interested in examining the existence or otherwise of a linear, relationship between the scores., What makes more sense is correlation between ranks of contestants as judged by, the two judges. Spearman Rank Correlation Coefficient can indicate if judges agree to, each other’s views as far as talent of the contestants are concerned (though they might, award different numerical scores) - in other words if the judges are unanimous., Self Learning Material 177
Page 178 :
Research Methodology Interpretation of Numerical Values, The numerical value of the correlation coefficient, rs, ranges between –1 and +1. The, correlation coefficient is the number indicating how the scores are relating., rs = correlation coefficient, , Notes, , In general,, rs > 0 implies positive agreement among ranks, rs < 0 implies negative agreement (or agreement in the reverse direction), rs = 0 implies no agreement, Closer is the, rs to 1 the better is the agreement whereas rs closer to –1 indicates, strong agreement in the reverse direction., , Assigning Ranks, In order to compute Spearman Rank Correlation Coefficient, it is necessary that the data, be ranked. There are a few issues here., Suppose that scores of the judges (out of 10 were as follows):, Contestant No., , 1, , 2, , 3, , 4, , 5, , 6, , 7, , 8, , 9, , 10, , Score by Judge A, , 5, , 9, , 3, , 8, , 6, , 7, , 4, , 8, , 4, , 6, , Score by Judge B, , 7, , 8, , 6, , 7, , 8, , 5, , 10, , 6, , 5, , 8, , Ranks are assigned separately for the two judges either starting from the highest, or from the lowest score. Here, the highest score given by Judge A is 9., If we begin from the highest score, we assign rank 1 to contestant 2 corresponding, to the score of 9., The second highest score is 8 but two competitors have been awarded the score of, 8. In this case, both the competitors are assigned a common rank which is the arithmetic, mean of ranks 2 and 3. In this way, scores of Judge A can be converted into ranks., Similarly, ranks are assigned to the scores awarded by Judge B and then difference, between ranks for each contestant are used to evaluate rs. For the above example, ranks, are as follows., Contestant No., , 1, , 2, , Ranks of scores by Judge A, , 7, , 1 10, , Ranks of scores by Judge B, , 3, , 4, , 5, , 2.5 5.5, , 5.5 3 7.5 5.5, , 3, , 6, 4, 9.5, , 7, , 8, , 9, , 10, , 8.5 2.5 8.5 5.5, 1, , 7.5 9.5, , 3, , Spearman Rank Correlation Coefficient is a non-parametric measure of correlation., Spearman Rank Correlation Coefficient tries to assess the relationship between, ranks without making any assumptions about the nature of their relationship., Hence it is a non-parametric measure–a feature which has contributed to its, popularity and wide spread use., 178 Self Learning Material
Page 179 :
Advantages and Caveats, , Analysis of Data, , Other measures of correlation are parametric in the sense of being based on possible, relationship of a parameterized form, such as a linear relationship., Another advantage with this measure is that it is much easier to use since it does, not matter which way we rank the data, ascending or descending. We may assign rank, 1 to the smallest value or the largest value, provided we do the same thing for both sets, of data., , Notes, , The only requirement is that data should be ranked or at least converted into ranks., , Correlation and Causation, Correlation and causation, closely related to confounding variables, is the incorrect, assumption that because something correlates, there is a causal relationship., Causality is the area of statistics that is most commonly misused, and misinterpreted,, by non-specialists. Media sources, politicians and lobby groups often leap upon a, perceived correlation, and use it to ‘prove’ their own beliefs. They fail to understand, that, just because results show a correlation, there is no proof of an underlying causality., Many people assume that because a poll, or a statistic, contains many numbers, it must, be scientific, and therefore correct., , Patterns of Causality in the Mind, Unfortunately, the human mind is built to try and subconsciously establish links between, many contrasting pieces of information. The brain often tries to construct patterns from, randomness, so jumps to conclusions, and assumes that a relationship exists., Overcoming this tendency is part of academic training of students and academics in, most fields, from physics to the arts. The ability to evaluate data objectively is absolutely, crucial to academic success., , 4.14 Interpretation of Correlation Coefficient, Pearson’s Correlation Coefficient, Correlation is a technique for investigating the relationship between two quantitative,, continuous variables, for example, age and blood pressure. Pearson’s correlation, coefficient (r) is a measure of the strength of the association between the two variables., The first step in studying the relationship between two continuous variables is to draw, a scatter plot of the variables to check for linearity. The correlation coefficient should, not be calculated if the relationship is not linear. For correlation only purposes, it does, not really matter on which axis the variables are plotted. However, conventionally, the, independent (or explanatory) variable is plotted on the x-axis (horizontally) and the, dependent (or response) variable is plotted on the y-axis (vertically)., Self Learning Material 179
Page 180 :
Research Methodology, , Notes, , The nearer the scatter of points is to a straight line, the higher the strength of, association between the variables. Also, it does not matter what measurement units are, used., , Values of Pearson’s Correlation Coefficient, Pearson’s correlation coefficient (r) for continuous (interval level) data ranges from –1, to +1:, r = -1, , data lie on a perfect straight line, with a negative slope, , r=0, , no linear relationship between the, variables, , r = +1, , data lie on a perfect straight line, with a positive slope, , Positive correlation indicates that both variables increase or decrease together,, whereas negative correlation indicates that as one variable increases, so the other, decreases, and vice versa., , Statistical Significance of r, The t-test is used to establish if the correlation coefficient is significantly different from, zero, and, hence that there is evidence of an association between the two variables. There, 180 Self Learning Material
Page 181 :
is then the underlying assumption that the data is from a normal distribution sampled, randomly. If this is not true, the conclusions may well be invalidated. If this is the, case, it is better to use Spearman’s coefficient of rank correlation (for non-parametric, variables). See Campbell & Machin (1999) appendix A12 for calculations and more, discussion of this., , Analysis of Data, , Notes, , It is interesting to note that with larger samples, a low strength of correlation, for, example r = 0.3, can be highly statistically significant (i.e., p < 0.01)., , 4.15 Central Limit Theorem, The central limit theorem explains why many distributions tend to be close to the normal, distribution. The key ingredient is that the random variable being observed should be, the sum or mean of many independent identically distributed random variables. One, version of the theorem is, Central Limit Therorem 1. Let X1, X2, .... be independent, identically distributed, random variables having mean m and finite nonzero variance s2., Let Sn = X1 + ... Xn. Then, lim, , n→∞ P, , Sn – nm, s√ n, , ≤ x = f(x), , where F(x) is the probability that a standard normal random variable is less than x., This last point is especially important as it indicates that the shape of the sampling, distribution approaches normal as the size of the sample increases, whatever be the shape, of the population distribution., The facts represented in the Central Limit Theorem allow us to determine the, likely accuracy of a sample mean, but only if the sampling distribution of the mean is, approximately normal., If the population distribution is normal, the sampling distribution of the mean, will be normal for any sample size N (even N = 1). If a population distribution is not, normal, but it has a bump in the middle and no extreme scores and no strong skew, then, a sample of even modest size (e.g., N = 30) will have a sampling distribution of the, mean that is very close to normal. However, if the population distribution is far from, normal (e.g., extreme outliers or strong skew), then to produce a sampling distribution, of the mean that is close to normal it may be necessary to draw a very large sample, (e.g., N = 500 or more)., It is important to note here that one should not assume that the sampling distribution, of the mean is normal without considering the shape of the population distribution and, the size of your sample., Self Learning Material 181
Page 182 :
Research Methodology Mean, , Notes, , The mean is the most common indicator of an ‘average’ score. It is computed by dividing, the sum of all scores by the number of scores. If the distribution has extreme outliers, and/or skew, the mean may not be very descriptive of a ‘typical’ score., , Standard Deviation, The standard deviation is a common measure of variation of scores. The standard deviation, is computed by taking the square root of the variance. The larger the standard deviation, (and variance), the wider the distribution and the further the scores are from the mean., Like the mean, the standard deviation is sensitive to outlying scores., , Variance, Variance is a measure of how much scores in a distribution vary from the mean., Mathematically, variance is the average of the squared deviations from the mean. Taking, of the square root of variance, results into the standard deviation., , Population Versus Sample, A population consists of all cases in the group of interest. A sample is a group, of cases selected from all possible cases in the population. For example, if the group, of interest is American working women, the population would include each and every, working woman in America. Usually, it is impossible to collect data on an entire, population. Instead, we use one of many sampling techniques to select a subgroup from, the population. This subgroup is a sample., , Sample Size, A sample is a subset taken from the population of interest. The number of sampled cases, is called the sample size., , Sampling Distribution of the Mean, The sampling distribution of the mean is a theoretical distribution. If you were to draw, an infinite number of samples with a particular sample size from a population you, would get an infinite number of sample means (one for each sample you drew). The, distribution of these means is the sampling distribution of means for your population, at that particular sample size., , Normal Distribution, The normal curve (also called the “Bell curve” or “the Gaussian distribution”) is a, theoretical distribution mathematically defined by its mean and variance. When graphed, the normal distribution has a shape similar to a bell curve (see Fig. 13.1). Naturally, occurring distributions are rarely normal in shape. However, the distributions of many, 182 Self Learning Material
Page 183 :
chance events do approach normal shape. Importantly, the distribution of possible means, for a randomly selected sample is approximately normal if the sample is sufficiently, large. The area under the curve for a standardized normal curve is exactly 1.00 or 100%,, which is useful for finding probabilities., , Analysis of Data, , Notes, , Fig. 4.8: Three Normal Distributions whose Means and Standard Deviations Vary, , Sample Proportions, Let’s say we want to know what percentage of people in the population is left-handed. It, would be impossible to measure every single person in the world, so we take a sample, of 500 people and create a proportion. In our sample, 75 people are left handed. So:, x, 75, p^ = n 500 = 0.15, We can find out the distribution of the sample proportion if our sample size is less, than 5% of the total population size., If np (1 – p) ≥ 10, the distribution of the sample proportion is approximately normal., Standard deviation of sampling distribution:, sp^ =, , p(1 – p), n, , Let’s describe the sampling distribution: In a sample of 500 individuals, 75 are, left handed. Describe the distribution of the sample proportion:, Is the sample size less than 5% of the total population size?, YES, 500 is less than 5% of the entire world population., Is the distribution approximately normal?, YES, because 500(0.15) (1 – 0.15) ≥ 0, , np(1 – p) ≥10, 63.75 ≥ 0, p(1 – p), 0.15(1 –0.15), sp^ =, sp^ =, = 0.016, n, 500, m^p = 0.15 s^p = 0.016, Self Learning Material 183
Page 184 :
Research Methodology, , First, we answer the two questions to verify that we can create a meaningful, sampling distribution. After we find that the two requirements are met, we find a mean, proportion of 0.15, with a standard deviation of 0.016., , Notes, , mp^ = 0.015 sp^ = 0.016, , 0.30, 0.20, Probability, 0.10, , 0.118, , 0.134, , 0.150, p^, , 0.166, , 0.182, , Fig. 4.9, Using this information, we can finally create the distribution shown above (Fig. 4.2)., �Confidence Intervals about the Mean, Population Standard Deviation Known, , Central Limit Theorem, We can calculate what sample size we will need in order for our confidence interval to, have a certain margin of error., –, x → m, –x = 2.95, , m = 3.00, , We rarely know if our point estimate is correct because it is merely an estimation, of the actual value. Because of this discrepancy, we construct confidence intervals to, help estimate what the actual value of the unknown population mean is., Point Estimate ± Margin of Error, Confidence intervals are a point estimate plus/minus a margin of error. The margin, of error is determined by several factors like:, 1. How confident we want to be with our assessment,, 2. Population’s standard deviation,, 3. How large our sample size is etc., Let’s say we want to create a 95% confidence interval. That means we have an, alpha of 0.05(5%) which is split into two equal tails. This 2.5% refers to the value we, look up in the z-table in order to find the z-score we need to plug into the equation., , 184 Self Learning Material
Page 185 :
Analysis of Data, , x– ± za/2 s, n, , Notes, , 95%, , Probability, 2.5%, , 2.5%, , a = 0.05, , z0.05/2 = z0.025, , Fig. 4.10, Let’s try an example: On the verbal section of the SAT, the standard deviation, is known to be 100. A sample of 25 test-takers has a mean of 520. Construct a 95%, confidence interval about the mean., s, x– ± za/2, n, 100, 520 – (1.96), = 480.8, 25, 100, = 559.2, 25, We take this information and plug it into the equation for the confidence interval., Because we’re creating a 95% confidence interval, this means we have two tails of, 2.5%. When we look up 0.025 in the Z table, we find that it corresponds to a z-score of, 1.96. After plugging everything into the equation, we find a lower bound of 480.8 and, an upper bound of 559.2. We are 95% confident that the mean SAT score is between, 480.8 and 559.2., 520 + (1.96), , Calculating Required Sample Size to Estimate Population Mean, We can calculate what sample size we will need in order for our confidence interval to, have a certain margin of error., n=, , (za/2) (s) 2, E, , On the verbal section of the SAT, the standard deviation is known to be 100. What, size sample would we need to construct a 95% confidence interval with a margin of, error of 20?, (za/2) (s) 2, n=, E, n=, , (1.96) (100) 2, = 96.04, 20, We plug in the same “1.96” from the last example and find that a sample size of, 97 is needed to create a 95% confidence interval with a margin of error of 20., Self Learning Material 185
Page 186 :
Research Methodology, , Notes, , 4.16, , Parametric Tests, , Inferential statistics suggest statements about a population based on a sample from, that population. Parametric inferential tests are carried out on data that follow certain, parameters: the data will be normal (i.e., the distribution parallels the bell curve); numbers, can be added, subtracted, multiplied and divided; variances are equal when comparing, two or more groups; and the sample should be large and randomly selected., There are generally more statistical technique options for the analysis of parametric, than non-parametric data, and parametric statistics are considered to be the more, powerful. Common examples of parametric tests are: correlated t-tests and the Pearson, r-correlation coefficient., , 4.17, , Sign Test, , We may wish to test whether the sample median differs significantly from some prespecified hypothesized value. The simplest way to do this is with a sign test., If the hypothesized median value were true, we would expect:, zz Approximately,, , half of the sample values to be larger than the hypothesized, value and the remaining half to be less than it., , If the hypothesised median is not true then:, zz The, , numbers above and below may be quite different in our sample., , The sign test considers how likely we were to obtain the observed imbalance if, the hypothesised median were true. The following table allows us to obtain p-values., , Example, There were 12 temperature changes. If temperature change was on average zero, we, would expect 6 values above zero and 6 below. In this sample, only 1 value is positive, and 11 are negative. The table shows that p = 0.0063., , 4.18, , One-sample z test, , Requirements: Normally distributed population, σ known Test for population mean, Hypothesis test, x– – D, Formula: z = s, n, Where, x– is the sample mean, Δ is a specified value to be tested, σ is the population, standard deviation and ‘n’ is the size of the sample. Look up the significance level of, the z-value in the standard normal table (Table in Appendix)., A herd of 1,500 steer was fed a special high-protein grain for a month. A random, sample of 29 was weighed and had gained an average of 6.7 pounds. If the standard, 186 Self Learning Material
Page 187 :
deviation of weight gain for the entire herd is 7.1, test the hypothesis that the average, , Analysis of Data, , weight gain per steer for the month was more than 5 pounds., Null hypothesis: H 0: μ = 5, Alternative hypothesis: H a: μ > 5, 1.7, 6.7 – 5, = 1.289, z = 7.1 =, 1.318, 29, , Notes, , Tabled value for z ≤ 1.28 is 0.8997, 1 – 0.8997 = 0.1003, So, the conditional probability that a sample from the herd gains at least 6.7 pounds, per steer is p = 0.1003. Should the null hypothesis of a weight gain of less than 5 pounds, for the population be rejected? That depends on how conservative you want to be. If, you had decided beforehand on a significance level of p < 0.05, the null hypothesis, could not be rejected., In national use, a vocabulary test is known to have a mean score of 68 and a, standard deviation of 13. A class of 19 students takes the test and has a mean score of 65., Is the class typical of others who have taken the test? Assume a significance level, of p < 0.05., There are two possible ways that the class may differ from the population. Its scores, may be lower than, or higher than, the population of all students taking the test; therefore,, this problem requires a two-tailed test. First, state the null and alternative hypotheses:, Null hypothesis: H 0: μ = 68, Alternative hypothesis: H a : μ ≠ 68, Because you have specified a significance level, you can look up the critical z-value, in Table of Appendix B before computing the statistic. This is a two-tailed test; so the, 0.05 must be split such that 0.025 is in the upper tail and another 0.025 in the lower., The z-value that corresponds to –0.025 is –1.96, which is the lower critical z-value. The, upper value corresponds to 1 – 0.025, or 0.975, which gives a z-value of 1.96. The null, hypothesis of no difference will be rejected if the computed z statistic falls outside the, range of –1.96 to 1.96., , –3, 65 – 68, = –1.006, =, 13, 2.982, 19, Because –1.006 is between –1.96 and 1.96, the null hypothesis of population, , Next, compute the z statistic: z =, , mean is 68 and cannot be rejected. That is, there is no evidence that this class can be, considered different from others who have taken the test., –, s, Formula: (a, b) = x ± za/2 ., n, Self Learning Material 187
Page 188 :
where a and b are the limits of the confidence interval, x– is the sample mean,, , Research Methodology, , za/2 is the upper (or positive) z-value from the standard normal table corresponding to, half of the desired alpha level (because all confidence intervals are two-tailed), σ is the, , Notes, , population standard deviation, and ‘n’ is the size of the sample., A sample of 12 machine pins has a mean diameter of 1.15 inches, and the population, standard deviation is known to be 0.04. What is a 99% confidence interval of diameter, width for the population?, First, determine the z-value. A 99% confidence level is equivalent to p < 0.01. Half, of 0.01 is 0.005. The z-value corresponding to an area of 0.005 is 2.58. The interval, 0.04, = 1.15 ± 0.03, may now be calculated: 1.15 ± 2.58 ., 12, The interval is (1.12, 1.18)., We have 99% confidence that the population mean of pin diameters lies between, 1.12 and 1.18 inches. Note that this is not the same as saying that 99% of the machine pins, have diameters between 1.12 and 1.18 inches, which would be an incorrect conclusion, from this test., Because surveys cost money to administer, researchers often want to calculate how, many subjects will be needed to determine a population mean using a fixed confidence, 2za/2s 2, interval and significance level. The formula is n = w , Where ‘n’ is the number of subjects needed, za/2 is the critical z-value corresponding, to the desired significance level, σ is the population standard deviation and w is the, desired confidence interval width., How many subjects will be needed to find the average age of students at Fisher, College plus or minus a year, with a 95% significance level and a population standard, deviation of 3.5?, (2) (1.96) (3.5) 2, 13.72 2, , , = 47.06, n =, =, 2, 2, Rounding up, a sample of 48 students would be sufficient to determine students’, mean age plus or minus one year. Note that the confidence interval width is always, double the “plus or minus” figure., , Example, Let’s perform a one-sample z-test: In the population, the average IQ is 100 with a, standard deviation of 15. A team of scientists wants to test a new medication to see if, it has either a positive or negative effect on intelligence or no effect at all. A sample of, 30 participants who have taken the medication has a mean of 140. Did the medication, affect intelligence, using alpha = 0.05?, , Steps for One-Sample z-Test, 1. Define Null and Alternative Hypotheses, 188 Self Learning Material
Page 189 :
Analysis of Data, , 2. State Alpha, 3. State Decision Rule, 4. Calculate Test Statistic, , Notes, , 5. State Results and, 6. State Conclusion, Let’s begin., 1. Define Null and Alternative Hypotheses, H0; m = 100, H1; m ≠ 100, 2. State Alpha, �Using an alpha of 0.05 with a two-tailed test, we would expect our distribution, to look something like this:, , 95%, , Probability, 2.5%, , 2.5%, , Fig. 4.11, � ere we have 0.025 in each tail. Looking up 1 – 0.025 in our z-table, we find, H, a critical value of 1.96. Thus, our decision rule for this two-tailed test is:, If Z is less than –1.96, or greater than 1.96, reject the null hypothesis., 3. Calculate Test Statistic, 40, 140 – 100, x– – m, = 14.60, Z=, Z= s, =, 15, 2.714, n, 30, 4. State Results, Z = 14.60, Result: Reject the null hypothesis., Self Learning Material 189
Page 190 :
5. State Conclusion, , Research Methodology, , Medication significantly affected intelligence, Z = 14.60, p < 0.05., , Notes, , 4.19, , One-Sample z-Test for Proportions, , Let’s perform a one-sample z-test for proportions: A survey claims that 9 out of 10, doctors recommend aspirin for their patients with headaches. To test this claim, a, random sample of 100 doctors is obtained. Of these 100 doctors, 82 indicate that they, recommend aspirin. Is this claim accurate? Use alpha = 0.05, , Steps for One-Sample z-Test for Proportions, 1. Define Null and Alternative Hypotheses, 2. State Alpha, 3. State Decision Rule, 4. Calculate Test Statistic, 5. State Results, 6. State Conclusion, Let’s begin., 1. Define Null and Alternative Hypotheses, , 2. State Alpha, Alpha = 0.05, 3. State Decision Rule, �Using an alpha of 0.05 with a two-tailed test, we would expect our distribution, to look something like this:, , 95%, , Probability, , 2.5%, , 2.5%, , Fig. 4.12, 190 Self Learning Material
Page 191 :
� ere we have 0.025 in each tail. Looking up 1 – 0.025 in our z-table, we find, H, a critical value of 1.96. Thus, our decision rule for this two-tailed test is:, , Analysis of Data, , If Z is less than –1.96, or greater than 1.96, reject the null hypothesis., 4. Calculate Test Statistic, z0 =, , Notes, , p^ – p0, , p0(1 – p0), n, , p^ = .82, , p0 = .90 z0 =, n = 100, , .82 – .90, .90(1 – .90), 100, , =, , –0.08, = –2.667, 0.03, , 5. State Results, z = –2.667, Result: Reject the null hypothesis., 6. State Conclusion, �The claim that 9 out of 10 doctors recommend aspirin for their patients is not, accurate, z = –2.667, p < 0.05., , 4.20 Students’ t distribution, While performing any type of test or analysis using a Z-score, it is required that the, population standard deviation already be known. In real life, this is hardly ever the case., It is almost impossible for us to know the standard deviation of the population from, which our sample is drawn., We use Student’s t-distribution to perform an analysis when we don’t know the, population standard deviation, or when or sample size is unreasonably small., x– – m, t=, s/ n, Student’s t-Distribution has n – 1 degrees of freedom., Remember that we are no longer given population standard deviation. Instead,, we must estimate it with sample standard deviation. Sample standard deviation, itself, is a random variable. The proof for degrees of freedom is far beyond the scope of this, lecture. Just try to understand that by calculating sample standard deviation, it is given, a fixed value and thus one less value is free to vary., These degrees of freedom change how the probability distribution looks. The, probability distribution of t has more dispersion than the normal probability distribution, associated with z., Self Learning Material 191
Page 192 :
Research Methodology, , Notes, , While performing tests using t, we expect the probability distribution to look slightly, different, so we must use a different t-table calculate areas associated with different, areas of the graph when taking degrees of freedom into account., , 4.21, , Homogeneity of variance, , Most commonly used statistical hypothesis tests, such as t-tests, compare means or, other measures of location. Some studies need to compare variability also. Equality of, variance tests can be used on their own for this purpose but they are often used alongside, other methods (e.g., analysis of variance) to support assumptions made about variance., Homogeneity of variance is a major assumption underlying the validity of many, parametric tests such as the t-test and ANOVA. It also represents the null hypothesis in, substantive studies that focus on cross- or within-group fluctuation in variability., , ANOVA, ANOVA is a statistical method used to compare the means of two or more groups., An ANOVA has factors (variables), and each of those factors has levels:, 0 mg, , 50 mg, , 100 mg, , 9, , 7, , 4, , 8, , 6, , 3, , 7, , 6, , 2, , 8, , 7, , 3, , 8, , 8, , 4, , 9, , 7, , 3, , 8, , 6, , 2, , There are several different types of ANOVA such as one-way anova, two-way, anova, etc., , Assumptions, There are four main assumptions of an ANOVA:, 7. Normality of Sampling Distribution of Means: The distribution of sample means, is normally distributed., 8. Independence of Errors: Errors between cases are independent of one another., 9. Absence of Outliers: Outlying scores have been removed from the data set., 10. Homogeneity of Variance; Population variances in different levels of each, independent variable are equal., Hypotheses in ANOVA depend on the number of factors you’re dealing with:, 192 Self Learning Material
Page 193 :
Analysis of Data, , ANOVA with one factor (“A”, three levels):, H0; mA1 = mA2 = mA3, H1; not all means are, , Main Effect, , Notes, , ANOVA with two factors (“A” and “B”, each with three levels):, H0; mA = mA = mA, 1, , 2, , 3, , H1; not all means are, , H0; mB = mB = mB, 1, , 2, , 3, , H1; not all means are, H0; interaction absect, H1; interaction absect, , Interaction Effect, , Fig. 4.13, Effects dealing with one factor are called main effects. Effects dealing with multiple, factors are called interaction effects., Here’s an example of an interaction effect in an ANOVA: Below we have a Factorial, ANOVA with two factors: dosage (0 mg and 100 mg) and gender (men and women). In, the 0 mg dosage condition, men have a mean of 60 while women have a mean of 80., In the 100 mg dosage condition, men have a mean of 80 while women have a mean of, 50. This could be represented in a graph like this:, , 80, , 80, , Scroe, , Men, Women, , 60, 50, 0mg, , 100mg, , Fig. 4.14, Dosage and gender are interacting because the effect of one variable depends on, which level you’re at of the other variable. For example, men with a lower dosage have, lower scores than women, but men with a higher dosage have higher scores than women., Self Learning Material 193
Page 194 :
Research Methodology, , H0, mA1 = mA2 = mA, , 3, , H1; not all means are equal, , Notes, , If we reject the null hypothesis in an ANOVA, all we know is that there is a, difference somewhere among the groups. Additional tests called Post Hoc tests must, be done to determine where differences lie., When performing an ANOVA, we calculate an “F” statistic. It is similar to other, statistics such a “z” and “t”., Treatment Differences + Random Differences, Random Differences, If there are no treatment differences (that is, if there is no actual effect), we expect, F to be 1. If there are treatment differences, we expect F to be greater than 1., F=, , The F statistic has its own one-tailed distribution, much like how the “z” and “t”, statistics have their own separate distributions., One-Way ANOVA, Let’s perform a one-way ANOVA: Researchers want to test a new anti-anxiety medication., They split participants into three conditions (0 mg, 50 mg, and 100 mg), and then ask, them to rate their anxiety level on a scale of 1–10. Are there any differences between, the three conditions using alpha = 0.05?, Table 4.1, 0 mg, , 50 mg, , 100 mg, , 9, , 7, , 4, , 8, , 6, , 3, , 7, , 6, , 2, , 8, , 7, , 3, , 8, , 8, , 4, , 9, , 7, , 3, , 8, , 6, , 2, , Steps for One-Way ANOVA, 1. Define Null and Alternative Hypotheses., 2. State Alpha., 3. Calculate Degrees of Freedom., 4. State Decision Rule., 5. Calculate Test Statistic., 6. State Results., 7. State Conclusion., 194 Self Learning Material
Page 195 :
Analysis of Data, , Let’s begin., 1. Define Null and Alternative Hypotheses., H0, m0mg = m50mg = m100mg, H1; not all m’s are equal, 2. State Alpha, , Notes, , Alpha = 0.05, 3. Calculate Degrees of Freedom., �Now we calculate the degrees of freedom using N = 21, n = 7, and a = 3. You, should already recognize N and n. “a” refers to the number of groups (“levels”), you’re dealing with:, dfBetween = a – 1 = 3 – 1 = 2, dfWithin = N – a = 21 – 3 = 18, dfTotal = N – 1 = 21 – 1 = 20, 4. State Decision Rule, To look up the critical value, we need to use two different degrees of freedom., dfBetween = a – 1 = 3 – 1 = 2, dfWithin = N – a = 21 – 3 = 18, �We now head to the F-table and look up the critical value using (2, 18) and, alpha = 0.05. This results into a critical value of 3.5546, so our decision rule is:, If F is greater than 3.5546, reject the null hypothesis., 5. Calculate Test Statistic, To calculate the test statistic, we first need to find three values:, SSbetween SSwithin SStotal, SSbetween =, , 572 + 472 + 212, 1252, –, = 98.67, 7, 21, , 0 mg Group: 9 + 8 – 7 + 8 + 8 + 9 + 8 = 57, 50 mg Group : 7 + 6 – 6 + 7 + 8 + 7 + 6 = 47, 100 mg Group: 4 + 3 – 2 + 3 + 4 + 3 + 2 = 21, 572 + 472 + 212, = 10.29, , SSwithin = 853 –, 7, SY2 = 92 + 82 + 72 + 82 + 82 + 92 + 82 + 72 + 62, , , , + 62 + 72 + 82 + 72 + 62 + 42 + 32 + 22 + 32, + 42 + 32 + 22 = 853, , SStotal = 853 –, , 1252, = 108.95, 21, Self Learning Material 195
Page 196 :
Research Methodology, , All the values we’ve found so far can be organized in an ANOVA, Table 14.2, , Notes, , SS, , df, , Between, , 98.67, , 2, , Within, , 10.29, , 18, , Total, , 108.25, , 20, , MS, , F, , Now we find each MS by diving each SS by their respective df:, MSbetween =, MSwithin =, , 98.67, = 49.34, 2, , 10.29, = 0.57, 18, , And finally, we can calculate our F:, F=, , MSbetween, MSwithin, , =, , 49.64, = 0.57, 0.57, Table 14.3, SS, , df, , MS, , F, , Between, , 98.67, , 2, , 49.34, , 86.56, , Within, , 10.29, , 18, , 0.57, , Total, , 108.25, , 20, , 6. State Results, F = 86.56, Result: Reject the null hypothesis., 7. State Conclusion, �The three conditions differed significantly on anxiety level, F (2, 18) = 86.56,, p < 0.05., , 4.22 Analysis of Co-variance (ANOCOVA), Why ANOCOVA?, The object of experimental design in general happens to be to ensure that the results, observed may be attributed to the treatment variable and to no other causal circumstances., For instance, the researcher studying one independent variable, X, may wish to control, the influence of some uncontrolled variable (sometimes called the covariate or the, concomitant variables), Z, which is known to be correlated with the dependent variable,, Y, then he should use the technique of analysis of covariance for a valid evaluation of, 196 Self Learning Material
Page 197 :
the outcome of the experiment. “In psychology and education primary interest in the, analysis of covariance rests in its use as a procedure for the statistical control of an, uncontrolled variable.”, , Analysis of Data, , Notes, , ANOCOVA Technique, While applying the ANOCOVA technique, the influence of uncontrolled variable is, usually removed by simple linear regression method and the residual sums of squares are, used to provide variance estimates which in turn are used to make tests of significance., In other words, covariance analysis consists in subtracting from each individual score, (Yi) that portion of it Yi´ that is predictable from uncontrolled variable (Zi) and then, computing the usual analysis of variance on the resulting (Y – Y´)’s, of course making, the due adjustment to the degrees of freedom because of the fact that estimation using, regression method required loss of degrees of freedom., , Assumptions in ANOCOVA, The ANOCOVA technique requires one to assume that there is some sort of relationship, between the dependent variable and the uncontrolled variable. We also assume that this, form of relationship is the same in the various treatment groups. Other assumptions are:, 1. Various treatment groups are selected at random from the population., 2. The groups are homogeneous in variability., 3. The regression is linear and is same from group to group., , 4.23 Partial Correlation, Partial correlation is a method used to describe the relationship between two variables, whilst taking away the effects of another variable, or several other variables, on this, relationship., Consider a correlation matrix for variables A, B and C:, A, , B, , A:, , *, , B:, , r(AB), , *, , C:, , r(AC), , r(BC), , C, , *, , The partial correlation of A and B adjusted for C is:, rABC =, , rAB – rAC rBC, , √ (1 – r2AC) (1 – r2BC), , The same can be done using Spearman’s rank correlation co-efficient., The hypothesis test for the partial correlation co-efficient is performed in the same, way as for the usual correlation co-efficient but it is based upon n–3 degrees of freedom., Self Learning Material 197
Page 198 :
Research Methodology, , Please note that this sort of relationship between three or more variables is more, usefully investigated using the multiple regression itself (Altman, 1991)., The general form of partial correlation from a multiple regression is as follows:, , Notes, , rk =, , tk, , √ tk2 + residual DF, , Where tk is the Student t statistic for the kth term in the linear model., Residual df = residual degrees of freedom = Total df – Regression df = n – 1 –, number of independent variables (xi), , 4.24, , Multiple Correlation and Regression, , When there are two or more than two independent variables, the analysis concerning, relationship is known as multiple correlation and the equation describing such relationship, as the multiple regression equation. We here explain multiple correlation and regression, taking only two independent variables and one dependent variable (Convenient computer, programs exist for dealing with a great number of variables). In this situation the results, are interpreted as shown below:, Multiple regression equation assumes the form given below:, ^, , Y = a + b1X1 + b2X2, Where X1 and X2 are two independent variables and Y being the dependent, variable, and the constants a, b1 and b2 can be solved by solving the following three, normal equations:, , SYi = na + b1 SX1i + b2 SX2i, SX1iYi = aSX1i + b1SX1i2 + b2SX1iX1i, SX2iYi = aSX2i + b1SX1iX2i + b2SX2i2, (It may be noted that the number of normal equations would depend upon the, number of independent variables. If there are 2 independent variables, 3 equations, if, there are 3 independent variables then 4 equations and so on, are used.), In multiple regression analysis, the regression coefficients (viz., b1 b2) become, less reliable as the degree of correlation between the independent variables (viz., X1,, X2) increases. If there is a high degree of correlation between independent variables,, we have a problem of what is commonly described as the problem of multicollinearity., In such a situation, we should use only one set of the independent variable to make our, estimate. In fact, adding a second variable, say X2, that is correlated with the first variable,, say X1, distorts the values of the regression coefficients. Nevertheless, the prediction, for the dependent variable can be made even when multicollinearity is present, but in, such a situation enough care should be taken in selecting the independent variables to, estimate a dependent variable so as to ensure that multicollinearity is reduced to the, 198 Self Learning Material
Page 199 :
minimum. With more than one independent variable, we may make a difference between, the collective effect of the two independent variables and the individual effect of each, of them taken separately. The collective effect is given by the coefficient of multiple, correlation, and b1 and b2 are the regression coefficients., Ry – x1x2 defined as under:, Ry – x1x2 =, , – –, , Analysis of Data, , Notes, , – –, , b1 SYiX1i – n Y X1 + b2SYiX2i – n Y X2, , SX1iX1i, , Alternatively, we can write, b1 Sx1iyi + b2Sx2iyi, , Ry . x1x2 =, SYi2, where, , , , , –, x1i = (X1i – X1), –, x2i = (X2i – X2), –, yi = (Yi – Y ), , 4.25 Non-parametric tests, Chi-Square Test, The chi-square test is an important test amongst the several tests of significance developed, by statisticians. Chi-square, symbolically written as χ2 (Pronounced as Ki-square), is a, statistical measure used in the context of sampling analysis for comparing a variance to a, theoretical variance. As a non-parametric test, it “can be used to determine if categorical, data shows dependency or the two classifications are independent. It can also be used, to make comparisons between theoretical populations and actual data when categories, are used.” Thus, the chi-square test is applicable in large number of problems. The test, is, in fact, a technique through the use of which it is possible for all researchers to, 1. test the goodness of fit;, 2. test the significance of association between two attributes, and, 3. test the homogeneity or the significance of population variance., , Chi-Square as a Test for Comparing Variance, The chi-square value is often used to judge the significance of population variance,, i.e., we can use the test to judge if a random sample has been drawn from a normal, population with mean (m) and with a specified variance ( s p 2 ). The test is based on c2, -distribution. Such a distribution we encounter when we deal with collections of values, that involve adding up squares. Variances of samples require us to add a collection of, squared quantities and, thus, have distributions that are related to c2 -distribution. If we, take each one of a collection of sample variances, divided them by the known population, Self Learning Material 199
Page 200 :
Research Methodology variance and multiply these quotients by (n – 1), where ‘n’ means the number of items, in the sample, we shall obtain a c2 -distribution. Thus, Formula degrees of freedom., , Notes, , The x2-distribution is not symmetrical and all the values are positive. For making, use of this distribution, one is required to know the degrees of freedom since for different, degrees of freedom we have different curves. The smaller the number of degrees of, freedom, the more skewed is the distribution which is illustrated in below (Fig. 14.3):, 2—distribution, , for different degrees of freedom, , df = 1, df = 3, df = 5, df = 10, , 0, , 5, , 10, , 15, , 20, , 25, , 30, , 2—Values, , Fig. 4.15, Table given in the Appendix gives selected critical values of x 2 for, , the different degrees of freedom. x 2 -values are the quantities indicated on, , the x-axis of the above diagram and in the table are areas below that value., In brief, when we have to use chi-square as a test of population variance, we have to, work out the value of c2 to test the null hypothesis (viz., Formula) as under:, χ2 –, , s s2, , sp2, , (n – 1), , Then by comparing the calculated value with the table value of c2 for (n – 1), degrees of freedom at a given level of significance, we may either accept or reject, the null hypothesis. If the calculated value of c2 is less than the table value, the null, hypothesis is accepted, but if the calculated value is equal or greater than the table value,, the hypothesis is rejected., , Chi-Square Test for Goodness of Fit, The Chi-Square Test for Goodness of Fit tests claims about population proportions., It is a non-parametric test that is performed on categorical (nominal or ordinal) data., Let’s try an example. In the 2000 US Census, the ages of individuals in a small, town were found to be the following:, 200 Self Learning Material
Page 201 :
Table 4.4, 18–35, 30%, , Less than 18, 20%, , Analysis of Data, Greater than 35, 50%, , In 2010, ages of n = 500 individuals from the same small town were sampled., Below are the results:, Table 4.5, 18–35, 288, , Less than 18, 121, , Notes, , Greater than 35, 91, , Using alpha = 0.05, would you conclude that the population distribution of ages, has changed in the last 10 years?, Using our sample size and expected per centages, we can calculate how many, people we expected to fall within each range. We can then make a table separating, observed values versus expected values:, Table 4.6, Less than 18, 20%, , 18–35, 30%, , Greater than 35, 50%, , Observed, Expected, , Less than 18, 121, 500*0.20 = 100, , 18–35, 288, 500*0.30 – 150, , Greater than 35, 91, 500*50 – 250, , Observed, Expected, , Less than 18, 121, 100, , 18-35, 288, 150, , Greater than 35, 91, 250, , Expected, , Let’s perform a hypothesis test on this new table to answer the original question., , Steps for Chi-Square Test for Goodness of Fit, 1. Define Null and Alternative Hypotheses, 2. State Alpha, 3. Calculate Degrees of Freedom, 4. State Decision Rule, 5. Calculate Test Statistic, 6. State Results, 7. State Conclusion, 1. Define Null and Alternative Hypotheses, H0; the data meet the expected distribution, H1; the data do not meet the expected distribution, Self Learning Material 201
Page 202 :
2. State Alpha, , Research Methodology, , alpha = 0.05, 3. Calculate Degrees of Freedom, df = k – 1, where k = your number of groups., , Notes, , df = 3 – 1 = 2, 4. State Decision Rule, �Using our alpha and our degrees of freedom, who look up a critical value in, the Chi-Square Table. We find our critical value to be 5.99., If χ2 is greater than 5.99, reject H0., 5. Calculate Test Statistic, �The Chi-Square statistic is found using the following equation, where observed, values are compared to expected values:, Table 4.7, Less than 18, 18–35, 121, 288, 100, 150, , Observed, Expected, χ2, , =, , S, , Greater than 35, 91, 250, , (f0 – fe)2, f, , (121 – 100)2, , χ2, , =, , χ2, , = 232.494, , 100, , +, , (288 – 150)2, 150, , +, , (91 – 250)2, 250, , 6. State Results, If χ2 is greater than 5.99, reject H0., χ2 = 232.494, , Reject the null hypothesis., 7. State Conclusion, �The ages of the 2010 population are different than those expected based on the, 2000 population., , Chi-Square Test for Independence, The Chi-Square Test for Independence evaluates the relationship between two variables., It is a non-parametric test that is performed on categorical(nominal or ordinal) data., Let’s try an example. 500 elementary school boys and girls are asked which is, their favourite colour: blue, green, or pink? Results are shown below:, Table 4.8, Boys, 202 Self Learning Material, , Blue, , Green, , Pink, , 100, , 150, , 20, , 300
Page 203 :
Girls, , 20, , 30, , 180, , 200, , 120, , 180, , 200, , N = 500, , Using alpha = 0.05, would you conclude that there is a relationship between gender, and favourite colour?, , Analysis of Data, , Notes, , Let’s perform a hypothesis test to answer this question., , Steps for Chi-Square Test for Independence, 1. Define Null and Alternative Hypotheses, 2. State Alpha, 3. Calculate Degrees of Freedom, 4. State Decision Rule, 5. Calculate Test Statistic, 6. State Results, 7. State Conclusion, 1. Define Null and Alternative Hypotheses, �H0; For the population of elementary school students, gender and favourite, colour are not related., , �H1; For the population of elementary school students, gender and favourite, colour are related., , 2. State Alpha, alpha = 0.05, 3. Calculate Degrees of Freedom, df = (rows – 1)(columns – 1), df = (2 – 1)(3 – 1), df = (1)(2) = 2, 4. State Decision Rule, �Using our alpha and our degrees of freedom, who look up a critical value in, the Chi-Square Table. We find our critical value to be 5.99., If χ2 is greater than 5.99, reject H0., 5. Calculate Test Statistic, �First, we need to calculate our expected values using the equation below. We, find the expected values by multiplying each row total by each column total,, and then diving by the total number of subjects. The calculations for boys who, like blue are shown., Self Learning Material 203
Page 204 :
Table 4.9, fc fr, (Boys, Blue) = (120 * 300)/500 = 72, fe =, n, Expected, Blue, Green, Pink, , Research Methodology, , Notes, , Boys, , 72, , 108, , 120, , 300, , Girls, , 48, , 72, , 80, , 200, , 120, , 180, , 200, , N = 500, , 6. State Results, If χ2 is greater than 5.99, reject H0., χ2 = 266.389, Reject the null hypothesis, 7. State Conclusion, In the population, there is a relationship between gender and favourite colour., , Mann-Whitney U Tests, The Mann-Whitney U-Test is a version of the independent samples t-Test that can be, performed on ordinal (ranked) data., Ordinal data is displayed in the table below. Is there a difference between Treatment, A and Treatment B using alpha = 0.05?, Table 4.10, Treatment A, , 28, , 31, , 36, , 35, , 32, , 33, , Treatment B, , 12, , 18, , 19, , 14, , 20, , 19, , Let’s test to see if there is a difference with a hypothesis test., , Steps for Mann-Whitney U-Test, 1. Define Null and Alternative Hypotheses., 2. State Alpha., 3. State Decision Rule., 4. Calculate Test Statistic., 5. State Results., 6. State Conclusion., 1. Define Null and Alternative Hypotheses, H0; There is no difference between the ranks of the two treatments., H1; There is a difference between the ranks of the two treatments., , 2. State Alpha, , alpha = 0.05, 204 Self Learning Material
Page 205 :
3. State Decision Rule, , Analysis of Data, , � hen you have a sample size that is greater than approximately 30, the MannW, Whitney U statistic follows the z distribution. Here, our sample is not greater, than 30. However, we will still be using the z distribution for the sake of brevity., � e look up our critical value in the z-Table and find a critical value of plus/, W, minus 1.96. If z is less than -1.96, or greater than 1.96, reject the null hypothesis., , Notes, , 4. Calculate Test Statistic, �First, we must rank all of our scores and indicate which group the scores came, from:, Table 4.11, , If there is a tie, as shown below, we average the ranks:, Table 4.12, , Self Learning Material 205
Page 206 :
Research Methodology, , �Next, we give every “B” group one point for every “A” group that is above it., We also give every “A” group one point for every “B” group that is above it., We then add together the points for “A” and “B”, and take the smaller of those, two values which we call “U”., , Notes, , Table 4.13, , The “U” score is then used to calculate the z statistic:, , z=, , z=, , U=0, U=, , nAnB, 2, , nAnB (nA + nB + 1), 12, (6) (6), 0–, 2, (6) (6) (6 + 6 + 1), 12, , z = – 2.88, 5. State Results, If z is less than –1.96, or greater than 1.96, reject the null hypothesis., z = –2.88, Reject the null hypothesis., 6. State Conclusion, �, There is a difference between the ranks of the two treatments, z = –2.88, p, < .05., , Outliers and Missing Data, An outlier is a value that is very different from the other data in your data set. This can, skew your results., 206 Self Learning Material
Page 207 :
Let’s examine what can happen to a data set with outliers. For the sample data set:, , Analysis of Data, , 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, We find the following mean, median, mode, and standard deviation:, Mean = 2.58, Median = 2.5, , Notes, , Mode = 2, Standard Deviation = 1.08, If we add an outlier to the data set:, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, 400, The new values of our statistics are:, Mean = 35.38, Median = 2.5, Mode = 2, Standard Deviation = 114.74, As you can see, having outliers often has a significant effect on your mean and, standard deviation. Because of this, we must take steps to remove outliers from our, data sets., , 4.26 Use of Statistical Software’s in Research, Computer based statistical packages are an important tool for researchers in the social, sciences. The prospect of using statistics is sometimes either repugnant or simply, frightening for people, yet most researchers recognize the potential utility of statistical, analysis to aid them to describe, analyze, interpret and report their data. The mathematics, behind statistical analysis can be daunting for those who have little formal training in, either mathematics or the use of statistics. The development of specialist statistical, analysis packages has greatly reduced the mathematical challenge of undertaking many, analyses. It should be emphasised, however, that these packages have not reduced the, need for researchers to understand the assumptions behind statistical analyses, and, to be able to interpret their results. The packages have, however, reduced the need, for researchers to be able to undertake many of the calculations that are required for, statistical analyses. In this way, they allow researchers to concentrate on understanding, the assumptions behind the various methods, as well as the potential applications and, limitations of various statistical tests., Statistical software packages have, like other software packages, changed greatly, since the advent of the personal computer a little over 20 years ago. Some of the authors, still remember programming mainframe computers with paper cards. Holes were punched, into the cards and these were then fed into the computer. Computers in those days, Self Learning Material 207
Page 208 :
Research Methodology were scarce, especially the big ones with four megabyte memory! Needless to say that, statistical tests were difficult to perform unless the user had an advanced understanding, of the mathematics required. More recent computer software packages are reasonably, easy to use for people with some familiarity with computers. Most of the packages have, Notes, features such as drop-down menus, ‘tree’ structure diagrams and on-line help systems., This is said, it should be remembered that the packages discussed here are large and, highly complex. While they are considerably easier to use today than they were even, 10 years ago, like other large software packages, familiarity and ease of use are only, developed through practice with the package. A user can become functionally proficient, with a package such as Excel and Word after several weeks, use but development of a, high level of expertise can take many months or even several years., When choosing which package to use for statistical analyses a number of factors, must be considered. These include the availability of a package, its cost, the functions it, can perform, familiarity with the package and the availability of an expert statistician to, assist with the analysis process. As discussed above, the packages take time and effort, to learn, and many researchers prefer to continue using a particular package once they, learned how to use it. Other factors may affect this however. Availability of a package, is an important factor in deciding whether to use it or not. If an institution has already, obtained the rights to use a particular package, it may be the only choice available., Buying copies of the latest versions of the specialist statistical packages is expensive,, as is the cost of maintaining the license to use the package. If an institution already has, a package that can provide the functions required, the researcher may be forced to use, that package despite preferences for other software because of limited funds., Where expert statisticians are available to assist with data analyses then the, preferred package of the expert is likely to be the one used. As discussed in other units, it is important to discuss research projects with expert statisticians during their design, to ensure that the data collected will be in a format that allows the use of the desired, analysis techniques. It is also important at this stage to discuss the packages available, to the researcher and the time available to access a computer for data entry, analysis and, reporting. Where access to the computers with the statistical software is limited it may, be possible for the researcher to enter the data into a spreadsheet programme like Excel, and then transfer the data set to the statistics package in order to carry out the analyses., In this case, it is important to have some understanding of the formatting required by the, statistical package to be used so as to avoid unnecessary reformatting of the data in the, statistical package. Where possible, data should be entered directly into the statistical, package to avoid the potential need to reformat the data., , Excel for Statistical Data Analysis, Excel is the widely used statistical package, which serves as a tool to understand, statistical concepts and computation to check your hand-worked calculation in solving, 208 Self Learning Material
Page 209 :
your homework problems. The site provides an introduction to understand the basics, of and working with the Excel., , Entering Data, A new worksheet is a grid of rows and columns. The rows are labelled with numbers,, and the columns are labelled with letters. Each intersection of a row and a column is, , Analysis of Data, , Notes, , a cell. Each cell has an address, which is the column letter and the row number. The, arrow on the worksheet to the right points to cell A1, which is currently highlighted,, indicating that it is an active cell. A cell must be active to enter information into it. To, highlight (select) a cell, click on it., To select more than one cell:, Click on a cell (e.g., A1), then hold the shift key while you click on another (e.g.,, D4) to select all cells between and including A1 and D4., Click on a cell (e.g., A1) and drag the mouse across the desired range, unclicking, on another cell (e.g., D4) to select all cells between and including A1 and D4., To select several cells which are not adjacent, press “control” and click on the, cells you want to select. Click a number or letter labelling a row or column to select, that entire row or column., One worksheet can have up to 256 columns and 65,536 rows, so it’ll be a while, before you run out of space., Each cell can contain a label, value, logical value, or formula., Labels can contain any combination of letters, numbers, or symbols., Values are numbers. Only values (numbers) can be used in calculations. A value, can also be a date or a time, Logical values are “true” or “false.”, Formulas automatically do calculations on the values in other specified cells and, display the result in the cell in which the formula is entered (for example, you can specify, that cell D3 is to contain the sum of the numbers in B3 and C3; the number displayed, in D3 will then be a funtion of the numbers entered into B3 and C3)., , Fig. 4.16, To enter information into a cell, select the cell and begin typing., Self Learning Material 209
Page 210 :
Research Methodology, , Note that as you type information into the cell, the information you enter also, displays in the formula bar. You can also enter information into the formula bar, and, the information will appear in the selected cell., When you have finished entering the label or value:, , Notes, , Press “Enter” to move to the next cell below (in this case, A2), Press “Tab” to move to the next cell to the right (in this case, B1), Click in any cell to select it, , Entering Labels, , Fig. 4.17, Unless the information you enter is formatted as a value or a formula, Excel will, interpret it as a label, and defaults to align the text on the left side of the cell., If you are creating a long worksheet and you will be repeating the same label, information in many different cells, you can use the AutoComplete function. This, function will look at other entries in the same column and attempt to match a previous, entry with your current entry. For example, if you have already typed “Wesleyan” in, another cell and you type “W” in a new cell, Excel will automatically enter “Wesleyan.”, If you intended to type “Wesleyan” into the cell, your task is done, and you can move, on to the next cell. If you intended to type something else, e.g., “Williams,” into the, cell, just continue typing to enter the term., To turn on the AutoComplete funtion, click on “Tools” in the menu bar, then, select “Options,” then select “Edit,” and click to put a check in the box beside “Enable, AutoComplete for cell values.”, Another way to quickly enter repeated labels is to use the Pick List feature. Right, click on a cell, then select “Pick From List.” This will give you a menu of all other, entries in cells in that column. Click on an item in the menu to enter it into the currently, selected cell., , Entering Values, A value is a number, date, or time, plus a few symbols if necessary to further define, the numbers [such as: . , + – ( ) % $ / ]., 210 Self Learning Material
Page 211 :
Numbers are assumed to be positive; to enter a negative number, use a minus sign, “–” or enclose the number in parentheses “()”., Dates are stored as MM/DD/YYYY, but you do not have to enter it precisely in, that format. If you enter “jan 9” or “jan-9”, Excel will recognize it at January 9 of the, current year, and store it as 1/9/2002. Enter the four-digit year for a year other than the, current year (e.g. “jan 9, 1999”). To enter the current day’s date, press “control” and, “;” at the same time., , Analysis of Data, , Notes, , Times default to a 24-hour clock. Use “a” or “p” to indicate “am” or “pm” if you, use a 12-hour clock (e.g. “8:30 p” is interpreted as 8:30 PM). To enter the current time,, press “control” and “:” (shift-semicolon) at the same time., , Fig. 4.18, An entry interpreted as a value (number, date, or time) is aligned to the right side of, the cell, to reformat a value., , Descriptive Statistics, The Data Analysis ToolPak has a Descriptive Statistics tool that provides you with an, easy way to calculate summary statistics for a set of sample data. Summary statistics, includes Mean, Standard Error, Median, Mode, Standard Deviation, Variance, Kurtosis,, Skewness, Range, Minimum, Maximum, Sum, and Count. This tool eliminates the need, to type indivividual functions to find each of these results. Excel includes elaborate and, customisable toolbars, for example, the “standard” toolbar shown here:, , Fig. 4.19, Some of the icons are useful mathematical computation:, is the “Autosum” icon, which enters the formula “=sum()” to add up a range of cells., Self Learning Material 211
Page 212 :
Research Methodology, , is the “FunctionWizard” icon, which gives you access to all the functions available., is the “GraphWizard” icon, giving access to all graph types available, as shown, , Notes, , in this display:, , Fig. 4.20, Excel can be used to generate measures of location and variability for a variable., Suppose we wish to find descriptive statistics for a sample data: 2, 4, 6, and 8., Step 1. Select the Tools *pull-down menu, if you see data analysis, click on this, option, otherwise, click on add-in.. option to install analysis tool pak., Step 2. Click on the data analysis option., Step 3. Choose Descriptive Statistics from Analysis Tools list., Step 4. When the dialog box appears:, Enter A1: A4 in the input range box, A1 is a value in column A and row 1, in, this case this value is 2. Using the same technique enter other VALUES until you reach, the last one. If a sample consists of 20 numbers, you can select for example A1, A2,, A3, etc. as the input range., Step 5. Select an output range, in this case B1. Click on summary statistics to see, the results., Select OK., When you click OK, you will see the result in the selected range., As you will see, the mean of the sample is 5, the median is 5, the standard deviation, is 2.581989, the sample variance is 6.666667, the range is 6 and so on. Each of these, factors might be important in your calculation of different statistical procedures., , Normal Distribution, Consider the problem of finding the probability of getting less than a certain value under, any normal probability distribution. As an illustrative example, let us suppose the SAT, 212 Self Learning Material
Page 213 :
scores nationwide are normally distributed with a mean and standard deviation of 500, and 100, respectively. Answer the following questions based on the given information:, A: What is the probability that a randomly selected student score will be less than 600, points?, B: What is the probability that a randomly selected student score will exceed 600, points?, C: What is the probability that a randomly selected student score will be between 400, and 600?, , Analysis of Data, , Notes, , Hint: Using Excel you can find the probability of getting a value approximately, less than or equal to a given value. In a problem, when the mean and the standard, deviation of the population are given, you have to use common sense to find different, probabilities based on the question since you know the area under a normal curve is 1., , Solution:, In the work sheet, select the cell where you want the answer to appear. Suppose, you, chose cell number one, A1. From the menus, select “insert pull-down”., Steps 2-3 From the menus, select insert, then click on the Function option., Step 4. After clicking on the Function option, the Paste Function dialog appears, from Function Category. Choose Statistical then NORMDIST from the Function, Name box; ClickOK, Step 5. After clicking on OK, the NORMDIST distribution box appears:, 1. Enter 600 in X (the value box);, 2. Enter 500 in the Mean box;, 3. Enter 100 in the Standard deviation box;, 4. Type “true” in the cumulative box, then click OK., As you see the value 0.84134474 appears in A1, indicating the probability that a, randomly selected student’s score is below 600 points. Using common sense we can, answer part “b” by subtracting 0.84134474 from 1. So the part “b” answer is 1 – 0.8413474, or 0.158653. This is the probability that a randomly selected student’s score is greater, than 600 points. To answer part “c”, use the same techniques to find the probabilities or, area in the left sides of values 600 and 400. Since these areas or probabilities overlap, each other to answer the question you should subtract the smaller probability from the, larger probability. The answer equals 0.84134474 – 0.15865526 that is, 0.68269. The, screen shot should look like following:, , Inverse Case, Calculating the value of a random variable often called the “x” value, You can use NORMINV from the function box to calculate a value for the random, variable – if the probability to the left side of this variable is given. Actually, you should, use this function to calculate different per centiles. In this problem, one could ask what, Self Learning Material 213
Page 214 :
Research Methodology is the score of a student whose per centile is 90? This means approximately 90% of, students scores are less than this number. On the other hand, if we were asked to do, this problem by hand, we would have had to calculate the x value using the normal, distribution formula x = m + zd. Now let’s use Excel to calculate P90. In the Paste, function,, dialog click on statistical, then click on NORMINV. The screen shot would, Notes, look like the following:, When you see NORMINV the dialog box appears., 1. Enter 0.90 for the probability (this means that approximately 90% of students’, score is less than the value we are looking for), 2. Enter 500 for the mean (this is the mean of the normal distribution in our case), 3. Enter 100 for the standard deviation (this is the standard deviation of the normal, distribution in our case), At the end of this screen, you will see the formula result which is approximately, 628 points. This means the top 10% of the students scored better than 628., , Confidence Interval for the Mean, Suppose we wish for estimating a confidence interval for the mean of a population., Depending on the size of your sample size you may use one of the following cases:, Large Sample Size (n is larger than, say 30):, The general formula for developing a confidence interval for a population means is:, –, x ± Z•(√S/n), –, In this formula, x is the mean of the sample; Z is the interval coefficient, which, can be found from the normal distribution table (for example, the interval coefficient, for a 95% confidence level is 1.96). S is the standard deviation of the sample and n is, the sample size., Now we would like to show how Excel is used to develop a certain confidence, interval of a population mean based on a sample information. As you see in order, –, to evaluate this formula you need x “the mean of the sample” and the margin of, error “Z•(√S/n)” Excel will automatically calculate these quantities for you., The only things you have to do are:, , –, add the margin of error “Z•(√S/n)” to the mean of the sample, x ; Find the upper, limit of the interval and subtract the margin of error from the mean to the lower limit of, the interval. To demonstrate how Excel finds these quantities we will use the data set,, which contains the hourly income of 36 work-study students here, at the University of, Baltimore. These numbers appear in cells A1 to A36 on an Excel work sheet., After entering the data, we followed the descriptive statistic procedure to calculate, the unknown quantities. The only additional step is to click on the confidence interval in, the descriptive statistics dialog box and enter the given confidence level, in this case 95%., Here is, the above procedures in step-by-step:, Step 1. Enter data in cells A1 to A36 (on the spreadsheet), 214 Self Learning Material
Page 215 :
Analysis of Data, , Step 2. From the menus select Tools, Step 3. Click on Data Analysis then choose the Descriptive Statistics option then, click OK., On the descriptive statistics dialog, click on Summary Statistic., After you have done that, click on the confidence interval level and type 95% - or, in other problems whatever confidence interval you desire. In the Output Range box,, , Notes, , enter B1 or what ever location you desire., Now click on OK. The screen shot would look like the following:, , 95%, , 0.025, , 0.025, , Fig. 4.21, –, As you see, the spreadsheet shows that the mean of the sample is x = 6.902777778, , and the absolute value of the margin of error |± Z•(S/√n)| = 0.231678109. This mean, is based on this sample information. A 95% confidence interval for the hourly income, of the UB work-study students has an upper limit of 6.902777778 + 0.231678109 and, a lower limit of 6.902777778 – 0.231678109., , Fig. 4.22, Self Learning Material 215
Page 216 :
Research Methodology, , Notes, , On the other hand, we can say that of all the intervals formed this way 95% contains, the mean of the population. Or, for practical purposes, we can be 95% confident that, the mean of the population is between 6.902777778 – 0.231678109 and 6.902777778 +, 0.231678109. We can be at least 95% confident that interval [$6.68 and $7.13] contains, the average hourly income of a work-study student., Small Sample Size (say less than 30) If the sample n is less than 30 or we must, use the small sample procedure to develop a confidence interval for the mean of a, population, the general formula for developing confidence intervals for the population, mean based on small a sample is:, –, x ± ta/2•(S/√n), , –, , In this formula, x is the mean of the sample, ta/2 is the interval coefficient providing, an area of a/2 in the upper tail of at distribution with n – 1 degrees of freedom which, can be found from at distribution table (for example, the interval coefficient for a 90%, confidence level is 1.833 if the sample is 10). S is the standard deviation of the sample, and n is the sample size., Now you would like to see how Excel is used to develop a certain confidence, interval of a population mean based on this small sample information., –, As you see, to evaluate this formula you need x “the mean of the sample” and, , the margin of error “ta/2•(S/√n)” Excel will automatically calculate these quantities the, way it did for large samples., Again, the only things you have to do are: add the margin of error “ta/2•(S/√n)” to, –, the mean of the sample, x , find the upper limit of the interval and to subtract the margin, of error from the mean to find the lower limit of the interval., , To demonstrate how Excel finds these quantities we will use the data set, which, contains the hourly incomes of 10 work-study students here, at the University of, Baltimore. These numbers appear in cells A1 to A10 on an Excel work sheet., After entering the data we follow the descriptive statistic procedure to calculate, the unknown quantities (exactly the way we found quantities for large sample). Here, you are with the procedures in step-by-step form:, Step 1. Enter data in cells A1 to A10 on the spreadsheet, Step 2. From the menus select Tools, Step 3. Click on Data Analysis then choose the Descriptive Statistics option., Click OK on the descriptive statistics dialog, click on Summary Statistic, click on the, confidence interval level and type in 90% or in other problems whichever confidence, interval you desire. In the Output Range box, enter B1 or whatever location you desire., Now click on OK. The screen shot will look like the following page:, 216 Self Learning Material
Page 217 :
Now, like the calculation of the confidence interval for the large sample, calculate, , Analysis of Data, , the confidence interval of the population based on this small sample information. The, confidence interval is:, 6.8 ± 0.414426102, , Notes, , or, $6.39<===>$7.21., , Fig. 4.23, We can be at least 90% confidant that the interval [$6.39 and $7.21] contains the, true mean of the population., , Test of Hypothesis Concerning the Population Mean, Again, we must distinguish two cases with respect to the size of your sample, Large Sample Size (say, over 30): In this section, you wish to know how Excel, can be used to conduct a hypothesis test about a population mean. We will use the, hourly incomes of different work-study students than those introduced earlier in the, confidence interval section. Data are entered in cells A1 to A36. The objective is to test, the following Null and Alternative hypothesis:, H0: m = 6, Ha: m ± 7, Self Learning Material 217
Page 218 :
Research Methodology, , The null hypothesis indicates that the average hourly income of a work-study, student is equal to $7 per hour; however, the alternative hypothesis indicates that the, average hourly income is not equal to $7 per hour., , Notes, , I will repeat the steps taken in descriptive statistics and at the very end will show, how to find the value of the test statistics in this case, z, using a cell formula., Step 1. Enter data in cells A1 to A36 (on the spreadsheet), , Fig. 4.24, Step 2. From the menus select Tools, Step 3. Click on Data Analysis then choose the Descriptive Statistics option, click OK., On the descriptive statistics dialog, click on Summary Statistic. Select the Output, Range box, enter B1 or whichever location you desire. Now click OK., (To calculate the value of the test statistics search for the mean of the sample then, the standard error. In this output, these values are in cells C3 and C4.), Step 4. Select cell D1 and enter the cell formula = (C3 – 7)/C4. The screen shot, should look like the following:, The value in cell D1 is the value of the test statistics. Since this value falls in, acceptance range of –1.96 to 1.96 (from the normal distribution table), we fail to reject, the null hypothesis., Small Sample Size (say, less than 30), Using steps taken the large sample size case, Excel can be used to conduct a hypothesis, for small-sample case. Let’s use the hourly income of 10 work-study students at UB to, conduct the following hypothesis., 218 Self Learning Material
Page 219 :
Analysis of Data, , H0: m = 7, Ha: m ± 7, The null hypothesis indicates that average hourly income of a work-study student, is equal to $7 per hour. The alternative hypothesis indicates that average hourly income, is not equal to $7 per hour., , Notes, , I will repeat the steps taken in descriptive statistics and at the very end will show, how to find the value of the test statistics in this case “t” using a cell formula., Step 1. Enter data in cells A1 to A10 (on the spreadsheet), Step 2. From the menus select Tools, Step 3. Click on Data Analysis then choose the Descriptive Statistics option. Click OK., On the descriptive statistics dialog, click on Summary Statistic. Select the Output, Range boxes, enter B1 or whatever location you chose. Again, click on OK., (To calculate the value of the test statistics search for the mean of the sample then the standard, error, in this output these values are in cells C3 and C4.), Step 4. Select cell D1 and enter the cell formula = (C3 – 7)/C4. The screen shot, would look like the following:, Since the value of test statistic t = –0.66896 falls in acceptance range –2.262 to, +2.262 (from t table, where, , a/2 = 0.025 and the degrees of freedom is 9), we fail to, , reject the null hypothesis., , Fig. 4.25: Variable View in SPSS, Self Learning Material 219
Page 220 :
Research Methodology Difference Between Mean of Two Populations, , Notes, , In this section, we will show how Excel is used to conduct a hypothesis test about the, difference between two population means assuming that populations have equal variances., The data in this case are taken from various offices here at the University of Baltimore., I collected the hourly income data of 36 randomly selected work-study students and 36, student assistants. The hourly income range for work-study students was $6–$8 while, the hourly income range for student assistants was $6–$9. The main objective in this, hypothesis testing is to see whether there is a significant difference between the means of, the two populations. The NULL and the ALTERNATIVE hypothesis is that the means, are equal and the means are not equal, respectively., Referring to the spreadsheet, I chose A1 and A2 as label centers. The work-study, students’ hourly income for a sample size 36 are shown in cells A2:A37, and the student, assistants’ hourly income for a sample size 36 is shown in cells B2:B37, Data for Work Study Student: 6, 6, 6, 6, 6, 6, 6, 6.5, 6.5, 6.5, 6.5, 6.5, 6.5, 7, 7, 7,, 7, 7, 7, 7, 7.5, 7.5, 7.5, 7.5, 7.5, 7.5, 8, 8, 8, 8, 8, 8, 8, 8, 8., Data for Student Assistant: 6, 6, 6, 6, 6, 6.5, 6.5, 6.5, 6.5, 6.5, 7, 7, 7, 7, 7, 7.5,, 7.5, 7.5, 7.5, 7.5, 7.5, 8, 8, 8, 8, 8, 8, 8, 8.5, 8.5, 8.5, 8.5, 8.5, 9, 9, 9, 9., Use the Descriptive Statistics procedure to calculate the variances of the two, samples. The Excel procedure for testing the difference between the two population means, will require information on the variances of the two populations. Since the variances of, the two populations are unknowns they should be replaced with sample variances. The, descriptive for both samples show that the variance of first sample is s12 = 0.55546218,, while the variance of the second sample s22 =0.969748., work-study student, , 220 Self Learning Material, , student assistant, , Mean, , 7.05714286, , Mean, , 7.471429, , Standard Error, , 0.12597757, , Standard Error, , 0.166454, , Median, , 7, , Median, , 7.5, , Mode, , 8, , Mode, , 8, , Standard Deviation, , 0.74529335, , Standard Deviation, , 0.984758, , Sample Variance, , 0.55546218, , Sample Variance, , 0.969748, , Kurtosis, , –1.38870558, , Kurtosis, , –1.192825, , Skewness, , –0.09374375, , Skewness, , –0.013819, , Range, , 2, , Range, , 3, , Minimum, , 6, , Minimum, , 6
Page 221 :
Maximum, , 8, , Maximum, , 9, , Sum, , 247, , Sum, , 261.5, , Count, , 35, , Count, , 35, , To conduct the desired test hypothesis with Excel the following steps can be taken:, , Analysis of Data, , Notes, , Step 1. From the menus select Tools then click on the Data Analysis option., Step 2. When the Data Analysis dialog box appears:, Choose z-Test: Two Sample for means then click OK, Step 3. When the z-Test: Two Sample for means dialog box appears:, Enter A1:A36 in the variable 1 range box (work-study students’ hourly income), Enter B1:B36 in the variable 2 range box (student assistants’ hourly income), Enter 0 in the Hypothesis Mean Difference box (if you desire to test a mean difference, other than 0, enter that value), Enter the variance of the first sample in the Variable 1 Variance box, Enter the variance of the second sample in the Variable 2 Variance box and select Labels, Enter 0.05 or, whatever level of significance you desire, in the Alpha box, Select a suitable Output Range for the results, I chose C19, then click OK., The value of test statistic z = –1.9845824 appears in our case in cell D24. The, rejection rule for this test is z < –1.96 or z > 1.96 from the normal distribution table. In the, Excel output, these values for a two-tail test are z < –1.959961082 and z > +1.959961082., Since the value of the test statistic z = –1.9845824 is less than –1.959961082 we reject, the null hypothesis. We can also draw this conclusion by comparing the p-value for a, two tail-test and the alpha value., Since p-value 0.047190813 is less than a = 0.05 we reject the null hypothesis., Overall we can say, based on the sample results, the two populations’ means are different., , Small Samples: n1 OR n2 are less than 30, In this section, we will show how Excel is used to conduct a hypothesis test about the, difference between two population means. Given that the populations have equal variances, when two small independent samples are taken from both populations. Similar to the, above case, the data in this case are taken from various offices here at the University of, Baltimore. I collected hourly income data of 11 randomly selected work-study students, and 11 randomly selected student assistants. The hourly income range for both groups, was similar range, $6–$8 and $6–$9. The main objective in this hypothesis testing is, similar too, to see whether there is a significant difference between the means of the, two populations. The NULL and the ALTERNATIVE hypothesis are that the means, are equal and they are not equal, respectively., Self Learning Material 221
Page 222 :
Research Methodology, , Work-study student, 6, 8, 7.5, 6.5, 7, 6, 7.5, 8, 6, 6.5, 7, , Notes, , Student assistant, 6, 9, 8.5, 7, 6.5, 7, 7.5, 6, 8, 9, 7.5>, , Referring to the spreadsheet, we chose A1 and A2 as label centers. The workstudy students’ hourly income for a sample size 11 are shown in cells A2:A12, and the, student assistants’ hourly income for a sample size 11 is shown in cells B2:B12. Unlike, previous case, you do not have to calculate the variances of the two samples, Excel will, automatically calculate these quantities and use them in the calculation of the value of, the test statistic., Similar to the previous case, but a bit different in step # 2, to conduct the desired, test hypothesis with Excel the following steps can be taken:, Step 1. From the menus select Tools then click on the Data Analysis option., Step 2. When the Data Analysis dialog box appears:, Choose t-Test: Two Sample Assuming Equal Variances then click OK, Step 3. When the t-Test: Two Sample Assuming Equal Variances dialog box appears:, Enter A1:A12 in the variable 1 range box (work-study student hourly income), Enter B1:B12 in the variable 2 range box (student assistant hourly income), Enter 0 in the Hypothesis Mean Difference box (if you desire to test a mean difference, other than zero, enter that value) then select Labels, Enter 0.05 or, whatever level of significance you desire, in the Alpha box, Select a suitable Output Range for the results, I chose C1, then click OK., The value of the test statistic t = –1.362229828 appears, in our case, in cell D10. The, rejection rule for this test is t < –2.086 or t > +2.086 from the t distribution table where, the t value is based on a t distribution with n1– n2–2 degrees of freedom and where the, area of the upper one tail is 0.025 ( that is equal to alpha/2)., , In the Excel output, the values for a two-tail test are t < –2.085962478 and t >, +2.085962478. Since the value of the test statistic t = –1.362229828, is in an acceptance, range of t < –2.085962478 and t > +2.085962478, we fail to reject the null hypothesis., 222 Self Learning Material
Page 223 :
We can also draw this conclusion by comparing the p-value for a two-tail test and, the alpha value., Since the p-value 0.188271278 is greater than a = 0.05 again, we fail to reject the, null hypothesis., Overall we can say, based on sample results, the two populations’ means are equal., Work-study student, , Student assistant, , Mean, , 6.909090909, , 7.454545455, , Variance, , 0.590909091, , 1.172727273, , Observations, , 11, , 11, , Pooled Variance, , 0.881818182, , Hypothesized Mean Difference, , 0, , Df, , 20, , t Stat, , –1.362229828, , P(T<=t) one tail, , 0.094135639, , t Critical one tail, , 1.724718004, , P(T<=t)two tail, , 0.188271278, , t Critical two tail, , 2.085962478, , Analysis of Data, , Notes, , ANOVA: Analysis of Variances, In this section, the objective is to see whether or not means of three or more populations, based on random samples taken from populations are equal or not. Assuming independents, samples are taken from normally distributed populations with equal variances, Excel, would do this analysis if you choose one way anova from the menus. We can also, choose Anova: two way factor with or without replication option and see whether there, is significant difference between means when different factors are involved., , Single-Factor ANOVA Test, In this case, we were interested to see whether there a significant difference among, hourly wages of student assistants in three different service departments here at the, University of Baltimore. Six student assistants were randomly were selected from the, three departments and their hourly wages were recorded as following:, ARC, 10.00, 8.00, 7.50, 8.00, 7.00, , CSI, 6.50, 7.00, 7.00, 7.50, 7.00, , TCC, 9.00, 7.00, 7.00, 7.00, 6.50, Self Learning Material 223
Page 224 :
Research Methodology Enter data in an Excel work sheet starting with cell A2 and ending with cell C8. The, following steps should be taken to find the proper output for interpretation., Step 1. From the menus select Tools and click on Data Analysis option., , Notes, , Step 2. When data analysis dialog appears, choose Anova single-factor option;, enter A2:C8 in the input range box. Select labels in first row., Step 3. Select any cell as output(in here we selected A11). Click OK., The general form of Anova table looks like following:, Source of Variation, Between Groups, Within Groups, , SS, , df, , MS, , F, , P-value, , F crit, , SSTR K–1 MSTR MST/MSE 0.046725 3.682316674, SSE, , nt–K, , MSE, , Total, Suppose the test is done at level of significance a = 0.05, we reject the null, hypothesis. This means there is a significant difference between means of hourly incomes, of student assistants in these departments., , The Two-way ANOVA Without Replication, In this section, the study involves six students who were offered different hourly wages in, three different department services here at the University of Baltimore. The objective is to, see whether the hourly incomes are the same. Therefore, we can consider the following:, , Factor: Department, Treatment: Hourly payments in the three departments, Blocks: Each student is a block since each student has worked in the three different, departments, Student, 1, 2, 3, 4, 5, 6, , ARC, 10.00, 8.00, 7.00, 8.00, 9.00, 8.00, , CSI, 7.50, 7.00, 6.00, 6.50, 8.00, 8.00, , TCC, 7.00, 6.00, 6.00, 6.50, 7.00, 6.00, , The general form of Anova table would look like:, Source of, Variation, , 224 Self Learning Material, , Sum of, Squares, , Degrees of, freedom, , Mean, Squares, , F, , Treatment, , SST, , K–1, , MST, , F = MST/, MSE, , Blocks, , SSB, , b–1, , MSB, , Error, , SSE, , (K–1)(b–1), , MSB, , Total, , SST, , nt–1
Page 225 :
To find the Excel output for the above data the following steps can be taken:, , Analysis of Data, , Step 1. From the menus select Tools and click on Data Analysis option., Step 2. When data analysis box appears: select Anova two-factor without replication, then Enter A2: D8 in the input range. Select labels in first row., Step 3. Select an output range (in here we selected A11) then OK., SUMMARY, , COUNT, , SUM, , AVERAGE, , VARIANCE, , 1, , 3, , 24.5, , 8.166667, , 2.583333, , 2, , 3, , 21, , 7, , 1, , 3, , 3, , 19.5, , 6.5, , 0.25, , 4, , 3, , 21.5, , 7.166667, , 0.583333, , 5, , 3, , 23, , 7.666667, , 2.333333, , 6, , 3, , 22, , 7.333333, , 1.333333, , ARC, , 6, , 50, , 8.333333, , 1.066667, , CSI, , 6, , 43, , 7.166667, , 0.666667, , TCC, , 6, , 38.5, , 6.416667, , 0.241667, , Notes, , ANOVA, Source of Variation, , SS, , df, , Rows, , 4.902778 5, , 0.980556 1.972067 0.168792 3.325837, , Columns, , 11.19444, , 5.597222 11.25698, , Error, , 4.972222 10 0.497222, , Total, , 21.06944 17, , 2, , MS, , F, , P-value, , F crit, , 0.002752 4.102816, , NOTE: F = MST/MSE = 0.980556/0.497222 = 1.972067, F = 3.33 from table (5 numerator DF and 10 denominator DF), Since 1.972067 < 3.33 we fail to reject the null., Conclusion: There is not sufficient evidence to conclude that hourly rates differ, for the three departments., , Two-Way ANOVA with Replication, Referring to the student assistant and the work study hourly wages here at the University, of Baltimore the following data shows the hourly wages for the two categories in three, different departments:, Self Learning Material 225
Page 226 :
Research Methodology, , Work Study, , Notes, , Student Assistant, , ARC, , CSI, , TCC, , 6.50, , 6.10, , 6.90, , 6.80, , 6.00, , 7.20, , 7.10, , 6.50, , 7.10, , 7.40, , 6.80, , 7.50, , 7.50, , 7.00, , 7.00, , 8.00, , 6.60, , 7.10, , Factors, Factor A: Student job category (in here two different job categories exists), Factor B: Departments (in here we have three departments), Replication: The number of students in each experimental condition. In this case, there are three replications., , Interaction:, , Work Study, , Student Assistant, , SUMMARY, , ARC, , CSI, , TCC, , 6.50, , 6.10, , 6.90, , 6.80, , 6.00, , 7.20, , 7.10, , 6.50, , 7.10, , 7.40, , 6.80, , 7.50, , 7.50, , 7.00, , 7.00, , 8.00, , 6.60, , 7.10, , ARC, , CSI, , TCC, , Total, , 3, , 3, , 3, , 9, , Sum, , 20.4, , 19, , 21, , 60.2, , Average, , 6.8, , 6.2, , 7.1, , 6.69, , Variance, , 0.09, , 0.1, , 0, , 0.19, , Count, , Count, , 3, , 3, , 3, , 9, , Sum, , 22.9, , 20, , 22, , 64.9, , Average, , 7.63333, , 6.8, , 7.2, , 7.21, , Variance, , 0.10333, , 0, , 0.1, , 0.18, , Total, 226 Self Learning Material
Page 227 :
Analysis of Data, , Total, Count, , 6, , 6, , 6, , Sum, , 43.3, , 39, , 43, , Average, , 7.21667, , 6.5, , 7.1, , Variance, , 0.28567, , 0.2, , 0, , Notes, , ANOVA, Source of Variation, , SS, , df, , MS F, , P-value, , F crit, , Sample(Factor A), , 1.22722, , 1, , 1.2, , 18.6, , 0.001016557, , 4.747221, , Columns(Factor B), , 1.84333, , 2, , 0.9, , 13.9, , 0.000741998, , 3.88529, , Interaction, , 0.38111, , 2, , 0.2, , 2.88, , 0.095003443, , 3.88529, , Within, , 0.79333, , 12 0.1, , Total, , 4.245, , 17, , Conclusion, Mean hourly income differ by job category., Mean hourly income differ by department., Interaction is not significant., , 4.27 �The Statistical ProgramMe for Social Scientists (SPSS), The SPSS Corporation first produced the SPSS software package in the early 1980’s, and has recently released version 11.0. It is presently one of the most commonly used, statistical packages in various research institutions. The advantages of the package are, its relative ease of use, its familiarity to many statistical experts and its functionality., One of SPSS’s major disadvantages is its cost. The SPSS Corporation appears to be, progressively breaking up the programme into different sections that can be purchased, separately. The different versions have varying analytical functions and different capacities, in terms of the number of cases and variables that can be used. An institutional license, costs even more, depending on the number of expected users. The different packages, have licenses that also differ. In most cases, licenses are set up to expire automatically, after a limited period after which the package can no longer be used. The package is, developed for a number of operating systems including Windows and Unix. Information, about SPSS products is available on-line at www.SPSS.com., , 4.28 Organization of the SPSS Package, The set-up of the version 10.0 package (used for illustration here) is organised into two, main sections, for defining and entering data and for output. When defining and entering, Self Learning Material 227
Page 228 :
Research Methodology data, users can move between the ‘variable’ and ‘data’ ‘views’ by clicking on the tabs, at the bottom of the screen. The third ‘output’ section opens in a separate window and, displays the results of the statistical analyses. The ‘output’ data are saved as a separate, file to the data set., , Notes, , Fig. 4.26: Variable View in SPSS, In the ‘variable view’ (Fig. 17.11), the users sets up the data entry and analysis, cells by naming and defining the variables included in the data set. Users are required, to use names for the variables of eight or fewer characters. Names must begin with an, alphabetic character. Longer descriptions of the variables can be added using the ‘Labels’, dialog box (Fig. 17.12). A quick way to define the variable format (including the variable, type, the number of characters used and labels) if a number of variables have a similar, format, copy the attributes of a variable then paste them into other variable fields., , Fig. 4.27: Defining Variable Labels using the Value Labels Dialog Box, 228 Self Learning Material
Page 229 :
Analysis of Data, , Notes, , Fig. 4.28: Entering Data into the SPSS, Once the variables to be recorded have been named and defined the user can access, the ‘data view’ to enter in the values for each variable. The SPSS data view looks similar, to a spreadsheet programme. The variables are organised as columns with each row as, a single ‘case’ in the data set containing values for the variables relating to that case., It is a common practice to use codes to enter data into the package and labels can be, used to describe values where needed. For example, codes may be used to record the, types of agriculture practised on a landholding, or respondent’s educational levels. The, defined labels will appear, by clicking the drop-down list arrow on the right side of the, cell, and the user can select the relevant value (Fig. 17.13)., This is handy, when there are a large number of possible responses and thus codes,, for a variable, and the user cannot remember all of them. The user can choose to have, the codes or the labels displayed in the data view by selecting the ‘Value labels’ option, under the ‘View’ menu., , 4.29 Data analysis using SPSS, The SPSS ‘student pack’ has a wide range of analytical functions, from basic descriptive, statistics to advanced general linear modeling capabilities. Specific functions are also, included to allow the transformation of variables as preparation for different tests, (e.g., for creating standardised or logarithmic values, or the calculation of scales from, a number of variables) (Fig. 17.14). The use of these functions allows researchers to, Self Learning Material 229
Page 230 :
Research Methodology calculate quickly new variables based on the values of other variables, test variations, in category schemes used to classify responses to ‘open ended’ questions, and collapse, categories where necessary., , Notes, , Fig. 4.29: Data Transformation Function in SPSS, , Fig. 4.30: Frequencies Dialog Box, Once the data are entered into the SPSS program it is important to check the, database for typographic errors that may affect the results of statistical analyses. One, means of achieving this is to examine the frequencies of categorical (nominal) data, and, descriptive statistics of numeric (ordinal, scale or interval) data. All of the analytical, functions available in SPSS can be accessed using the ‘Analyse’ menu (Fig. 17.16). If, the ‘Descriptive statistics’ then the ‘Frequencies’ options are selected, the dialog box, 230 Self Learning Material
Page 231 :
illustrated in Fig. 17.15 appears. This dialog box enables users to select the variables, for which frequencies are computed as well as control the types and, to a limited extent,, the formatting of displays of the analyses., , Analysis of Data, , Notes, , Fig. 4.31: Analysis Options Available in SPSS, If calculation of descriptive statistics is required, users should select ‘Descriptive, statistics’ and the ‘Descriptives’ options under the Analysis menu to reveal the, ‘Descriptives’ dialog box (Fig. 17.17), , Fig. 4.32: Descriptive Function Dialog Box, Once the ‘Descriptives’ dialog box is shown, the variables to be included in the, analyses are selected from the list on the left side of the box (Fig. 17.17), and transferred, Self Learning Material 231
Page 232 :
Research Methodology to the list on the right side of the box (labeled ‘Variables’ in Fig. 17.17) using the arrow, in the centre of the box. The types of descriptive statistics that will be calculated using, this function can be selected by clicking on the ‘Options…’ button (Fig. 17.17). This, reveals the ‘Options’ dialog box for the Descriptives function (Fig. 17.18)., , Notes, , Fig. 4.33: Options Dialog Box for the ‘Descriptives’ Function Dialog Box, Other analytical functions included in the SPSS student pack (Version 10) include, chi-square tests, correlations, regressions, principal components analyses, ANOVA,, cluster analyses, general linear modeling and more., Whilst this unit does not attempt to provide the reader with statistical skills, the, flowchart in Fig. 17.19 may act as a guide for the reader to access quickly those functions, in SPSS that will best serve their statistical analysis needs., The analytical functions are adequate for all but the most advanced researchers or, those requiring highly specific analyses. Most advanced or specific applications can be, met as well, with SPSS open to manipulation via user compiled ‘Sax Basic’ computer, code (also known as ‘scripts’ in SPSS). This is similar to the use of the Visual Basic, programming language to develop and execute macros in Microsoft Excel. The Sax, Basic language is compatible with Visual Basic for Applications., , 4.30, , Using SPSS to Describe Data, , Whilst computer-based statistical packages provide a high degree of functionality, with regard to data analysis, they also provide a number of highly useful tools for the, description and presentation of summaries of the dataset., 232 Self Learning Material
Page 233 :
Analysis of Data, , Notes, , Fig. 4.34: Custom Tables Drop-down Menu Selections, These functions include Descriptives and Frequencies as explained earlier and, Crosstabs, also found under the Descriptive Statistics menu, and Basic Tables, General, Tables, Multiple Response Tables and Tables of Frequencies all located under the Custom, Tables menu item (Fig.). It is often useful to undertake one or more of these processes, before commencing data analysis to identify any weaknesses in the dataset such as, poorly represented groups within the sample that may limit the statistical validity of, some forms of analysis. Crosstabs are also an efficient way of presenting data summaries, in research and project reports., , Fig. 4.35: Design Options for a Simple Scatterplot, Self Learning Material 233
Page 234 :
Research Methodology, , Notes, , The charting functions available in SPSS also provide a number of techniques for, the initial exploration and the presentation of data. Scatter Plots (Figures and 17.22), can be used to identify quickly the presence and nature of any correlations between, variables while Histograms (Figures ) can be used to present a graphical representation, of the shape of the distribution of the data for important variables., There is a reasonable amount of literature available to assist users of the SPSS, package produced by the SPSS Corporation and by independent authors. The tutorial, and help facilities for the package are comprehensive, generally easy to understand and, include the on-line Statistics Coach and Syntax Guide., , Fig. 4.36: Simple Scatterplot Displayed in the Output Viewer, , Fig. 4.37: Design Options for Histogram, 234 Self Learning Material
Page 235 :
Analysis of Data, , Notes, , Fig. 4.38: Histogram Displayed in the Output Viewer, , 4.31 Summary, Data when collected is raw in nature. When processed, it becomes information without, data analysis, and interpretation, researcher cannot draw any conclusion. There are several, steps in data processing such as editing, coding and tabulation. The main idea of editing, is to eliminate errors. Editing can be done in the field or by sitting in the office. Coding, is done to enter the data to the computer. In other words, coding speeds up tabulation., Tabulation refers to placing data into different categories. Tabulation may be one-way,, two-ways or cross tabulation. Several statistical tools such as mode, median and mean, are used. Lastly, interpretation of the data is required to bring out meaning or we can say, data is converted into information. Interpretation can use either induction or deduction, logic. While interpreting certain precautions are to be taken., By analysis we mean the computation of certain indices or measures along with, searching for patterns of relationship that exist among the data groups. Analysis,, particularly in case of survey or experimental data, involves estimating the values of, unknown parameters of the population and testing of hypotheses for drawing inferences., Analysis may, therefore, be categorised as: descriptive analysis and inferential, analysis (Inferential analysis is often known as statistical analysis)., Selecting the appropriate statistical technique for investigating a given relationship, depends upon the level of measurement (nominal, ordinal, interval) and the number of, Self Learning Material 235
Page 236 :
Research Methodology variables to be analysed. The choice of parametric vs. non-parametric analyses depends, upon the analyst’s willingness to accept the distributional assumptions of normality, and homogeneity of variances. Finally, univariate hypothesis testing was demonstrated, using the standard normal distribution statistic (z) to compare a mean and proportion, Notes, to the population values. The t-test is demonstrated as a parametric test for populations, of unknown variance and samples of small size. The chi-square goodness of fit test, is demonstrated as a non-parametric test of nominal data that make no distributional, assumptions. The observed frequencies are compared to an expected distribution., In this unit, we have focused upon univariate analyses. Unit-12 expands this, discussion to include non-parametric and parametric analyses involving two variables., In Unit-12, we also focus on bivariate analyses involving Measures of Association., Finally, Unit-13 and 14, we focus on multivariate analyses, involving dependence, and, interdependence of associative data., In each unit, we will observe that the appropriate statistical technique is selected, in, part based on the number of variables and their relationship, when included in the analysis., However, without higher levels of measurement and their associated characteristics of, central tendency dispersion and rates of change, the ability to investigate these more, complex relationships is not possible., The most commonly used measure of central tendency is the mean. To compute the, mean, you add up all the numbers and divide by how many numbers there are. It’s not, the average nor a halfway point, but a kind of center that balances high numbers with, low numbers. For this reason, it’s most often reported along with some simple measure, of dispersion, such as the range, which is expressed as the lowest and highest number., The most common measures of position are percentiles, quartiles, and standard, scores (aka, z-scores). Both correlation and simple linear regression can be used to, examine the presence of a linear relationship between two variables providing certain, assumptions about the data are satisfied. The results of the analysis, however, need to, be interpreted with care, particularly when looking for a causal relationship or when, using the regression equation for prediction., In this unit, you have studied about inferential data analysis. Inferential statistics, involves you taking several samples and trying to find one that accurately represents, the population as a whole. You then test that sample and use it to make generalizations, about the entire population, which in this case is every student within the school., There are two methods used in inferential statistics: the first involves estimating, the parameter and the second involves testing the statistical hypothesis., The distribution of an average tends to be Normal, even when the distribution from, which the average is computed is decidedly non-Normal. Furthermore, the limiting, normal distribution has the same mean as the parent distribution and variance equal to, the variance of the parent divided by the sample size., 236 Self Learning Material
Page 237 :
In this unit, we have studied about various types of inferential data analysis. There, are various statistical tools available to do so. Homogeneity of variance is an underlying, assumption between some tests such as analysis of variance (ANOVA). ANOVA is a, statistical method used to compare the means of two or more groups. There are various, types of ANOVA such as one way ANOVA, two way independent ANOVA, two-way, dependent ANOVA, etc., , Analysis of Data, , Notes, , Partial correlation is a method used to describe the relationship between two, variables whilst taking away the effects of another variable, or several other variables,, on this relationship. When there are two or more than two independent variables, the, analysis concerning relationship is known as multiple correlation and the equation, describing such relationship as the multiple regression equation., Lastly, we have discussed about various types of non-parametric tests such as, chi-square test and Mann-Whitney test. We have also discussed the concept of outliers., Researchers frequently collect large quantities of data, from surveys, experiments, and other forms of observation. A statistical computing package provides a convenient, means to store these data, and derive descriptive and inferential statistics. The Statistical, Package for the Social Sciences (SPSS) is a widely used general-purpose survey analysis, package, and hence a useful one to master. It is necessary to allow some learning time, to become familiar with this package, and annual license fees can be a disincentive., , 4.32 Glossary, zz Editing:, , Editing involves inspection and correction of each questionnaire., , zz Tabulation:, , Tabulation refers to counting the number of cases that fall into, various categories., , zz Coding:, , Coding refers to those activities which helps in transforming edited, questionnaires into a form that is ready for analysis., , zz Standard deviation: Standard deviation represents a set of numbers indicating the, , spread, or typical distance between a single number and the set’s average., zz Standard, , error: Standard error is the standard deviation of a sampling, distribution., , zz Mean:, , Mean, or average, is a word describing the average calculated over an, entire population., , zz Quartiles:, , Any of the three values which divide a sorted data set into four, equal parts, each part representing 1/4th of the sample or population., , zz Percentiles:, , The values that divide a rank-ordered set of elements into 100, equal parts are called percentiles., , zz Correlation:, , It is a technique for investigating the relationship between two, quantitative and continuous variables., Self Learning Material 237
Page 238 :
zz Linear regression analysis: Linear regression analysis is a powerful technique, , Research Methodology, , used for predicting the unknown value of a variable from the known value of, another variable., zz Central, , limit theorem: The central limit theorem states that the sampling, distribution of any statistic will be normal or nearly normal, if the sample size, is large enough., , Notes, , zz T-test: A t-test is a common statistical test used to compare two groups, typically, , two groups’ means (the difference of two means divided by a measure of, variability). A t-test takes into account the number of units in the sample., zz Population:, , A population is all of the members contained within a group., , zz Mean: The mean or arithmetic mean or average is simply the total sum of all the, , numbers in a data set, divided by the number of different data points., zz Median:, , The middle data point in a data set., , zz Mode:, , The most common data point in a data set. This is the value that occurs, with greatest frequency., , zz ANOVA:, , ANOVA is a statistical method used to compare the means of two, or more groups., , zz Partial, , correlation: Partial correlation is a method used to describe the, relationship between two variables whilst taking away the effects of another, variable, or several other variables, on this relationship., , zz Chi-Square, , Test for Goodness of Fit Test: The Chi-Square Test for Goodness, of Fit tests claims about population proportions. It is a non-parametric test that, is performed on categorical (nominal or ordinal) data., , zz Chi-Square, , Test for Independence: The Chi-Square Test for Independence, evaluates the relationship between two variables. It is a non-parametric test that, is performed on categorical (nominal or ordinal) data., , zz SPSS:, , A statistical package from SPSS Inc., Chicago (www.spss.com) that, runs on PCs, most mainframes and minis and is used extensively in marketing, research., , 4.33, , Review Questions, , 1. What is data processing?, 2. What are the steps in data processing?, 3. What is editing?, 4. What is meant by analysis of data?, 5. Discuss different stages of editing., 6. What is coding? What are the guidelines to codify the data?, 238 Self Learning Material
Page 239 :
7. What is tabulation? Discuss different kinds of tabulation., , Analysis of Data, , 8. How to summarize and classify the collected data?, 9. What are the various techniques of data analysis? Describe in detail., 10. What are the three measures of central tendency?, 11. How do you measure dispersion?, , Notes, , 12. What is confidence interval?, 13. Define standard deviation., 14. Give any two examples of parametric tests., 15. Write difference between parametric and non-parametric tests., 16. Discuss main types of descriptive tests?, 17. What is normal distribution? Explain its use in research methodology., 18. What is standard deviation? Explain its importance., 19. What are the various statistical measures of relative position?, 20. What are the various measures of relationship?, 21. Name the two coefficients of correlation., 22. Define the following:, (i), , Percentile, , (ii), , Quartile, , (iii), , Standard score, , 23. What is percentile? List the steps How to calculate percentile., 24. Discuss the steps to calculate quartile., 25. Describe steps of conducting correlation analysis., 26. Discuss the technique of regression., 27. What do you mean by a standard score? Discuss its use., 28. Define the following:, (i), Mean, (ii), , Sample, , (iii), , spopulation, , 29. What is the T-test?, 30. What are parametric tests?, 31. State central limit theorem. Discuss the basic principles of the CLT., 32. Describe the use of sign test., 33. Discuss the use of z-test., Self Learning Material 239
Page 240 :
Research Methodology, , 34. Explain the application of student’s t distribution., 35. What is ANCOVA?, 36. Define partial correlation., 37. List any two non-parametric tests., , Notes, , 38. What is ANOVA? What are its assumptions?, 39. List the steps of performing an Anova test., 40. Explain the test of partial correlation., 41. Explain chi-square test using an example., 42. What is Mann Whitney U-test? Explain in detail., 43. What are outliers? What is its use?, 44. What is SPSS?, 45. List any two advantages of using SPSS., 46. List any two disadvantages of using SPSS., 47. Discuss any two statistical tests using MS Excel., 48. Explain the use of statistical software in research., 49. Describe the organization of SPSS., 50. Explain data analysis using SPSS., 51. How will you use SPSS to describe data?, , 4.34, , Further Readings, , 1. C.R. Kothari, Research Methodology, Willey International Ltd., New Delhi, 2. William J. Goode and Paul K. Hatt, Methods in Social Research, McGraw Hill,, New Delhi, 3. C.A. Moser and G. Kalton, Survey Methods in Social Investigation, 4. P.L. Bhandar Kar and T.S. Wilkinson, Methodology and Techniques of Social, Research, Himalaya Publishing House, Delhi, 5. V.P. Michael, Research Methodology in Management, Himalaya Publishing House,, Delhi, 6. S.R. Bajpai, Methods of Social Survey and Research, Kitab Ghar, Kanpur, 7. M.H. Gopal, An Introduction to Research Procedure in Social Sciences, Asian, Publishing House, Bombay, , 240 Self Learning Material
Page 241 :
UNIT–5, , Report Preparation, , Report Preparation, , Notes, , (Structure), 5.1, , Learning Objectives, , 5.2, , Introduction, , 5.3, , Types of Report, , 5.4, , Preparation of Research Report, , 5.4, , How to Make Interpretations, , 5.5, , Significance of Report Writing, , 5.6, , Mechanics of Writing a Research Report, , 5.8, , How to Write a Bibliography, , 5.9, , Precautions for Writing Research Reports, , 5.10, , Effective Report Writing, , 5.11, , Use of Figures, , 5.12, , Use of Tables in Report, , 5.13, , Use of Graphs in Report, , 5.14, , Organizing and Numbering, , 5.15, , Use of Headings in Report, , 5.16, , Reference Lists and Referencing, , 5.17, , Use of Appendices, , 5.18, , Editing, , 5.19, , Giving Effective to Report Presentation, , 5.20, , Summary, , 5.21, , Glossary, , 5.22, , Review Questions, , 5.23, , Further Readings, , 5.1 Learning Objectives, After studying the chapter, students will be able to:, zz Know, , what is an oral report and what are the guidelines to oral report, presentation;, Self Learning Material 241
Page 242 :
Research Methodology, , zz Explain, , what are the types of written reports;, , zz Discuss, , what is the difference between an oral report and a written report;, , zz Know, , Notes, , how to prepare a research report;, , zz Explain, , how to write a bibliography;, , zz Discuss, , the basics of effective report writing;, , zz Describe, , effective use of figures, tables and graphs in report;, , zz Understand, zz Learn, , how to edit a report;, , effective report presentation skills., , 5.2 Introduction, Reporting research is an essential component of the research and knowledge translation, process (KT). Knowledge translation is facilitated when research is reported and, communicated with sufficient depth and accuracy for readers to interpret, synthesize,, and utilize the study findings. This unit emphasizes on reporting, types of reports and, how to interpret the qualitative and quantitative data, and contents of report., The ideas you present in your report will only have their full value recognised when, they are clearly expressed in logical, cohesive text that is easy to follow. Being able to, present your ideas effectively, in a cohesive manner, will allow readers and markers of, your report to have the satisfaction of understanding your ideas and will allow you to, have the satisfaction of having your ideas understood!, , 5.3 Types of Report, There are two types of reports (1) Oral report, (2) Written report., Oral Report, This type of reporting is required, when the researchers are asked to make an oral, presentation. Making an oral presentation is somewhat difficult compared to the written, report. This is because the reporter has to interact directly with the audience. Any faltering, during an oral presentation can leave a negative impression on the audience. This may, also lower the self-confidence of the presenter. In an oral presentation, communication, plays a big role. A lot of planning and thinking is required to decide ‘What to say’,, ‘How to say’, ‘How much to say’. Also, the presenter may have to face a barrage of, questions from the audience. A lot of preparation is required; the broad classification, of an oral presentation is as follows:, Nature of an Oral Presentation, 1. Opening: A brief statement can be made on the nature of discussion that will follow., The opening statement should explain the nature of the project, how it came about, and what was attempted., 242 Self Learning Material
Page 243 :
2. Finding/Conclusion: Each conclusion may be stated backed up by findings., 3. Recommendation: Each recommendation must have the support of conclusion., At the end of the presentation, question-answer session should follow from the, audience., 4. Method of presentation: Visuals, if need to be exhibited, can be made use of. The, use of tabular form for statistical information would help the audience., (i), , Report Preparation, , Notes, , What type of presentation is a root question? Is it read from a manuscript, or memorized or delivered ex-tempo. Memorization is not recommended,, since there could be a slip during presentation. Secondly, it produces speakercentric approach. Even reading from the manuscript is not recommended,, because it becomes monotonous, dull and lifeless. The best way to deliver, in ex-tempo is to make main points notes, so that the same can be expanded., Logical sequences should be followed., , Points to Remember in Oral Presentation, 1. Language used must be simple and understandable., 2. Time management should be adhered., 3. Use of charts, graph, etc., will enhance understanding by the audience., 4. Vital data such as figures may be printed and circulated to the audience so that their, ability to comprehend increases, since they can refer to it when the presentation, is going on., 5. The presenter should know his target audience well in advance to prepare tailor, made presentation., 6. The presenter should know the purpose of report such as “Is it for making a, decision”, “Is it for the sake of information”, etc., Written Report, , Types of Written Reports, (A) Reports can be classified based on the time-interval such as:, 1. Daily, 2. Weekly, 3. Monthly, 4. Quarterly, 5. Yearly, (B) Type of reports:, 1. Short report, 2. Long report, Self Learning Material 243
Page 244 :
Research Methodology, , 3. Formal report, 4. Informal report, 5. Government report, 1. Short report: Short reports are produced when the problem is very well defined and, if the scope is limited, e.g., monthly sales report. It will run into about five pages., It consists of report about the progress made with respect to a particular product, in clearly a specified geographical location., , Notes, , 2. Long report: This could be both a technical report as well as non-technical report., This will present the outcome of the research in detail., 3. Technical report: This will include the sources of data, research procedure, sample, design, tools used for gathering data, data analysis methods used, appendix,, conclusion and detailed recommendations with respect to specific findings. If, any journal, paper or periodical is referred, such references must be given for the, benefit of reader., 4. Non-technical report: This report is meant for those who are not technically, qualified, e.g., Chief of the finance department. He may be interested in financial, implications only, such as margins, volumes, etc. He may not be interested in the, methodology., 5. Final report, 6. Example: The report prepared by the marketing manager to be submitted to the, Vice-President (marketing) on quarterly performance, reports on test marketing., 7. Informal report: The report prepared by the supervisor by way of filling the shift, log book, to be used by his colleagues., 8. Government report: These may be prepared by state governments or the central, government on a given issue. Example: Programme announced for rural employment, strategy as a part of five, year plan or report on children’s education, etc., , 5.4 Preparation of Research Report, Ensure your research plan is documented so that you can regularly and efficiently carry, out your research activities. In your plan, record enough information so that someone, outside of the organization can understand what you’re researching and how., For example, consider the following format:, 1. Title Page (name of the organization, or a product/service/programme that is being,, researched; date), 2. Table of Contents, 3. Executive Summary (one-page, concise overview of findings and recommendations), 4. Purpose of the Report (what type of research was conducted, what decisions are, being aided by the findings of the research, who is making the decision, etc.), 244 Self Learning Material
Page 245 :
5. Background about Organization and Product/Service/Programme that is being, researched, (i), , Description/History of Organization, , (ii), , Description of Product/Service/Programme (that is being researched), (a), , Problem Statement (in the case of non–profits, description of the, community need that is being met by the product/service/programme), , (b), , Overall Goal(s) of Product/Service/Programme, , (c), , Outcomes (or client/customer impacts) and Performance Measures, (that can be measured as indicators toward the outcomes), , (iii), , Activities/Technologies of the Product/Service/Programme (general, description of how the product/service/programme is developed and, delivered), , (iv), , Staffing (description of the number of personnel and roles in the organization, that are relevant to developing and delivering the product/service/programme), , Report Preparation, , Notes, , 6. Overall Evaluation Goals (e.g., what questions are being answered by the research), 7. Methodology, (i), , Types of data/information that were collected, , (ii), , How data/information were collected (what instruments were used, etc.), , (iii), , How data/information were analyzed, , (iv), , Limitations of the evaluation (e.g., cautions about findings/conclusions and, how to use the findings/conclusions, etc.), , 8. Interpretations and Conclusions (from analysis of the data/information), 9. Recommendations (regarding the decisions that must be made about the product/, service/programme), 10. Appendices: Content of the appendices depends on the goals of the research report,, e.g.:, , 5.4, , (i), , Instruments used to collect data/information, , (ii), , Data, e.g., in tabular format, etc., , (iii), , Testimonials, comments made by users of the product/service/programme, , (iv), , Case studies of users of the product/service/programme, , (v), , Any related literature, , How to Make Interpretations, , Basic Analysis of “Quantitative” Information, (For information other than commentary, e.g., ratings, rankings, yes’s, no’s, etc.):, 1. Make copies of your data and store the master copy away. Use the copy for making, edits, cutting and pasting, etc., Self Learning Material 245
Page 246 :
Research Methodology, , 2. Tabulate the information, i.e., add up the number of ratings, rankings, yes’s, no’s,, etc., for each question., 3. For ratings and rankings, consider computing a mean, or average, for each question., , Notes, , Basic Analysis of “Qualitative” Information, Basic Analysis of “Qualitative” Information (respondents’ verbal answers in interviews,, focus groups, or written commentary on questionnaires):, 1. Read through all the data., 2. Organize comments into similar categories, e.g., concerns, suggestions, strengths,, weaknesses, similar experiences, program inputs, recommendations, outputs,, outcome indicators, etc., 3. Label the categories or themes, e.g., concerns, suggestions, etc., 4. Attempt to identify patterns, or associations and causal relationships in the themes,, e.g., all people who attended programmes in the evening had similar concerns, most, people came from the same geographic area, most people were in the same salary, range, what processes or events respondents experience during the programme, etc., 5. Keep all commentary for several years after completion in case needed for future, reference., Interpreting Information, 1. Attempt to put the information in perspective, e.g., compare results to what you, expected, promised results; management or programme staff; any common standards, for your products or services; original goals (especially if you’re conducting a, programme evaluation); indications or measures of accomplishing outcomes or, results (especially if you’re conducting an outcomes or performance evaluation);, description of the programme’s experiences, strengths, weaknesses, etc. (especially, if you’re conducting a process evaluation)., 2. Consider recommendations to help employees improve the programme, product or, service; conclusions about programme operations or meeting goals, etc., 3. Record conclusions and recommendations in a report, and associate interpretations, to justify your conclusions or recommendations., Precautions in Interpretations, One should always remember that even if the data are properly collected and analyzed,, wrong interpretation would lead to inaccurate conclusions. It is, therefore, absolutely, essential that the task of interpretation be accomplished with patience in an impartial, manner and also in correct perspective. Researcher must pay attention to the following, points for correct interpretation:, , 246 Self Learning Material
Page 247 :
1. At the outset, researcher must invariably satisfy himself that the data are appropriate,, trustworthy and adequate for drawing inferences, the data reflect good homogeneity;, and that proper analysis has been done through statistical methods., 2. The researcher must remain cautious about the errors that can possibly arise in the, process of interpreting results. Errors can arise due to false generalization and/or due, to wrong interpretation of statistical measures, such as the application of findings, beyond the range of observations, identification of correlation with causation and, the like. Another major pitfall is the tendency to affirm that definite relationships, exist on the basis of confirmation of particular hypotheses. In fact, the positive test, results accepting the hypothesis must be interpreted as “being in accord” with the, hypothesis, rather than as “confirming the validity of the hypothesis”. The researcher, must remain vigilant about all such things so that false generalization may not take, place. He should be well equipped with and must know the correct use of statistical, measures for drawing inferences concerning his study., , Report Preparation, , Notes, , 3. He must always keep in view that the task of interpretation is very much intertwined, with analysis and cannot be distinctly separated. As such he must take the task of, interpretation as a special aspect of analysis and accordingly must take all those, precautions that one usually observes while going through the process of analysis, viz., precautions concerning the reliability of data, computational checks, validation, and comparison of results., 4. He must never lose sight of the fact that his task is not only to make sensitive, observations of relevant occurrences, but also to identify and disengage the factors, that are initially hidden to the eye. This will enable him to do his job of interpretation, on proper lines. Broad generalization should be avoided as most research is not, amenable to it because the coverage may be restricted to a particular time, a, particular area and particular conditions. Such restrictions, if any, must invariably, be specified and the results must be framed within their limits., 5. The researcher must remember that “ideally in the course of a research study, there, should be constant interaction between initial hypothesis, empirical observation, and theoretical conceptions. It is exactly in this area of interaction between, theoretical orientation and empirical observation that opportunities for originality, and creativity lie.” He must pay special attention to this aspect while engaging in, the task of interpretation., , 5.5, , Significance of Report Writing, , Research report is considered a major component of the research study for the research, task remains incomplete till the report has been presented and/or written. As a matter, of fact even the most brilliant hypothesis, highly well designed and conducted research, study, and the most striking generalizations and findings are of little value unless they, Self Learning Material 247
Page 248 :
Research Methodology are effectively communicated to others. The purpose of research is not well served unless, the findings are made known to others. Research results must invariably enter the general, store of knowledge. All this explains the significance of writing research report. There are, people who do not consider writing of report as an integral part of the research process., Notes, But the general opinion is in favour of treating the presentation of research results or, the writing of report as part and parcel of the research project. Writing of report is the, last step in a research study and requires a set of skills somewhat different from those, called for in respect of the earlier stages of research. This task should be accomplished, by the researcher with utmost care; he may seek the assistance and guidance of experts, for the purpose., , 5.6, , Mechanics of Writing a Research Report, , There are very definite and set rules which should be followed in the actual preparation, of the research report or paper. Once the techniques are finally decided, they should be, scrupulously adhered to, and no deviation is permitted. The criteria of format should, be decided as soon as the materials for the research paper have been assembled. The, following points deserve mention so far as the mechanics of writing a report are concerned:, 1. Size and Physical Design: The manuscript should be written on unruled paper, 81/2 × 11in size. If it is to be written by hand, black or blue-black ink should be, used. A margin of at least one and one-half inches should be allowed at the left, hand and of at least half an inch at the right hand of the paper. There should also, be one-inch margins, top and bottom. The paper should be neat and legible. If the, manuscript is to be typed, all typing should be double-spaced on one side of the, page only except for the insertion of the long quotations., 2. Procedure: Various steps in writing the report should be strictly adhered to (All, such steps have already been explained earlier in this unit)., 3. Layout: Keeping in view the objective and nature of the problem, the layout of the, report should be thought of and decided and accordingly adopted. The layout of, the research, as given in present unit, should be taken as a guide for report-writing., 4. Treatment of Quotations: Quotations should be placed in quotation marks and, double spaced, forming an immediate part of the text. But if a quotation is of a, considerable length (more than four or five type written lines) then it should be, single-spaced and indented at least half an inch to the right of the normal text margin., 5. The Footnotes: Regarding footnotes one should keep in view the followings:, (i), , 248 Self Learning Material, , The footnotes serve two purposes viz., the identification of materials used, in quotations in the report and the notice of materials not immediately, necessary to the body of the research text but still of supplemental value. In, other words, footnotes are meant for cross references, citation of authorities, and sources, acknowledgement and elucidation or explanation of a point of
Page 249 :
view. It should always be kept in view that footnote is not an end in itself, nor a means of the display of scholarship. The modern tendency is to make, the minimum use of footnotes for scholarship does not need to be displayed., , Report Preparation, , (ii), , Footnotes are placed at the bottom of the page on which the reference or, quotation which they identify or supplement ends. Footnotes are customarily, separated from the textual material by a space of half an inch and a line about, one and a half inches long., , Notes, , (iii), , Footnotes should be numbered consecutively, usually beginning with, 1 in each chapter separately. The number should be put slightly above, the line, say at the end of a quotation. At the foot of the page, again, the, footnote number should be indented and typed a little above the line. Thus,, consecutive numbers must be used to correlate the reference in the text with, its corresponding note at the bottom of the page, except in case of statistical, tables and other numerical material, where symbols such as the asterisk (*), or the like one may be used to prevent confusion., , (iv), , Footnotes are always typed in single space though they are divided from, one another by double space., , (v), , The first footnote reference to any given work should be complete in its, documentation, giving all the essential facts about the edition used. Such, documentary footnotes follow a general sequence. The common order may, be described as under:, (a), , , , Regarding the single-volume reference:, v , , Author’s name in normal order (and not beginning with the last, name as in a bibliography) followed by a comma;, , v , , Title of work, underlined to indicate italics;, , v , , Place and date of publication;, , v , , Pagination references (The page number)., , Example–John Gassner, Masters of the Drama, New York: Dover Publications,, Inc. 1954, p. 315., (b), , (c), , Regarding multivolumed reference:, v , , Author’s name in the normal order;, , v , , Title of work, underlined to indicate italics;, , v , , Place and date of publication;, , v , , Number of volume;, , v , , Pagination references (The page number)., , For works arranged alphabetically such as encyclopedias and, dictionaries, no pagination reference is usually needed. In such, cases, the order is illustrated as under:, Self Learning Material 249
Page 250 :
Research Methodology, , Example 1–“Salamanca,” Encyclopaedia Britannica, 14th Edition., Example 2–“Mary Wollstonecraft Godwin,” Dictionary of national, biography., , Notes, , But if there should be a detailed reference to a long encyclopedia article,, volume and pagination reference may be found necessary., (d), , Regarding periodicals reference:, v , , Name of the author in normal order;, , v , , Title of article, in quotation marks;, , v , , Name of periodical, underlined to indicate italics;, , v , , Volume number;, , v , , Date of issuance;, , v , , Pagination., , (e), , Regarding anthologies and collections reference: Quotations from, anthologies or collections of literary works must be acknowledged, not only by author, but also by the name of the collector., , (f), , Regarding second-hand quotations reference:, v , , Original author and title;, , v , , “quoted or cited in,”;, , v , , Second author and work., , Example– J.F. Jones, Life in Ploynesia, p. 16, quoted in History of the Pacific, Ocean area, by R.B. Abel, p. 191., (g), , In case of multiple authorship:, If there are more than two authors or editors, in the documentation, the name of only the first given and the multiple authorship is, indicated by “et al.” or “and others”. Subsequent references to the, same work need not be so detailed as stated above. If the work is, cited again without any other work intervening, it may be indicated, as ibid, followed by a comma and the page number. A single page, should be referred to as p., but more than one page be referred to as, pp. If there are several pages referred to at a stretch, the practice is, to use often the page number, for example, pp. 190ff, which means, page number 190 and the following pages; but only for page 190 and, the following page ‘190f’. Roman numerical is generally used to, indicate the number of the volume of a book. Op. cit. (opera citato,, in the work cited) or Loc. cit. (loco citato, in the place cited) are two, of the very convenient abbreviations used in the footnotes. Op. cit., or Loc. cit. after the writer’s name would suggest that the reference, is to work by the writer which has been cited in detail in an earlier, footnote but intervened by some other references., , 250 Self Learning Material
Page 251 :
(h), , Punctuation and abbreviations in footnotes: The first item after the, number in the footnote is the author’s name, given in the normal, signature order. This is followed by a comma. After the comma, the, title of the book is given: the article (such as “A”, “An”, “The” etc.), is omitted and only the first word and proper nouns and adjectives, are capitalized. The title is followed by a comma. Information, concerning the edition is given next. This entry is followed by a, comma. The place of publication is then stated; it may be mentioned, in an abbreviated form, if the place happens to be a famous one such, as Lond. for London, N.Y. for New York, N.D. for New Delhi and, so on. This entry is followed by a comma. Then the name of the, publisher is mentioned and this entry is closed by a comma. It is, followed by the date of publication if the date is given on the title, page. If the date appears in the copyright notice on the reverse side, of the title page or elsewhere in the volume, the comma should be, omitted and the date enclosed in square brackets [c 1978], [1978]., The entry is followed by a comma. Then follow the volume and, page references and are separated by a comma if both are given. A, period closes the complete documentary reference. But one should, remember that the documentation regarding acknowledgements from, magazine articles and periodical literature follow a different form, as stated earlier while explaining the entries in the bibliography., Certain English and Latin abbreviations are quite often used, in bibliographies and footnotes to eliminate tedious repetition., The following is a partial list of the most common abbreviations, frequently used in report-writing (the researcher should learn, to recognise them as well as he should learn to use them):, anon.,, nonymous, ante.,, , before, , art.,, , article, , aug.,, , augmented, , bk.,, , book, , bull.,, , bulletin, , cf.,, , compare, , ch.,, , chapter, , col.,, , column, , þdiss.,, , dissertation, , d.,, , editor, edition, edited., , ed. cit.,, , edition cited, , Report Preparation, , Notes, , Self Learning Material 251
Page 252 :
Research Methodology, , Notes, , e.g.,, , exempli gratia: for example, , eng.,, , enlarged, , et.al.,, , and others, , et seq.,, , et sequens: and the following, , ex.,, , example, , f., ff.,, , and the following, , fig(s).,, , figure(s), , fn.,, , footnote, , ibid., ibidem:, , in the same place (when two or more successive, footnotes refer to the same work, it is not necessary, to repeat complete reference for the second footnote., Ibid. may be used. If different pages are referred to,, pagination must be shown)., , id., idem:, , the same, , ill., illus., or, illust(s)., , illustrated, illustration(s), , Intro., intro.,, , introduction, , l, or ll,, , line(s), , loc. cit.,, , in the place cited; used as op.cit., (when new reference, , loco citato:, , is made to the same pagination as cited in the previous, note), , MS., MSS.,, , Manuscript or Manuscripts, , N.B., nota bene: note well, n.d.,, , no date, , n.p.,, , no place, , no pub.,, , no publisher, , no(s).,, , number(s), , o.p.,, , out of print, , op. cit: in the work cited (If reference has been made to a, work, , 252 Self Learning Material, , opera citato, , and new reference is to be made, ibid., may be used,, if intervening reference has been made to different, works, op.cit. must be used. The name of the author, must precede., , p. or pp.,, , page(s), , passim:, , here and there, , post:, , after
Page 253 :
rev.,, , revised, , tr., trans.,, , translator, translated, translation, , vid or vide:, , see, refer to, , viz.,, , namely, , vol. or vol(s)., volume(s), vs., versus:, , Report Preparation, , Notes, , against, , Use of statistics, charts and graphs: A judicious use of statistics in research reports, is often considered a virtue for it contributes a great deal towards the clarification and, simplification of the material and research results. One may well remember that a good, picture is often worth more than thousand words. Statistics are usually presented in the, form of tables, charts, bars and line-graphs and pictograms. Such presentation should, be self-explanatory and complete in itself. It should be suitable and appropriate looking, to the problem at hand. Finally, statistical presentation should be neat and attractive., The final draft: Revising and rewriting the rough draft of the report should be, done with great care before writing the final draft. For the purpose, the researcher should, put to himself questions like: Are the sentences written in the report clear? Are they, grammatically correct? Do they say what is meant’? Do the various points incorporated, in the report fit together logically? “Having at least one colleague read the report just, before the final revision is extremely helpful. Sentences that seem crystal-clear to the, writer may prove quite confusing to other people; a connection that had seemed selfevident may strike others as a non-sequitur. A friendly critic, by pointing out passages, that seem unclear or illogical, and perhaps suggesting ways of remedying the difficulties,, can be an invaluable aid in achieving the goal of adequate communication., Bibliography: Bibliography should be prepared and appended to the research, report as discussed earlier., Preparation of the index: At the end of the report, an index should invariably, be given, the value of which lies in the fact that it acts as a good guide, to the reader., Index may be prepared both as subject index and as author index. The former gives the, names of the subject-topics or concepts along with the number of pages on which they, have appeared or discussed in the report, whereas the latter gives the similar information, regarding the names of authors. The index should always be arranged alphabetically., Some people prefer to prepare only one index common for names of authors, subjecttopics, concepts and the like ones., , 5.8 How to Write a Bibliography, Bibliography, the last section of the report comes after appendices. Appendices contain, questionnaires and other relevant material of the study. The bibliography contains the, source of every reference used and any other relevant work that has been consulted. It, imparts an authenticity regarding the source of data to the reader. Bibliographies are of, Self Learning Material 253
Page 254 :
Research Methodology different types, viz., bibliography of works cited; this contains only the items referred in, the text. A selected bibliography lists the items which the author thinks are of primary, interest to the reader. An annotated bibliography gives brief description of each item., The method of representing bibliography is explained on the following page., , Notes, , Books, Name of the author, title of the book (underlined), publisher’s detail, year of publishing,, page number., Single Volume Works. Dube, S. C. “India’s Changing Villages”, Routledge and, Kegan Paul Ltd., 1958, p. 76., , Chapter in an Edited Book, Warwick, Donald P., “Comparative Research Methods” in Balmer, Martin and Donald, Warwick (eds) 1983, pp. 315-30., , Periodicals Journal, Dawan Radile (2005), “They Survived Business World” (India), May 98 pp. 29-36., , Newspaper, Articles, Kumar Naresh, “Exploring Divestment” The Economic Times (Bangalore), August 7,, 1999 p. 14., , Website, www.infocom.in.com, For citing Seminar paper, Krishna Murthy, P., “Towards Excellence in Management” (Paper presented at a Seminar, in XYZ College Bangalore, July 2000)., , 1.0, , Reporting Results, , 1. The level and scope of content depends upon to whom the report is intended, e.g.,, to funders/bankers, employees, clients, customers, the public, etc., 2. Be sure, employees have a chance to carefully review and discuss the report,, translate recommendations to action plans, including who is going to do what about, the research results and by when., 3. Funders/bankers will require a report that includes an executive summary, (this is a summary of conclusions and recommendations, not a listing of what, sections of information are in the report – that’s a table of contents); description, of the organization and the programme, product, service, etc., under evaluation;, 254 Self Learning Material
Page 255 :
explanation of the research goals, methods, and analysis procedures; listing of, conclusions and recommendations; and any relevant attachments, e.g., inclusion, of research questionnaires, interview guides, etc. The funder may want the report, to be delivered as a presentation, accompanied by an overview of the report. Or,, the funder may want to review the report alone., , Report Preparation, , Notes, , 4. Be sure while recording the research plans and activities in a research plan which, can be referenced when a similar research effort is needed in the future., , 5.9 Precautions for Writing Research Reports, Research report is a channel of communicating the research findings to the readers of, the report. A good research report is one which does this task efficiently and effectively., As such it must be prepared keeping the following precautions in view:, 1. While determining the length of the report (since research reports vary greatly in, length), one should keep in view the fact that it should be long enough to cover the, subject but short enough to maintain interest. In fact, report-writing should not be, a means to learn more and more about less and less., 2. A research report should not, if this can be avoided, be dull; it should be such as, to sustain reader’s interest., 3. Abstract terminology and technical jargon should be avoided in a research report., The report should be able to convey the matter as simply as possible. This, in other, words, means that report should be written in an objective style in simple language,, avoiding expressions such as “it seems,” “there may be” and the like., 4. Readers are often interested in acquiring a quick knowledge of the main findings, and as such the report must provide a ready availability of the findings. For this, purpose, charts, graphs and the statistical tables may be used for the various results, in the main report in addition to the summary of important findings., 5. The layout of the report should be well thought out and must be appropriate and, in accordance with the objective of the research problem., 6. The reports should be free from grammatical mistakes and must be prepared, strictly in accordance with the techniques of composition of report-writing such, as the use of quotations, footnotes, documentation, proper punctuation and use of, abbreviations in footnotes and the like., 7. The report must present the logical analysis of the subject matter. It must reflect a, structure wherein the different pieces of analysis relating to the research problem, fit well., 8. A research report should show originality and should necessarily be an attempt to, solve some intellectual problem. It must contribute to the solution of a problem, and must add to the store of knowledge., Self Learning Material 255
Page 256 :
Research Methodology, , 9. Towards the end, the report must also state the policy implications relating to the, problem under consideration. It is usually considered desirable if the report makes, a forecast of the probable future of the subject concerned and indicates the kinds, of research still needs to be done in that particular field., , Notes, , 10. Appendices should be enlisted in respect of all the technical data in the report., 11. Bibliography of sources consulted is a must for a good report and must necessarily, be given., 12. Index is also considered an essential part of a good report and as such must be, prepared and appended at the end., 13. Report must be attractive in appearance, neat and clean, whether typed or printed., 14. Calculated confidence limits must be mentioned and the various constraints, experienced in conducting the research study may also be stated in the report., 15. Objective of the study, the nature of the problem, the methods employed and the, analysis techniques adopted must all be clearly stated in the beginning of the report, in the form of introduction., , 5.10, , Effective Report Writing, , An effectively written report is one that has a logical flow of ideas and is cohesive. This, means the report works as a unified whole; for example, it contains links between and, within its sentences, paragraphs and sections, it is easy to follow and it uses language, to maintain the report’s focus and to direct the reader., There are several devices that can improve the effectiveness of your report writing., These devices include macro or whole text devices such as logical structure and logical, flow. They also include more detailed macro devices such as using paragraphs that are, legitimate; clearly referring back to ideas, subjects and objects throughout the text and, using connective words which signal changes and movements in the text to the reader., , 5.11, , Use of Figures, , Use figures such as diagrams, tables, graphs, charts or maps can be a very useful way to, show and emphasise information in your report. They can be used to compile data in an, orderly way or to amplify a point and are a useful tool to help your readers understand, complex or numerous data (Weaver and Weaver, 1977)., Figures essential to the report should be smoothly and correctly integrated and, should be explained and referred to in the main body of the report. A useful way to do, this is to ‘lead in’ the figure by telling the reader what to focus on in the figure and then, ‘lead out’ of the figure perhaps by linking the important point that was illustrated to the, next salient point; for example:, Figures that are supportive rather than essential to your explanation can be placed, in the appendix section so that the continuity of your writing is not broken up (Weaver, 256 Self Learning Material
Page 257 :
and Weaver, 1977). If a figure such as a table of data is essential for understanding but, is very lengthy, you may wish to include an excerpt of the most relevant part of the, figure in the text and the full figure in an appendix., The inclusion of tables and figures does not absolve you from making your report, coherent. Regardless of whether the figures are integrated into the text or are in an, appendix, it is important that you do discuss the information represented in the diagrams,, tables, graphs, charts and maps and not just let them ‘speak for themselves’. A good, rule of thumb is to produce text and figures that can both stand alone: the text should be, readable without figures, and vice versa. In your discussion of the information represented, in the figures you should highlight information which you consider significant, point, out trends or relationships or compare data presented in separate figures; for example,, , Report Preparation, , Notes, , The Keeling plant’s production capacity was reached in May this year. In contrast,, the Hergort plant has not yet reached 75% of its production capacity (see Table)., As can be seen from Fig. below, when the tap handle is, placed in an upward position the tap is closed in contrast,, when the tap handle, or lever, is moved to a downward, position, the tap valve is opened by a pushrod that raises the, normal washer and water flows (see Fig.)., , The tap handle in the upward, The tap handle in the, (closed) position, downward (open) position, By incorporating a ratchet locking system, similar to that used, in an automobile handbrake, the lever can be locked in a number, of positions, provided by graduations in the ratchet, allowing, the user of set the flow rate, similar to a conventional tap., , ‘Lead-in’ sentence showing, what is to be noticed., Include the number(s) of the, figures being discussed., The figure are figures being, discussed are inserted as, closely as possible to the end, of the paragraph in which it, was introduced (i.e. below the, paragraph or on the next page)., The figures should be numbered, and titled., ‘Lead out’ sentences that, conclude the point being made, or link the discussion to the, next point., , Make sure the figure is worthwhile. If the text is crystal clear without the insertion, of a figure there is no point including it, despite how good it may look. If the text does, not make sense without the insertion of the figure, you are expecting the figure to do, your job for you. In fact, the figure is not meant to make your point but to illustrate,, emphasise and supplement it (Weaver & Weaver, 1977: 87)., , Labelling Figures in Your Report, Figures must be clearly labelled so they can be accurately referred to in your written, discussion. Each figure should have a title and a number, for example:, Figure 1: Retention rates of Year 10 students in NSW public schools in 1998–2001., Table 5: Means scores and standard deviations from Experiment 2., Self Learning Material 257
Page 258 :
Research Methodology, , Notes, , Note in the examples above that the number of the figure is presented as a numeral, in the title of the figure. The number of the figure is also presented as a numeral when, the figure is referred to in the text of the report., You may choose to label diagrams, tables and figures as Figures or you may, choose to label diagrams and graphs as Figures and tables as Tables. In the latter case, the numbering used for figures and tables would be separate. The numbering of figures, should proceed chronologically (1, 2, 3, etc.) or may relate to chapter or section numbers, (i.e. 1.1, 1.2, etc., 2.1, 2.2, etc., 3.1, 3.2, etc.). As long as the numbering system you, choose is logical and you use it consistently, variations should be acceptable., The title of your figure should include enough information to enable the figure, to be self-explanatory; for example, the title Figure 1: Retention rates would be, inadequate. This title could be improved by adding enough information so its content, is self-explanatory; for example,, Figure Retention rates of Year 10 students in NSW public schools in 1998-2001, In fact, from the figure title and the axis labels of a graph/table the reader should, be able to determine the question being asked, get a good idea of how the study was, done, and be able to interpret the figure without reference to the text., In the science related content in particular, it is expected that your figure legends, will be quite detailed and very precise. This is probably a reaction to many journal readers, only having time to scan an article instead of reading it in its entirety; for example, refer, to the figure below for a good example of a figure title and legend., Meaan number of colonies per plate, , 120, 100, 80, , EC1, EC2, EC3, , 60, , EC4, , 40, 20, 0, , None, , Streptomycin Chloramphenicol, , Chlor. + Strep, , Media content, , Fig. 5.1, Effect of various antibiotic media on growth of four strains of E. coli (EC1, EC2,, EC3 and EC4) isolated from nappies of babies at a Casey hospital. Strains were grown on, media containing no antibiotics (none), 5mg/ml streptomycin, 5mg/ml chloramphenicol, 258 Self Learning Material
Page 259 :
or 5mg/ml streptomycin and 5mg/ml chloramphenicol (chlor. + strep.). Bacterial growth, was scored as number of colonies present after three days of growth at 37°C. Data is, expressed as the mean number of colonies on each medium (n = 10). Vertical bars show, standard errors of the mean., Figures which are replicated from someone else’s work should be acknowledged;for, example,, , Report Preparation, , Notes, , Figure: An example of a typical novice problem categorisation (from Chi,, Feltovich and Glaser, 1981, p. 264)., How you reference the figure will depend on the referencing style you have used, throughout your report but you should include the page number the figure was taken from., If your report includes a large number of figures and tables it is advisable to, create a new list/s after the table of contents called the ‘table of figures’ and the ‘table, of tables’ (if required). In the ‘table of figures” and the ‘table of tables’ list the titles of, your figures and the number of the page they can be located upon., , 5.12 Use of Tables in Report, Use tables to show quantitative features of data and close analysis. Tables should be, presented so that patterns and exceptions in the data are highlighted; for example, if, you intend to discuss two means, place them close enough together to compare visually., Also, if you want to show the relationship between two or more series of numbers,, arrange them in columns rather than rows because reading down columns is quicker, than reading across rows and patterns emerge more quickly., A poor example of a table in a report, Table 5.1: Performance Success Index Table, Attribute, , P.S.I., , A, , A, , A, , Fund Corr., , 10, , –2, , –2, , –1, , Perf. Quar., , 8, , – 0.8, , – 0.8, , –4, , Prod. Cost, , 10, , –2, , –1, , – 10, , O & M Costs, , 8, , 0, , 0, , Ergonomic, , 10, , –3, , –3, , Physiological, , 8, , 0, , 0, , Psychological, , 5, , 0, , 0, , Legal, , 5, , –1, , –1, , Total, , 64, , – 8.8, , The title of table does not follow, standard format, it should not be, bold., , – 10 What each attribute consists of is, unclear., –1, The acronym “PSI’ could be, – 0.8, mistaken for the scientific term, – 1 ‘pounds per square inch’, so, should not have been used., 0, , – 7.8 – 27.8, , A better example of a table in a report, Self Learning Material 259
Page 260 :
Research Methodology, Performance, attribute, Correctness, , Notes, , Predicted, Performance, , Table 5.2: Performance Success Index, Success Proposal Proposal Proposal, index, A, B, C, Title follows ‘standard, 10, –2, –2, –1, format’, 8, – 0.8, – 0.8, –4, , Overall &, Maint. Costs, , 10, , –2, , –1, , – 10, , Ergonomic, Design, , 8, , –0, , 0, , – 10, , Physiological, , 10, , –3, , –3, , –1, , Physiological, , 8, , 0, , 0, , – 0.8, , Psychological, , 5, , 0, , 0, , –1, , Legal issues, , 5, , –1, , –1, , 0, , Total, , 10, , – 8.8, , – 7.8, , – 27.8, , 5.13, , Labelling with the, table is now more, meaningful, The addition of a, border around the table, makes it more visually, pleasing, Important information, such as the totals are, highlighted through, colour and bolding., , Use of Graphs in Report, , Use graphs to show qualitative features and gross differences in data. Graphs can show, a change in one function in relation to a change in another and are usually simpler,, quicker and easier to digest., , A Poor Example of a Graph in a Report, This figure lacks;, standard deviations; and axis/labels. It, also has insufficient information in the, legend as it does not stipulate which, bacteria or what sort of agar plates., , 100, 80, 60, , Control, CHL, STR, CH/STR, , 40, 20, 0, , EC1, , EC2, , EC3, , EC4, , Fig. 5.2, Fig. 5.2 Shows the average number of colonies of the four different strains of, bacteria which had grown on the different agar plates after the three day incubation., 260 Self Learning Material
Page 261 :
Report Preparation, , Meaan number of colonies per plate, , A better example of a graph in a report, This graph contains standard error bars, showing the standard deviations, for each column of data. Each of the axes of the graph are provided, with an explanatory label. The title is self-sufficient: it contains detailed, information about the bacteria and its sources, the location of the, experiment and content of the bacteria and its source, the location of the, experiment and content of the agar plates. This information clarifies the, , 120, 100, , Notes, , 80, 60, EC1, EC2, EC3, EC4, , 40, 20, 0, , None, None, , Streptomycin Chloramphenicol, , Chlor. + Strep, , Figure 5.3: Effect of various antibiotic media on growth of four strains of E.coli, (EC1.EC2, EC3 and EC4) isolated from nappies of babies at Casey hospital., Strains were grown on media containing either no antibiotics (none), 5mg/ml, streptomycin, 5mg/ml chloramphenicol or 5 mg/ml streptomycin and 5 mg/, ml chloramphenicol (chlor + strep). Bacterial growth was scored as number of, colonies present after three days of growth at 37°C. Data is expressed as the, mean number of colonies on each medium (n=10). Vertical bars show standard, errors of the mean., , 5.14 Organizing and Numbering, There is no one ideal strategy that can be used to organise the information of your report, as this will vary and be dependent upon the information you are presenting. A logical, and clear organisational strategy, however, is a key ingredient to a good report. It is, important to include a consistent numbering system for the headings and subheadings,, or to use the layout (indenting) of the report’s headings to indicate the sections and, sub-sections; for example, the following heading and subheadings have been taken the, report of a university library., 1. Client Service Satisfaction, 1.1 Client Feedback System, 1.1.1 Inter-library Loans, 1.1.2 Shelf Tidiness, 1.1.3 Three Day Loans, 1.2 Materials Availability Survey, 1.3 Online help service, , Self Learning Material 261
Page 262 :
Research Methodology, , 2. INFORMATION TECHNOLOGY, 2.1 The library system, 2.1.1 Use, 2.1.2 Maintenance, 2.1.3 Future directions, 2.2 Databases, 2.1.1 Use, 2.1.2 Access, 2.1.3 Expansion, , Notes, , Below is an extended example of a report structure that looks at how you might, arrange the hierarchy of headings and subheadings., The first order numbering identifies the main sections:, 1. Heading First Main Section, 2. Heading Second Main Section, 3. Heading Third Main Section, A second order system of numbering is used for the subheadings or subsections that, come under each of the main headings:, 1. Heading First Main Section, 1.1 Second order heading, 1.2 Second order heading, 1.3 Second order heading, 2. HEADING SECOND MAIN SECTION, 2.1 Second order heading, 2.2 Second order heading, 2.3 Second order heading, The sub sections may then require further sub dividing into a third order system, of numbering:, 1. Heading First Main Section, 1.1 Second order heading (subheading), 1.2 Second order heading (subheading), 1.2.1 Third order heading (sub-subheading), 1.2.2 Third order heading (sub-subheading), 2. HEADING SECOND MAIN SECTION, 2.1 Second order heading (subheading), 2.1.1 Third order heading (sub-subheading), 262 Self Learning Material
Page 263 :
3. Heading Third Main Section, , Report Preparation, , 3.1 Second order heading (subheading), 3.1.1 Second order heading (subheading), 3.2 Second order heading (subheading), , Notes, , 3.2.1 Third order heading (sub-subheading), 3.2.2 Third order heading (sub-subheading), (Adapted from Dwyer, J. (1991) The Business Communication Handbook (2nd Ed.)., Sydney: Managing Business Communication.), In general, your table of contents will only show the first two levels of headings., The headings should appear in the table of contents exactly the same way as they appear, in the text of your report in terms of numbering, capitalisation, underlining etc. (Weaver, & Weaver, 1977)., , 5.15 Use of Headings in Report, Headings should be clearly, logically and accurately labelled since they reveal the, organisation of the report and permit quick reference to specific information. They also, make the report easy to read., Headings should be specific and descriptive NOT vague and general (Weaver, & Weaver, 1977). Sometimes a main heading will be general but the specificity is, developed through subheadings. Given the need for specificity, headings would tend to, be more like an abbreviated sentence rather than a single word. A good rule of thumb, is that the heading should be “long enough to be an inclusive label but short enough, to be immediately clear” (Weaver & Weaver, 1977: 84). You should also try to make, headings grammatically and logically consistent; for example, if your main heading was, “Types of Schemas” and your subheadings under this section were:, zz Schemas, , for scenes, , zz Schemas, , for events, , zz Schemas, , for stories, , zz Problems, , and their schemas, , It would be much better to change the final subheading to “Schemas for problems”, so that consistency in your headings is maintained., Also avoid using headings that are catchy rather than informative; for example, the, following subheadings, although catchy and cute, detract from the serious informative, intent of the following report., 4. Key products and services of the McDonald’s corporation, The following outline of McDonald’s key products and services will thoroughly, examine all aspects of consumer buying behaviour ….., Self Learning Material 263
Page 264 :
Research Methodology, , Notes, , 4.1 The Big Mac: two all beef patties, special sauce, lettuce, cheese, pickles, and onions on a sesame seed bun!, The Big Mac hamburger brand was introduced to the McDonalds’s product range, in 1968 and has worldwide recognition. The longevity, popularity and recognisability, of this product impact on consumer buying behaviour in several ways….., 4.2 McFlurry: just like a snowstorm in your mouth!, The McFlurry is a relatively new item to the McDonald’s product range and as, such it is relevant to analyse several different aspects of consumer buying behaviour, such as ….., , 5.16, , Reference Lists and Referencing, , It is essential to include a reference list or bibliography of the reference material you, consulted during your research for the report. A bibliography is a list of all the reference, material you consulted during your research for the report while a reference list is a list, of all the references cited in the text of your report, listed in alphabetical order at the end, of the report. Each reference in the reference list needs to contain all the bibliographic, information from a source., Throughout the text of your report, you will also need to provide references when, you have included an idea in your report which is not your own original idea. You, don’t need to reference an idea, however, if it is common knowledge (i.e., enzymes, are proteins) or if it has been established by you in your experiment (i.e., in scientific, reports reporting on an experiment). A reference is the bracketed or footnoted piece of, information within the text of your writing that provides an acknowledgment that you, are using someone else’s ideas. There are several systems of referencing such as the, Harvard or author-date system, footnotes or endnotes. Different faculties, departments, and even lecturers will generally have preferences about how you should reference and, you should seek these out before submitting your assignment., , 5.17, , Use of Appendices, , The information that is not essential to explain your findings, but that supports your, analysis (especially repetitive or lengthy information), validates your conclusions or, pursues a related point should be placed in an appendix. Sometimes excerpts from, this supporting information (i.e., part of the data set) will be placed in the body of the, report but the complete set of information (i.e., all of the data set) will be included in, the appendix. Examples of information that could be included in an appendix include, figures/tables/charts/graphs of results, statistics, questionnaires, transcripts of interviews,, pictures, lengthy derivations of equations, maps, drawings, letters, specification or data, sheets, computer program information., 264 Self Learning Material
Page 265 :
There is no limit to what can be placed in the appendix providing it is relevant, and reference is made to it in the report. The appendix is not a catch net for all the, semi-interesting or related information you have gathered through your research for, your report: The information included in the appendix must bear directly relate to the, research problem or the report’s purpose. It must be a useful tool for the reader (Weaver, & Weaver, 1977)., , Report Preparation, , Notes, , Each separate appendix should be lettered (Appendix A, Appendix B, Appendix, B1, Appendix B2, Appendix C, etc.). The order they are presented in is dictated by the, order they are mentioned in the text of the report. It is essential to refer to each appendix, within the text of the report., , 5.18 Editing, The final stage in the process of writing a report is editing and this stage is a significant, one. Thorough editing helps to identify:, zz spelling, , mistakes;, , zz awkward, , grammar;, , zz breakdowns, , in the logic of the report’s organisation or conclusion;, , zz if, , you have really fulfilled the requirements of the report and answered all, parts of the question., , Ideally, you will have ironed out any major problems in the redrafting stage, of writing, and make sure that you have answered the question or the report task;, however, thorough editing will allow you to make the minor adjustments or changes to, expression that can greatly improve the flow of your report, or make your ideas clearer., Attention to content as well as surface errors in the editing stage is also an integral part, of editing your work, just as editing is an integral part of the report writing process., A good editing plan of attack is to check your report thoroughly for a particular aspect,, then check thoroughly for another aspect. This means in your haste to complete your, assignment, you won’t neglect editing for different features! An editing checklist can be, a useful tool to help you learn to edit your report and check it is as complete as possible., , Editing Checklist, Use this editing checklist on your final report to ensure that it has been written in an, appropriate style and is as complete as possible., 1. Have I checked the report follows an appropriate structure?, 2. Have I ensured the headings and subheadings accurately reflect the content of, each section?, 3. Have I ensured each paragraph contains a topic sentence?, 4. Have I used paragraphs that aid the flow and analysis of the report’s findings?, 5. Have I structured the sections of the report logically, Self Learning Material 265
Page 266 :
Research Methodology, , 6. Have I used language/expression in the report that is:, , Notes, , (i), , appropriate to the report’s purpose?, , (ii), , clear and easily understood?, , (iii), , concise?, , (iv), , non-sexist, non-racist and inclusive?, , (v), , suited to the needs of the reader?, , 7. Have I made the report’s purpose clear?, 8. Have I fulfilled the terms of reference?, 9. Have I written an introduction that:, (i), , explains the report’s purpose?, , (ii), , defines the problem?, , (iii), , guides the reader into the centre section of the report?, , 10. Have I written a body section that:, (i), , has headings and perhaps subheadings?, , (ii), , presents factual and objective information?, , (iii), , analyses the findings?, , 11. Have I written a conclusion that:, (i), , draws the ideas together/, , (ii), , summarises the content and findings?, , 12. Have I prepared recommendations that:, (i), , offer solutions to any problems in the body?, , (ii), , relate to the terms of reference?, , (iii), , are concrete, specific and action oriented?, , (iv), , are acceptable to the reader and possible to implement?, , 13. Have I included appendices that are:, (i), , relevant to the report?, , (ii), , clearly labelled?, , (iii), , necessary?, , 14. Have I referenced appropriately in the text of the report?, 15. Have I included a complete reference list?, (This checklist has been adapted from Dwyer, J. (1991) The Business Communication, Handbook (2nd Ed.). Sydney: Managing Business Communication), , 5.19, , Giving Effective to Report Presentation, , Congratulations! You or your team has just completed its crowning achievement: a, book-length report on just about every phase of your unit’s operations. And you’ve been, 266 Self Learning Material
Page 267 :
tapped to deliver the report to a senior managers. As the panic builds, you ask, “Why, me? And how on earth can I possibly take so many pages of mind-numbing data and, somehow transform it all into a clear, compelling, oral presentation?”, You might start by looking at the bright side: at least you won’t have to research, your topic. Your task instead is to whittle that mound of material down to size., , Report Preparation, , Notes, , The best way to start that process is to go first to the end of your report. That’s, where your conclusions and recommendations are to be found—and where you’re, likely to find the most salient parts of your report. Work to pare down the report’s most, essential findings. Keep these to as few points as possible., You should now be ready to build the presentation that will lead you to the conclusion, you’ve already established. That means a return to some fundamentals., , Your Objective, Start by being clear about your goals. Was your report designed primarily to pass, along information-perhaps to bring your audience up-to-date or make them aware of, some business issues? Or was it intended as a call to action? What specific response, do you want from your audience? The answers to those questions will help shape your, presentation. Write down your objective. Make it as clear and concise as you can. Keep, it to a few sentences, at most., , Your Audience, Know your audience thoroughly. Check for anything that can affect how they’re likely, to respond. Find out also what they may be expecting from your report. You’ll have, to address in your presentation whatever expectations or preconceived notions your, audience may have., , Your Road Map, Your best bet is to begin by mapping out the logic underlying the presentation, especially, when dealing with extensive and detailed material. Think of this as your road map. It’ll, help you stay focused on the key elements of your report—the main ideas and messages,, the conclusions, and recommendations. List those points from your report that best support, your key messages. You don’t want to get bogged down in more detail than you’ll need, in your presentation, so be ruthless in cutting out what you don’t need. Remember: you, are not presenting the report; you’re creating a presentation based on the report., , Structure Your Talk, When you’re dealing with a lengthy report that later will become an oral presentation,, it helps to break the material into several distinct parts, based on the structure you’ve, defined in your road map. That way, you can address each main idea as an entity, before, moving on to the next idea. That’ll help your listeners better comprehend and remember, Self Learning Material 267
Page 268 :
Research Methodology each key idea. Pay attention here to transitions; these should provide a natural link from, one idea or section to another. Your transitions can also serve both as a summary of each, section and a glimpse of what’s coming next. With a well-thought-out outline, building, the body of your presentation should not pose a great challenge. You should now be, Notes, able to move on logically, step-by-step, to your conclusion., , Create a Strong Opener, It’s essential that you begin any presentation with a strong opener. It’s even more, essential when your audience thinks it’s about to sit through what could be a long, tedious, exposition. You can quickly dispel any such notion with an opener that immediately, grabs everyone’s attention. So plan your opening comments carefully. Find something, in the report—a statement, a claim, a conclusion—that’s likely to have a particular, impact on this audience. That may require no more than going straight to the report’s, key conclusion, and stating it as concisely as you can. You may want to think of an, elevator speech. Imagine you’ve got 10 seconds to make your pitch. What would you, say? Once you’ve got the opener down cold, you can move on smoothly to the body, of your presentation., , Keep those Visuals Lean and Mean, Chances are your report contains lots of detailed data. Be on the alert to include only, the most essential data in your visuals. As you create your visuals, keep in mind the, fundamental rules. Use only at-a-glance visuals that support your key messages. As, much as possible, avoid visuals crowded with lots of data, charts, and graphs that add, nothing of real value. Here again, you’ll need to be somewhat ruthless in cutting out, all but the most essential material., , ome more Tips, zz Be, , clear about the time allotted for your presentation., , zz At, , the end of your presentation, summarize clearly and emphatically the key, conclusions and recommendations of your report., , zz Be, , prepared for questions. Will you be addressing questions as they come up, or will questions be held for a Q&A period at the end?, , zz Have back-up material in reserve in case you’re questioned or challenged about, , parts of the report you did not include in your presentation., zz Have, , handouts ready to pass around after your presentation. You may decide, to hand out the entire report or just portions of it, as appropriate., , zz Rehearse, , in the room and with the equipment you’ll be using., , zz Remember,, , your report was compiled as a report. Your job now is to create a, successful presentation. That means you’ll need everything in the presenter’s, toolkit, including practicing your non-verbal communication skills as well—like, maintaining eye focus and using your voice and gestures to good effect., , 268 Self Learning Material
Page 269 :
5.20 Summary, The most important aspect to be kept in mind while developing research report is the, communication with the audience. Report should be able to draw the interest of the, readers. Therefore, report should be reader centric. Other aspects to be considered while, writing report are accuracy and clarity., , Report Preparation, , Notes, , The points to be remembered while doing oral presentation are language used, time, management, use of graph, purpose of the report, etc. Visuals used must be understandable, to the audience. The presenter must make sure that presentation is completed within the, time allotted. Sometime should be set apart for questions and answers., Written report may be classified based on whether the report is a short report or a, long report. It can also be classified based on technical report or non-technical report., Written report should contain title page, contents, executive summary, body conclusions,, appendix and the last part is bibliography., These are some general things you should know before you start writing. A key, thing to keep in mind right through your report writing process is that a report is written, to be read, by someone else. This is the central goal of report-writing. A report which, is written for the sake of being written has very little value. Take a top-down approach, to writing the report (also applies to problem solving in general). This can proceed in, roughly three stages of continual refinement of details., zz First, zz Then, , write the section-level outline,, the subsection-level outline, and, , zz Then, , a paragraph-level outline. The paragraph-level outline would more-orless be like a presentation with bulleted points. It incorporates the flow of, ideas, , No report is perfect, and definitely not on the first version. Well written reports, are those which have gone through multiple rounds of refinement. This refinement may, be through self-reading and critical analysis, or more effectively through peer-feedback, (or feedback from advisor/instructor)., Here are some things to remember:, zz Start, , early; don’t wait for the completion of your work in its entirety before, starting to write., , zz Each, , round of feedback takes about a week at least. And hence it is good to, have a rough version at least a month in advance. Given that you may have, run/rerun experiments/simulations (for design projects) after the first round of, feedback– for a good quality report, it is good to have a rough version at least, 2 months in advance., , zz Feedback should go through the following stages ideally: (a) you read it yourself, , fully once and revise it, (b) have your peers review it and give constructive, feedback, and then (c) have your advisor/instructor read it., Self Learning Material 269
Page 270 :
Research Methodology, , Glossary, , 5.21, , zz Oral, , report: This type of reporting is required, when the researchers are asked, to make an oral presentation., , Notes, , zz Informal, , report: The report prepared by the supervisor by way of filling the, shift log book, to be used by his colleagues., , zz Appendix:, , Appendices contain questionnaires and other relevant materials of, , the study., zz Bibliography:, , The bibliography contains the source of every reference used, and any other relevant work that has been consulted., , zz Effective, , written report: An effectively written report is one that has a logical, flow of ideas and is cohesive., , zz, , : A bibliography is a list of all the reference material you consulted, during your research for the report., , zz Reference, , list: It is a list of all the references cited in the text of your, , report., , Review Questions, , 5.22, , 1. What is an Oral report?, 2. Write short notes on:, (i), , Short report, , (ii), , bibliography, , (iii), , Technical report:, , 3. What is the criterion for an oral report? Explain., 4. What is meant by “consider the audience” when writing a research report., 5. Why are the visual aids used in oral presentation?, 6. What are the various criteria used for classification of written report?, 7. What are the essential content of the following parts of research report?, (i), , Table of contents, , (ii), , Title page, , (iii), , Executive summary, , (iv), , Introduction, , (v), , Conclusion, , (vi), , Appendix, , 8. What are the essential content of the following parts of research report?, , 270 Self Learning Material, , (i), , Table of contents, , (ii), , Title page
Page 271 :
(iii), , Executive summary, , (iv), , Introduction, , (v), , Conclusion, , (vi), , Appendix, , Report Preparation, , Notes, , 9. Oral presentation requires the researcher to be good public speaker explain., 10. What are the pitfalls to avoid in report writing?, 11. How to make analysis of qualitative and quantitative information?, 12. How to write bibliography for research books?, 13. Define the following:, (i), , appendix, , (ii), , bibliography, , 14. List any two tips of effective report writing., 15. Discuss the basics of effective report writing., 16. Describe effective use of figures, tables and graphs in report., 17. Explain in detail how to edit a report., 18. Write an essay on “effective report presentation skills”., , 5.23, , Further Readings, , 1. C.R. Kothari, Research Methodology, Willey International Ltd., New Delhi, 2. William J. Goode and Paul K. Hatt, Methods in Social Research, McGraw Hill,, New Delhi, 3. C.A. Moser and G. Kalton, Survey Methods in Social Investigation, 4. P.L. Bhandar Kar and T.S. Wilkinson, Methodology and Techniques of Social, Research, Himalaya Publishing House, Delhi, 5. V.P. Michael, Research Methodology in Management, Himalaya Publishing House,, Delhi, 6. S.R. Bajpai, Methods of Social Survey and Research, Kitab Ghar, Kanpur, 7. M.H. Gopal, An Introduction to Research Procedure in Social Sciences, Asian, Publishing House, Bombay, , Self Learning Material 271
 Learn better on this topic
Learn better on this topic